看图理解过拟合与欠拟合
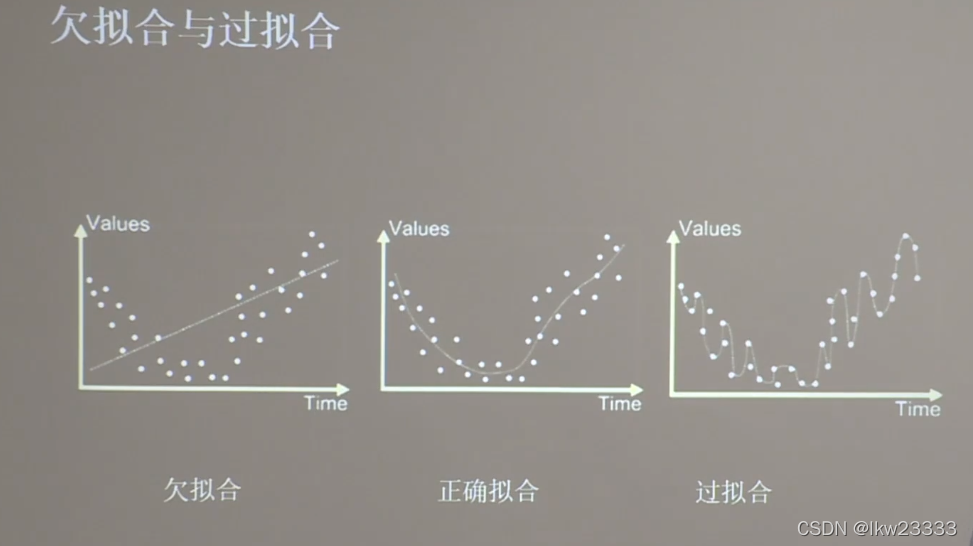
欠拟合解决方法
过拟合解决方法
案例
import tensorflow as tf
from matplotlib import pyplot as plt
import numpy as np
import pandas as pd
###正则化缓解过拟合
# 正则化在损失函数中引入模型复杂度指标,利用给W加权值,弱化训练数据的噪声(一般不正则化b)
# 正则化的选择
# L1正则化大概率会使很多参数变为0,因此该方法可通过稀疏参数,即加少参数的数量,降低复杂度
# L2正则化会使参数很接近0但不为0,因此该方法可通过减小参数值的大小降低复杂度
###读入数据
df = pd.read_csv("dot.csv")
x_data = np.array(df[['x1', 'x2']])
y_data = np.array(df['y_c'])
##-1的意思是行数自动生成
x_train = np.vstack(x_data).reshape(-1, 2)
y_train = np.vstack(y_data).reshape(-1, 1)
Y_c = [['red' if y else 'blue'] for y in y_train]
##转换数据类型。不然后面矩阵相乘会报错
x_train





 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 10万+
10万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









