




 这篇博客介绍了如何使用PyTorch实现逻辑斯蒂回归,将其应用于分类任务。内容包括模型的变化(引入sigmoid激活函数),损失函数的调整(采用BCELoss或交叉熵损失),以及训练过程的步骤。通过实例展示了模型的搭建、损失函数和优化器的设置,以及训练循环。最后,输出了训练后的模型参数和预测结果。
这篇博客介绍了如何使用PyTorch实现逻辑斯蒂回归,将其应用于分类任务。内容包括模型的变化(引入sigmoid激活函数),损失函数的调整(采用BCELoss或交叉熵损失),以及训练过程的步骤。通过实例展示了模型的搭建、损失函数和优化器的设置,以及训练循环。最后,输出了训练后的模型参数和预测结果。
b站链接:https://www.bilibili.com/video/BV1Y7411d7Ys?p=6
Logistic Regression(逻辑斯蒂回归) 是一个用于分类的模型,并不是回归模型
对于预测值y,在分类问题中此时就是一个集合,例如y∈{0,1,2,3,…},我们所要做的就是,得到y对应每个元素的概率,取概率最大的那个元素就是y的预测值,也就分类完成了。
用pytorch深度学习还是以下四个步骤:
- 准备数据集(用dataloader和dataset)
- 设计模型(设计 计算图)
- 构建损失函数和优化器(也就是loss函数和optimizer)
- 开始循环训练(前馈算损失,反馈算梯度,更新权重)
1. 模型变化
之前的线性模型,我们得到的y_pre(预测值)是一个具体的值,但现在我们要的是一个属于0~1之间的概率,所以我们要把数据集映射到0-1之间,这样就引出了sigmoid函数((激活函数(非线性变换),常见的还有ReLU, softmax等)
把y_pre当作下面函数的输入即可
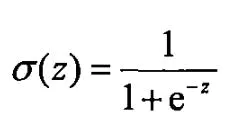
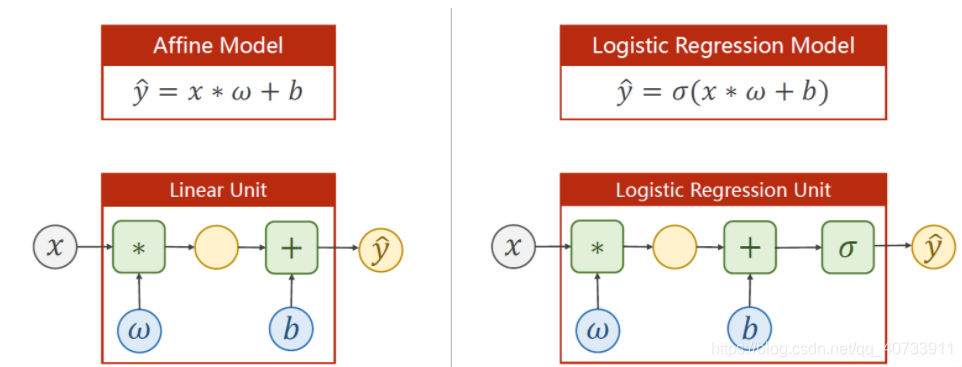
2. 损失函数变化
线性模型的loss=(y_pre-y)^2
logistic的loss是下面这个:
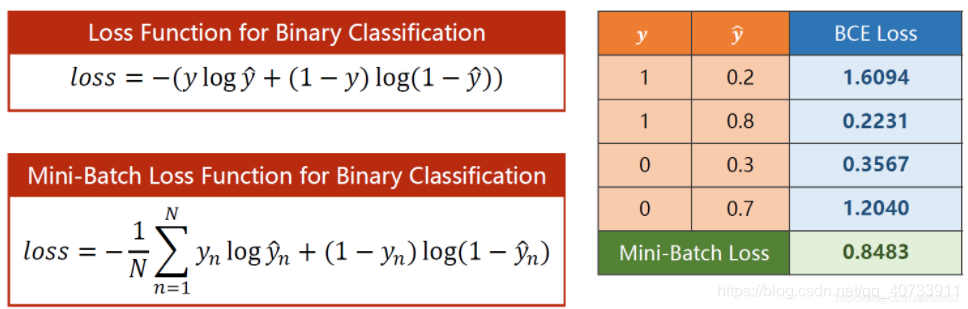
现在要计算的就是两个分布之间的差异,这里是二分类,所以又称为BCE loss
可以用cross-entropy交叉熵
代码:
import torch
# import torch.nn.functional as F
# prepare dataset
#这里就是用二分类的数据了
x_data = torch.Tensor([[1.0], [2.0], [3.0]])
y_data = torch.Tensor([[0], [0], [1]])
# design model using class
class LogisticRegressionModel(torch.nn.Module):
def __init__(self):
super(LogisticRegressionModel, self).__init__()
self.linear = torch.nn.Linear(1, 1)
def forward(self, x):
# 和linear就差了一个sigmoid函数
y_pred = torch.sigmoid(self.linear(x))
# warnings.warn("nn.functional.sigmoid is deprecated. Use torch.sigmoid instead.")
return y_pred
model = LogisticRegressionModel()
# construct loss and optimizer
# 默认情况下,loss会基于element平均,如果size_average=False的话,loss会被累加。
criterion = torch.nn.BCELoss(reduction='sum') # 注意区分线性回归,nn.MSELoss
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
# BCELoss和CE交叉熵的区别
# training cycle forward, backward, update
for epoch in range(1000):
y_pred = model(x_data)
loss = criterion(y_pred, y_data)
print(epoch, loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
print('w = ', model.linear.weight.item())
print('b = ', model.linear.bias.item())
x_test = torch.Tensor([[4.0]])
y_test = model(x_test)
print('y_pred = ', y_test.data)


















 788
788

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









