







已失效。原始代码可以在这里找到哦
本人为了学习该代码,对源代码做了一点修改,可能有错误。
如有侵权,请联系作者删除。
文章目录
requirements.txt
Keras>=2.1.2
numpy>=1.13.3
opencv-python>=3.4.0.12
scipy>=0.19.1
six>=1.11.0
tensorflow>=1.3.0
tifffile>=0.12.1
readme
# DR-CNN
This example implements the paper [Diverse Region-based CNN for Hyperspectral Image Classification](https://ieeexplore.ieee.org/document/8304691/)
Evaluated on the dataset of Inddian Pines, Salinas and Pavia.
## Prerequisites
- System *Ubuntu 14.04 or upper*
- Python 2.7 or 3.6
- Packages
``
pip install -r requirements.txt
``
## How to run the code:
**Please modify 'save_path','PATH','NUM_CLASS','mdata_name','dataset' in file 'consruct_multi_mat.py', and 'mask_train' is the name of train_label
python construct_multi_mat.py --train_label_name mask_train --ksize 11
结果存在“F:\DRCNN\data\save_results”中
**Please modify 'PATH','TEST_PATH','NUM_CLASS','HEIGHT','WIDTH','NUM_CHN' in file 'data_util.py'
python main.py
## Detail Information for Each Function-------------------------------------------------------------------------------------------------------------##
1.the main function of file "consruct_multi_mat.py", data preprocessing:
1) generate training data with shape 11*11*d,7*11*d,7*11*d,11*7*d,11*7*d,3*3*d (d is the dimension of Hyperspectral data)
training data (named train_data_H) including all the training patches for pixels provided with concrete label in mask_train
train_data_H:'data',
'XR',
'XL',
'XU',
'XB',
'XC',
'label'
2) generate test data with shape 11*11*d,7*11*d,7*11*d,11*7*d,11*7*d,3*3*d (d is the dimension of Hyperspectral data)
test data (named test_data_Hi) including all the test patches for pixels provided with concrete label i in mask_test_patchi
test_data_Hi:'hsi',
'XR',
'XL',
'XU',
'XB',
'XC',
'label'
test_data_Hi, i depends on different class in mask_test
****When use aforementioned file 'consruct_multi_mat.py',change 'save_path','PATH','NUM_CLASS','mdata_name','dataset' in file 'consruct_multi_mat.py' while use your own data for simulation
2. HSI_multi_SPA.py:
1) --mode 0 is for training the model(train_KEY,test_KEY,ksize1,ksize2)
2) --mode 1 is for testing the model(train_KEY,test_KEY,ksize1,ksize2)
For saving memory, all the test procedures are implemented class by class,each test operation is carried out based on 'test_data_Hi' dataset.
the test result will be obtained by combining sub-results of per class.
****When use aforementioned file 'HSI_multi_SPA.py',change 'PATH','TEST_PATH','NUM_CLASS','HEIGHT','WIDTH','NUM_CHN' in file 'data_util.py'
3. HSI_multiSPA_union.py:
1) --mode 0 is for training the model
relying on train_data_H, which is generated by consruct_multi_mat.py/consruct_square_mat.py
2) --mode 1 is for testing the model
relying on test_data_Hi, which is generated by consruct_multi_mat.py/consruct_square_mat.py
For saving memory, all the test procedures are implemented class by class,each test operation is carried out based on 'test_data_Hi' dataset.
the test result will be obtained by combining sub-results of per class.
****When use aforementioned file 'HSI_multiSPA_union.py',change 'PATH','TEST_PATH','NUM_CLASS','HEIGHT','WIDTH','NUM_CHN' in file 'data_util.py'
## Detail Information for Each Function------------------------------------------------------------------------------------------------------------------------------------##
1. generate_train_test_gt.py
#为后续构建训练集patchs/测试集patchs做准备,对gt影像进行重新赋值。
from scipy.io import loadmat,savemat
import numpy as np
# 最终得到1张‘mask_train.mat’,每类随机选择40个样本。中心像元标签都加上9,其邻域标签设为0,其他标签不变。
def generate_train_gt(train_samples):
train_test_gt=loadmat("F:\HSI_data_sets\PU\PaviaU_gt.mat")['paviaU_gt']
N=9
np.random.seed(1)
for k in range(1,N+1):
indices=np.argwhere(train_test_gt==k)
n=np.sum(train_test_gt==k)
rndIDX=np.random.permutation(n)
s=int(train_samples)
train_indices=indices[rndIDX[:s]]
for i,j in train_indices:
train_test_gt[i-2:i+2+1][j-2:j+2+1]=0#将patch邻域像元的标签设为0
train_test_gt[i][j]=N+k#将训练样本标签设为N+k
savemat("F:\\DRCNN\\mask_train.mat",{'paviaU_gt':train_test_gt})
generate_train_gt(40)
# 最终得到9张‘PaviaU_gt_test{i}.mat’。对于每一张gt影像,测试样本的标签为原来的标签,其他像元的标签为0。
def generate_test_gt():
train_test_gt=loadmat("F:\\DRCNN\\mask_train.mat")['paviaU_gt']#0,1,2,……9,,, 10,11,……18
# print(np.unique(train_test_gt))
for i in range(1,10):
temp=(train_test_gt==i)*i
temp=np.asarray(temp,dtype=np.float32)
print(np.unique(temp))
savemat("F:\DRCNN\data\HSI_gt_(train and test)\\PaviaU_gt_test{}.mat".format(i),{'paviaU_gt':temp})
generate_test_gt()
2. construct_multi_mat.py
# 构建多区域的训练集patchs/测试集patchs
import warnings
warnings.filterwarnings('ignore')
import os
import argparse
import numpy as np
import os,time,cv2
import numpy as np
import scipy.io as sio
import keras as K
import keras.layers as L
import tensorflow as tf
import tifffile as tiff
def image_pad(data,r):#ksize=11*11 , r=k//2=5
if len(data.shape)==3:#HSI
data_new=np.lib.pad(data,((r,r),(r,r),(0,0)),'symmetric')
return data_new
if len(data.shape)==2:#HSI_gt
data_new=np.lib.pad(data,r,'constant',constant_values=0)
return data_new
def sample_wise_standardization(data):#HSI标准化预处理
import math
_mean = np.mean(data)
_std = np.std(data)
npixel = np.size(data) * 1.0
min_stddev = 1.0 / math.sqrt(npixel)
return (data - _mean) / max(_std, min_stddev)
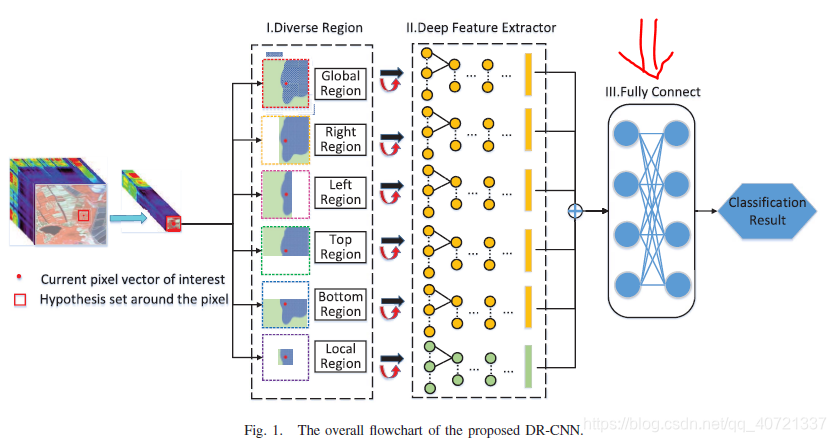
def construct_spatial_patch(mdata,mlabel,r,patch_type):
# 根据mlabel逐标签点构建HSI空间块(半径为r)和其标签
# 使用该函数需要预先做好map_train,map_test,分别调用一次本函数
patch=[]
patch_right=[]
patch_left=[]
patch_bottom=[]
patch_up=[]
patch_center=[]
label=[]
result_patchs=[]
result_labels=[]
XR=[]
XL=[]
XU=[]
XB=[]
XC=[]
if patch_type=='train':
num_class=np.max(mlabel)
for c in range(1+9,num_class+1+9):
idx,idy=np.where(mlabel==c)
for i in range(len(idx)):
patch.append(mdata[idx[i]-r:idx[i]+r+1,idy[i]-r:idy[i]+r+1,...])
patch_right.append(mdata[idx[i]-1:idx[i]+r+1,idy[i]-r:idy[i]+r+1,...])
patch_left.append(mdata[idx[i]-r:idx[i]+2,idy[i]-r:idy[i]+r+1,...])
patch_up.append(mdata[idx[i]-r:idx[i]+r+1,idy[i]-1:idy[i]+r+1,...])
patch_bottom.append(mdata[idx[i]-r:idx[i]+r+1,idy[i]-r:idy[i]+2,...])
patch_center.append(mdata[idx[i]-1:idx[i]+2,idy[i]-1:idy[i]+2,...])
label.append(mlabel[idx[i],idy[i]]-1-9)
result_patchs=np.asarray(patch,dtype=np.float32)
result_labels=np.asarray(label,dtype=np.int8)
XR=np.asarray(patch_right,dtype=np.float32)
XL=np.asarray(patch_left,dtype=np.float32)
XU=np.asarray(patch_up,dtype=np.float32)
XB=np.asarray(patch_bottom,dtype=np.float32)
XC=np.asarray(patch_center,dtype=np.float32)
return result_patchs,XR,XL,XU,XB,XC,result_labels
if patch_type=='test':
idx,idy=np.nonzero(mlabel)
for i in range(len(idx)):
patch.append(mdata[idx[i]-r:idx[i]+r+1,idy[i]-r:idy[i]+r+1,:])
patch_right.append(mdata[idx[i]-1:idx[i]+r+1,idy[i]-r:idy[i]+r+1,:])
patch_left.append(mdata[idx[i]-r:idx[i]+2,idy[i]-r:idy[i]+r+1,:])
patch_up.append(mdata[idx[i]-r:idx[i]+r+1,idy[i]-1:idy[i]+r+1,:])
patch_bottom.append(mdata[idx[i]-r:idx[i]+r+1,idy[i]-r:idy[i]+2,:])
patch_center.append(mdata[idx[i]-1:idx[i]+2,idy[i]-1:idy[i]+2,:])
label.append(mlabel[idx[i],idy[i]]-1)
result_patchs=np.asarray(patch,dtype=np.float32)
result_labels=np.asarray(label,dtype=np.int8)
XR=np.asarray(patch_right,dtype=np.float32)
XL=np.asarray(patch_left,dtype=np.float32)
XU=np.asarray(patch_up,dtype=np.float32)
XB=np.asarray(patch_bottom,dtype=np.float32)
XC=np.asarray(patch_center,dtype=np.float32)
idx=idx-2*r-1
idy=idy-2*r-1
return result_patchs,XR,XL,XU,XB,XC,result_labels,idx,idy
# Data Augmentation
def random_flip(data,xr,xl,xu,xb,xc,label,seed=0):#此处的data为result_patchs
num=data.shape[0]
datas=[]
xrs=[]
xls=[]
xus=[]
xbs=[]
xcs=[]
labels=[]
for i in range(num):
datas.append(data[i])
xrs.append(xr[i])
xls.append(xl[i])
xus.append(xu[i])
xbs.append(xb[i])
xcs.append(xc[i])
if len(data[i].shape)==3:
noise=np.random.normal(0.0,0.05,size=(data[i].shape))
datas.append(np.fliplr(data[i])+noise)
noise=np.random.normal(0.0,0.05,size=(xr[i].shape))
xrs.append(np.fliplr(xr[i])+noise)
noise=np.random.normal(0.0,0.05,size=(xl[i].shape))
xls.append(np.fliplr(xl[i])+noise)
noise=np.random.normal(0.0,0.05,size=(xu[i].shape))
xus.append(np.fliplr(xu[i])+noise)
noise=np.random.normal(0.0,0.05,size=(xb[i].shape))
xbs.append(np.fliplr(xb[i])+noise)
noise=np.random.normal(0.0,0.05,size=(xc[i].shape))
xcs.append(np.fliplr(xc[i])+noise)
labels.append(label[i])
labels.append(label[i])
datas=np.asarray(datas,dtype=np.float32)
xrs=np.asarray(xrs,dtype=np.float32)
xls=np.asarray(xls,dtype=np.float32)
xus=np.asarray(xus,dtype=np.float32)
xbs=np.asarray(xbs,dtype=np.float32)
xcs=np.asarray(xcs,dtype=np.float32)
labels=np.asarray(labels,dtype=np.float32)
np.random.seed(seed)
index=np.random.permutation(datas.shape[0])
return datas[index],xrs[index],xls[index],xus[index],xbs[index],xcs[index],labels[index]
#读取HSI和刚刚生成的HSI_gt_train,HSI_gt_test
def read_data(path,data_name):
mdata=[]
mdata=sio.loadmat(path)
mdata=np.array(mdata[data_name])
return mdata
PATH='F:\\DRCNN\\data\\PaviaU.mat'
mdata_name='paviaU'
r=5
PATH_trian='F:\\DRCNN\\data\\HSI_gt_(train and test)\\mask_train.mat'
mdata_name_train='paviaU_gt'
mdata_name_test='paviaU_gt'
save_path='F:\\DRCNN\\data\\save_results'
NUM_CLASS=9
def main():
mdata=read_data(PATH,mdata_name)
mdata=np.asarray(mdata,dtype=np.float32)
mdata=sample_wise_standardization(mdata)
mdata=image_pad(mdata,r)
mlabel_train=read_data(PATH_trian,mdata_name_train)
mlabel_train=image_pad(mlabel_train,r)
train_data_H,XR,XL,XU,XB,XC,train_label_H=construct_spatial_patch(mdata,mlabel_train,r,'train')
train_data_H,XR,XL,XU,XB,XC,train_label_H=random_flip(train_data_H,XR,XL,XU,XB,XC,train_label_H)
print('train data shape:{}'.format(train_data_H.shape))
print('right data shape:{}'.format(XR.shape))
print('left data shape:{}'.format(XL.shape))
print('up data shape:{}'.format(XU.shape))
print('botom data shape:{}'.format(XB.shape))
print('center data shape:{}'.format(XC.shape))
# shape=n*ksize*ksize*d,n取决于mlabel_train中的非零样本的个数
# SAVE TRAIN_DATA TO MAT FILE
print('Saving train data...')
data={
'data':train_data_H,
'XR':XR,
'XL':XL,
'XU':XU,
'XB':XB,
'XC':XC,
'label':train_label_H
}
path_train =os.path.join(save_path+'train_data_H.mat')
sio.savemat(path_train,data)
# SAVE TEST_DATA TO MAT FILE
for iclass in range(1,NUM_CLASS+1):
PATH_test=os.path.join('F:\\DRCNN\\data\\HSI_gt_(train and test)\\PaviaU_gt_test'+str(iclass)+'.mat')
mlabel_test=read_data(PATH_test,mdata_name_test)
mlabel_test=image_pad(mlabel_test,r)
test_data_H,XR,XL,XU,XB,XC,test_label_H,idx,idy=construct_spatial_patch(mdata,mlabel_test,r,'test')
print('test data shape:{}'.format(test_data_H.shape))
print('right data shape:{}'.format(XR.shape))
print('left data shape:{}'.format(XL.shape))
print('up data shape:{}'.format(XU.shape))
print('botom data shape:{}'.format(XB.shape))
print('center data shape:{}'.format(XC.shape))
print('Saving test data...')
data={
'hsi':test_data_H,
'XR':XR,
'XL':XL,
'XU':XU,
'XB':XB,
'XC':XC,
'label':test_label_H,
'idx':idx,#邻域左上角的行号
'idy':idy#邻域左上角的列号
}
path_test=os.path.join(save_path,'test_data_H'+str(iclass)+'.mat')
sio.savemat(path_test,data,format='5')
test_label_name=[]
mlabel_test=[]
test_data_H=[]
test_label_H=[]
idx=[]
idy=[]
XR=[]
XL=[]
XU=[]
XB=[]
XC=[]
print('Done')
if __name__=='__main__':
main()
3. data_util.py
#coding: utf-8
import os
import cv2
import tifffile as tiff
import numpy as np
import scipy.io as sio
import keras as K
from sklearn.preprocessing import MultiLabelBinarizer
# from construct_multi_mat import args
BATCH_SIZE=450
TRAIN_H='train_data_H.mat'
weights_path=os.path.join('weights\\')
if not os.path.exists(weights_path):
os.mkdir(weights_path)
PATH='F:\\DRCNN\\data\\save_results'
TEST_PATH='F:\\DRCNN\\data\\save_results'
NUM_CLASS=9
HEIGHT=610
WIDTH= 340
NUM_CHN= 103
class DataSet(object):
def __init__(self,hsi,labels):
self._hsi=hsi
self._labels=labels
@property
def hsi(self):
return self._hsi
@property
def labels(self):
return self._labels
def read_data(path,filename_H,data_style,key):
if data_style=='train':
train_data=sio.loadmat(os.path.join(path,filename_H))
hsi=np.array(train_data[key])
# hsi=sample_wise_standardization(hsi)
train_labl=np.array(train_data['label'])
return DataSet(hsi,train_labl)
else:
test_data=sio.loadmat(os.path.join(path,filename_H))
hsi=test_data[key]
test_labl=test_data['label']
test_labl=np.reshape(test_labl.T,(test_labl.shape[1]))
idx=test_data['idx']
idy=test_data['idy']
idx=np.reshape(idx.T,(idx.shape[1]))
idy=np.reshape(idy.T,(idy.shape[1]))
# hsi=sample_wise_standardization(hsi)
return DataSet(hsi,test_labl),idx,idy
def sample_wise_standardization(data):
import math
_mean = np.mean(data)
_std = np.std(data)
npixel = np.size(data) * 1.0
min_stddev = 1.0 / math.sqrt(npixel)
return (data - _mean) / max(_std, min_stddev)
def eval(predication,labels):
"""
evaluate test score
"""
num=labels.shape[0]
count=0
for i in range(num):
if(np.argmax(predication[i])==labels[i]):
count+=1
return 100.0*count/num
def generate_map(predication,idx,idy):
maps=np.zeros([HEIGHT,WIDTH])
for i in range(len(idx)):
maps[idx[i],idy[i]]=np.argmax(predication[i])+1
return maps
4. HSI_multi_SPA.py
import warnings
warnings.filterwarnings('ignore')
import keras as K
import keras.layers as L
import tensorflow as tf
import scipy.io as sio
import argparse,os
import numpy as np
import h5py
import time
import sys
from data_util import *
from sklearn.metrics import confusion_matrix
from sklearn.metrics import classification_report
from keras.preprocessing.image import ImageDataGenerator
from keras.callbacks import ModelCheckpoint,TensorBoard
from keras.utils import plot_model
#在命令行中运行此代码时可以设定的参数:epoch、mode、ksize等
parser=argparse.ArgumentParser()
parser.add_argument('--NUM_EPOCH',
type=int,
default=100,
help='number of epoch')
parser.add_argument('--mode',
type=int,
default=0,
help='train or test mode')
parser.add_argument('--train_KEY',
type=str,
default='data',
help='train data')
parser.add_argument('--test_KEY',
type=str,
default='hsi',
help='test data')
parser.add_argument('--ksize1',
type=int,
default='11',
help='patch row')
parser.add_argument('--ksize2',
type=int,
default='11',
help='patch column')
args=parser.parse_args()
if not os.path.exists('log/'):
os.makedirs('log/')
NUM_CHN=103
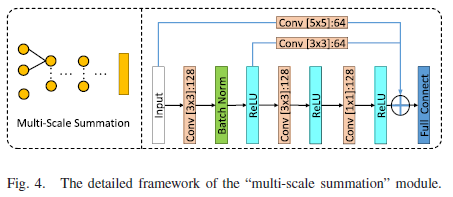
def GW_net(input_spat):
filters=[32,64,128,256]
input_spat=L.Input((args.ksize1,args.ksize2,NUM_CHN))
# 9*9
# define hsi_spatial convolution
conv0_spat=L.Conv2D(filters[2],(3,3),padding='valid')(input_spat)#kernel_size=3*3,128个
conv0_spat=L.BatchNormalization(axis=-1)(conv0_spat)
conv0_spat=L.Activation('relu')(conv0_spat)
# 7*7
conv1_spat = L.Conv2D(filters[2], (3, 3), padding='valid')(conv0_spat)
conv1_spat=L.Activation('relu')(conv1_spat)
# 3*3
conv3_spat=L.Conv2D(filters[2],(1,1),padding='valid',activation='relu')(conv1_spat)
conv5_spat=L.Conv2D(filters[1],(5,5),padding='valid',activation='relu')(input_spat)
conv6_spat=L.Conv2D(filters[1],(3,3),padding='valid',activation='relu')(conv0_spat)
conv3_spat=L.concatenate([conv3_spat,conv6_spat,conv5_spat],axis=-1)#Multi-Scale Summation
conv3_spat=L.BatchNormalization(axis=-1)(conv3_spat)
conv7_spat=L.Flatten()(conv3_spat)
logits=L.Dense(NUM_CLASS,activation='softmax')(conv7_spat)
model = K.models.Model([input_spat], logits)
opti = K.optimizers.SGD(lr=0.001, momentum=0.99, decay=1e-3)
model.compile(optimizer=opti,loss='categorical_crossentropy',metrics=['acc'])
return model
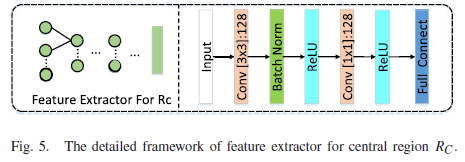
def SMALL_net(input_spat):
filters=[32,64,128,256]
conv0_spat=L.Conv2D(filters[2],(3,3),padding='valid')(input_spat)
conv0_spat=L.BatchNormalization(axis=-1)(conv0_spat)
conv1_spat=L.Activation('relu')(conv0_spat)
conv2_spat=L.Conv2D(filters[2],(1,1),padding='valid',activation='relu')(conv1_spat)
conv3_spat=L.Activation('relu')(conv2_spat)
conv7_spat=L.Flatten()(conv3_spat)
logits=L.Dense(NUM_CLASS,activation='softmax')(conv7_spat)
model = K.models.Model([input_spat], logits)
opti = K.optimizers.SGD(lr=0.001, momentum=0.99, decay=1e-3)
# kwargs=K.backend.moving_averages
model.compile(optimizer=opti,loss='categorical_crossentropy',metrics=['acc'])
return model
def SPA_net():
input_spat=L.Input((args.ksize1,args.ksize2,NUM_CHN))
if args.ksize1==3:
net=SMALL_net(input_spat)
else:
net = GW_net(input_spat)
return net
model_name=os.path.join(weights_path+args.train_KEY+'.h5')
NUM_CLASS=9
def train(model,model_name):
model_ckt = ModelCheckpoint(filepath=model_name, verbose=1, save_best_only=True)
tensorbd=TensorBoard(log_dir='./log',histogram_freq=0, write_graph=True, write_images=True)
train_data=read_data(PATH,TRAIN_H,'train',args.train_KEY)
# train_labels=K.utils.np_utils.to_categorical(train_data.labels,NUM_CLASS)
train_labels=K.utils.np_utils.to_categorical(train_data.labels)#创建独热编码,0-8,怪不得之前要减1
# print(train_labels.shape)
train_labels=np.squeeze(train_labels)
print(train_labels.shape)
print('train hsi data shape:{}'.format(train_data.hsi.shape))
print('{} train sample'.format(train_data.hsi.shape[0]))
class_weights={}
N=np.sum(train_data.labels!=0)#label不是0的元素个数??0-8
for c in range(NUM_CLASS):
n=1.0*np.sum(train_data.labels==c)
item={c:n}
class_weights.update(item)
print (class_weights)#每个类别有多少个样本
model.fit([train_data.hsi],train_labels,
batch_size=BATCH_SIZE,
# class_weight=class_weights,
epochs=args.NUM_EPOCH,
verbose=1,
validation_split=0.1,
shuffle=True,
callbacks=[model_ckt,tensorbd])
model.save(os.path.join(model_name+'_'))#??
def test(model_name,hsi_data):
model = SPA_net()
model.load_weights(model_name)
pred=model.predict([hsi_data],batch_size=BATCH_SIZE)
return pred
def main(mode=0,show=False):
if args.mode==0:
start_time=time.time()
model=SPA_net()
plot_model(model,to_file='model.png',show_shapes=True)
train(model,model_name)
duration=time.time()-start_time
print (duration)
# train_generator(model,model_name)
else:
# test_data,idx,idy=read_data(PATH,CTEST,'test',args.test_KEY)
# prediction=test(model_name,test_data.hsi,test_data.labels)
start_time=time.time()
prediction=np.zeros(shape=(1,NUM_CLASS),dtype=np.float32)
idxx=np.zeros(shape=(1,),dtype=np.int64)
idyy=np.zeros(shape=(1,),dtype=np.int64)
labels=np.zeros(shape=(1,),dtype=np.int64)
for iclass in range(1,NUM_CLASS+1):
CTEST=os.path.join('test_data_H'+str(iclass)+'.mat')
test_data,idx,idy=read_data(TEST_PATH,CTEST,'test',args.test_KEY)
tmp1=np.array(test(model_name,test_data.hsi),dtype=np.float32)
# print(np.argmax(tmp1,1))
prediction=np.concatenate((prediction,tmp1),axis=0)
idxx=np.concatenate((idxx,idx),axis=0)
idyy=np.concatenate((idyy,idy),axis=0)
tmp_label=test_data.labels
labels=np.concatenate((labels,tmp_label),axis=0)
prediction=np.delete(prediction,0,axis=0)
duration=time.time()-start_time
print (duration)
idxx=np.delete(idxx,0,axis=0)
idyy=np.delete(idyy,0,axis=0)
labels=np.delete(labels,0,axis=0)
f = open(os.path.join('prediction_'+args.train_KEY+'.txt'), 'w')
n = prediction.shape[0]
for i in range(n):
pre_label = np.argmax(prediction[i],0)
f.write(str(pre_label)+'\n')
f.close()
print(prediction.shape,labels.shape)
print('OA: {}%'.format(eval(prediction,labels)))
# generate classification map
pred_map=generate_map(prediction,idxx,idyy)
# generate confusion_matrix
prediction=np.asarray(prediction)
pred=np.argmax(prediction,axis=1)
pred=np.asarray(pred,dtype=np.int8)
print (confusion_matrix(labels,pred))
# generate accuracy
print (classification_report(labels, pred))
if __name__ == '__main__':
main()
GW_net
SMALL_net
5. main.py
import os
import warnings
warnings.filterwarnings('ignore')
train_KEY=['data','XR','XL','XU','XB','XC']
test_KEY=['hsi','XR','XL','XU','XB','XC']
ksize1=[11,7,7,11,11,3]
ksize2=[11,11,11,7,7,3]
num_result=1
for str_train_key, str_test_key, ksize_1, ksize_2 in zip(train_KEY, test_KEY, ksize1, ksize2):
os.system('python HSI_multi_SPA.py --mode 0 --train_KEY {} --test_KEY {} --ksize1 {} --ksize2 {}'\
.format(str_train_key,str_test_key,ksize_1,ksize_2))
print('@'*30)
#将shape、OA、confusion matrix、classification_report等存到result文件里
os.system('python HSI_multi_SPA.py --mode 1 --train_KEY {} --test_KEY {} --ksize1 {} --ksize2 {} > result{}'\
.format(str_train_key,str_test_key,ksize_1,ksize_2,num_result))
num_result+=1
Last Modified time:2020年2月26日10:59:57
6. HSI_multiSPA_union.py
# -*- coding: utf-8 -*-
import warnings
warnings.filterwarnings('ignore')
import keras as K
import keras.layers as L
import tensorflow as tf
import scipy.io as sio
import argparse,os
import numpy as np
import h5py
import time
import sys
from data_util import *
from sklearn.metrics import confusion_matrix
from sklearn.metrics import classification_report
from keras.preprocessing.image import ImageDataGenerator
from keras.callbacks import ModelCheckpoint,TensorBoard
from keras.utils import plot_model
parser=argparse.ArgumentParser()
parser.add_argument('--NUM_EPOCH',
type=int,
default=100,
help='number of epoch')
parser.add_argument('--mode',
type=int,
default=0,
help='train or test mode')
parser.add_argument('--full_net_',
type=bool,
default=False,
help='train or not')
parser.add_argument('--right_net_',
type=bool,
default=False,
help='train or not')
parser.add_argument('--left_net_',
type=bool,
default=False,
help='train or not')
parser.add_argument('--up_net_',
type=bool,
default=False,
help='train or not')
parser.add_argument('--bottom_net_',
type=bool,
default=False,
help='train or not')
parser.add_argument('--center_net_',
type=bool,
default=False,
help='train or not')
args=parser.parse_args()
model_name_data=os.path.join(weights_path+'data.h5')
model_name_XR=os.path.join(weights_path+'XR.h5')
model_name_XL=os.path.join(weights_path+'XL.h5')
model_name_XU=os.path.join(weights_path+'XU.h5')
model_name_XB=os.path.join(weights_path+'XB.h5')
model_name_XC=os.path.join(weights_path+'XC.h5')
new_model_name=os.path.join(weights_path+'all_mul_cnn_10.h5')
if not os.path.exists('log/'):
os.makedirs('log/')
def GW_net(input_spat):
filters=[32,64,128,256]
conv0_spat=L.Conv2D(filters[2],(3,3),padding='valid')(input_spat)#kernel_size=3*3,128个
conv0_spat=L.BatchNormalization(axis=-1)(conv0_spat)
conv0_spat=L.Activation('relu')(conv0_spat)
conv1_spat = L.Conv2D(filters[2], (3, 3), padding='valid')(conv0_spat)
conv1_spat=L.Activation('relu')(conv1_spat)
conv3_spat=L.Conv2D(filters[2],(1,1),padding='valid',activation='relu')(conv1_spat)
conv5_spat=L.Conv2D(filters[1],(5,5),padding='valid',activation='relu')(input_spat)
conv6_spat=L.Conv2D(filters[1],(3,3),padding='valid',activation='relu')(conv0_spat)
conv3_spat=L.concatenate([conv3_spat,conv6_spat,conv5_spat],axis=-1)#Multi-Scale Summation
conv3_spat=L.BatchNormalization(axis=-1)(conv3_spat)
conv7_spat=L.Flatten()(conv3_spat)
logits=L.Dense(NUM_CLASS,activation='softmax')(conv7_spat)
model = K.models.Model([input_spat], logits)
opti = K.optimizers.SGD(lr=0.001, momentum=0.99, decay=1e-3)
model.compile(optimizer=opti,loss='categorical_crossentropy',metrics=['acc'])
return model
def SMALL_net(input_spat):
filters=[32,64,128,256]
conv0_spat=L.Conv2D(filters[2],(3,3),padding='valid')(input_spat)
conv0_spat=L.BatchNormalization(axis=-1)(conv0_spat)
conv1_spat=L.Activation('relu')(conv0_spat)
conv2_spat=L.Conv2D(filters[2],(1,1),padding='valid',activation='relu')(conv1_spat)
conv3_spat=L.Activation('relu')(conv2_spat)
conv7_spat=L.Flatten()(conv3_spat)
logits=L.Dense(NUM_CLASS,activation='softmax')(conv7_spat)
model = K.models.Model([input_spat], logits)
opti = K.optimizers.SGD(lr=0.001, momentum=0.99, decay=1e-3)
# kwargs=K.backend.moving_averages
model.compile(optimizer=opti,loss='categorical_crossentropy',metrics=['acc'])
return model
def UNION_net():
input_full=L.Input((11,11,NUM_CHN))
full_net=GW_net(input_full)
full_net.load_weights(model_name_data)
full_net.layers.pop()#去掉最后用于分类的FC层
full_net.trainable=args.full_net_
full_output=full_net.layers[-1].output
input_right=L.Input((7,11,NUM_CHN))
right_net = GW_net(input_right)
right_net.load_weights(model_name_XR)
right_net.layers.pop()
right_net.trainable=args.right_net_
right_output=right_net.layers[-1].output
input_left=L.Input((7,11,NUM_CHN))
left_net=GW_net(input_left)
left_net.load_weights(model_name_XL)
left_net.layers.pop()
left_net.trainable=args.left_net_
left_output=left_net.layers[-1].output
input_up=L.Input((11,7,NUM_CHN))
up_net=GW_net(input_up)
up_net.load_weights(model_name_XU)
up_net.layers.pop()
up_net.trainable=args.up_net_
up_output=up_net.layers[-1].output
input_bottom=L.Input((11,7,NUM_CHN))
bottom_net=GW_net(input_bottom)
bottom_net.load_weights(model_name_XB)
bottom_net.layers.pop()
bottom_net.trainable=args.bottom_net_
bottom_output=bottom_net.layers[-1].output
input_center=L.Input((3,3,NUM_CHN))
center_net=SMALL_net(input_center)
center_net.load_weights(model_name_XC)
center_net.layers.pop()
center_net.trainable=args.center_net_
center_output=center_net.layers[-1].output
filters=[32,64,128,256]
# combine all patch
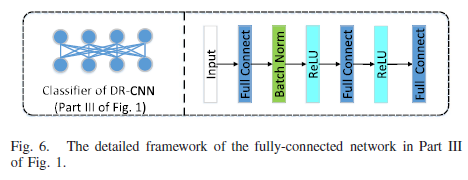
merge0=L.concatenate([full_output,right_output,left_output,up_output,bottom_output,center_output],axis=-1)
merge1=L.Dense(filters[2])(merge0)
merge1=L.BatchNormalization(axis=-1)(merge1)
merge2=L.Activation('relu')(merge1)
merge3=L.Dense(filters[3])(merge2)
# merge4=L.BatchNormalization(axis=-1)(merge3)
merge4=L.Activation('relu')(merge3)
logits=L.Dense(NUM_CLASS,activation='softmax')(merge4)#??源代码中为merge2
new_model=K.models.Model([input_full,input_right,input_left,input_up,input_bottom,input_center],logits)
sgd=K.optimizers.SGD(lr=0.001,momentum=0.99,decay=1e-4)
new_model.compile(optimizer=sgd,loss='categorical_crossentropy',metrics=['acc'])
return new_model
def train(model,model_name):
model_ckt = ModelCheckpoint(filepath=model_name, verbose=1, save_best_only=True)
tensorbd=TensorBoard(log_dir='./log',histogram_freq=0, write_graph=True, write_images=True)
train_data_full=read_data(PATH,TRAIN_H,'train','data')
train_data_XR=read_data(PATH,TRAIN_H,'train','XR')
train_data_XL=read_data(PATH,TRAIN_H,'train','XL')
train_data_XU=read_data(PATH,TRAIN_H,'train','XU')
train_data_XB=read_data(PATH,TRAIN_H,'train','XB')
train_data_XC=read_data(PATH,TRAIN_H,'train','XC')
train_labels=K.utils.np_utils.to_categorical(train_data_XC.labels,NUM_CLASS)
train_labels=np.squeeze(train_labels)#源代码中没有
print('train hsi data shape:{}'.format(train_data_full.hsi.shape))
print('train XR data shape:{}'.format(train_data_XR.hsi.shape))
print('train XL data shape:{}'.format(train_data_XL.hsi.shape))
print('train XU data shape:{}'.format(train_data_XU.hsi.shape))
print('train XB data shape:{}'.format(train_data_XB.hsi.shape))
print('train XC data shape:{}'.format(train_data_XC.hsi.shape))
print('{} train sample'.format(train_data_XC.hsi.shape[0]))
class_weights={}
N=np.sum(train_data_XC.labels!=0)
for c in range(NUM_CLASS):
n=1.0*np.sum(train_data_XC.labels==c)
item={c:n}
class_weights.update(item)
print (class_weights)
model.fit([train_data_full.hsi,train_data_XR.hsi,train_data_XL.hsi,
train_data_XU.hsi,train_data_XB.hsi,train_data_XC.hsi],train_labels,
batch_size=BATCH_SIZE,
# class_weight=class_weights,
epochs=args.NUM_EPOCH,
verbose=1,
validation_split=0.1,
shuffle=True,
callbacks=[model_ckt,tensorbd])
model.save(os.path.join(model_name+'_'))
def test(model_name,hsi_data,XR_data,XL_data,XU_data,XB_data,XC_data):
model = UNION_net()
model.load_weights(model_name)
pred=model.predict([hsi_data,XR_data,XL_data,XU_data,XB_data,XC_data],batch_size=BATCH_SIZE)
return pred
def main(mode=1,show=False):
if args.mode==0:
start_time=time.time()
model=UNION_net()
plot_model(model,to_file='model.png',show_shapes=True)
train(model,new_model_name)
duration=time.time()-start_time
print (duration)
# train_generator(model,model_name)
else:
start_time=time.time()
prediction=np.zeros(shape=(1,NUM_CLASS),dtype=np.float32)
idxx=np.zeros(shape=(1,),dtype=np.int64)
idyy=np.zeros(shape=(1,),dtype=np.int64)
labels=np.zeros(shape=(1,),dtype=np.int64)
for iclass in range(1,NUM_CLASS+1):
CTEST=os.path.join('test_data_H'+str(iclass)+'.mat')
test_data=sio.loadmat(os.path.join(TEST_PATH,CTEST))
test_data_full=test_data['hsi']
test_data_XR=test_data['XR']
test_data_XL=test_data['XL']
test_data_XU=test_data['XU']
test_data_XB=test_data['XB']
test_data_XC=test_data['XC']
test_labl=test_data['label']
test_labl=np.reshape(test_labl.T,(test_labl.shape[1]))
idx=test_data['idx']
idy=test_data['idy']
idx=np.reshape(idx.T,(idx.shape[1]))
idy=np.reshape(idy.T,(idy.shape[1]))
tmp1=np.array(test(new_model_name,test_data_full,test_data_XR,test_data_XL,
test_data_XU,test_data_XB,test_data_XC),dtype=np.float32)
prediction=np.concatenate((prediction,tmp1),axis=0)
idxx=np.concatenate((idxx,idx),axis=0)
idyy=np.concatenate((idyy,idy),axis=0)
labels=np.concatenate((labels,test_labl),axis=0)
prediction=np.delete(prediction,0,axis=0)
duration=time.time()-start_time
print (duration)
idxx=np.delete(idxx,0,axis=0)
idyy=np.delete(idyy,0,axis=0)
labels=np.delete(labels,0,axis=0)
print(prediction.shape,labels.shape)
print('OA: {}%'.format(eval(prediction,labels)))
# generate classification map
pred_map=generate_map(prediction,idxx,idyy)
# generate confusion_matrix
prediction=np.asarray(prediction)
pred=np.argmax(prediction,axis=1)
pred=np.asarray(pred,dtype=np.int8)
print (confusion_matrix(labels,pred))
# generate accuracy
f = open(os.path.join(str(NUM_CLASS)+'prediction.txt'), 'w')
n = prediction.shape[0]
for i in range(n):
pre_label = np.argmax(prediction[i],0)
f.write(str(pre_label)+'\n')
f.close()
print (classification_report(labels, pred))
if __name__ == '__main__':
main()
UNOIN_net
将main.py改为:
import os
import warnings
warnings.filterwarnings('ignore')
train_KEY=['data','XR','XL','XU','XB','XC']
test_KEY=['hsi','XR','XL','XU','XB','XC']
ksize1=[11,7,7,11,11,3]
ksize2=[11,11,11,7,7,3]
num_result=1
for str_train_key, str_test_key, ksize_1, ksize_2 in zip(train_KEY, test_KEY, ksize1, ksize2):
os.system('python HSI_multi_SPA.py --mode 0 --train_KEY {} --test_KEY {} --ksize1 {} --ksize2 {}'\
.format(str_train_key,str_test_key,ksize_1,ksize_2))
print('@'*30)
#将shape、OA、confusion matrix、classification_report等存到result文件里
os.system('python HSI_multi_SPA.py --mode 1 --train_KEY {} --test_KEY {} --ksize1 {} --ksize2 {} > result{}'\
.format(str_train_key,str_test_key,ksize_1,ksize_2,num_result))
num_result+=1
full_net_= [False]#不再重新训练它了
right_net_= [True]
left_net_= [False]
up_net_= [True]
bottom_net_=[True]
center_net_=[True]
num_result=11
for full_net,right_net,left_net,up_net,bottom_net,center_net in zip(full_net_,right_net_,left_net_,up_net_,bottom_net_,center_net_):
print (num_result)
os.system('python HSI_multiSPA_union.py --mode 0 --full_net_ {} --right_net_ {} --left_net_ {} --up_net_ {} --bottom_net_ {} --center_net_ {}'\
.format(full_net,right_net,left_net,up_net,bottom_net,center_net))
print('%'*30)
os.system('python HSI_multiSPA_union.py --mode 1 --full_net_ {} --right_net_ {} --left_net_ {} --up_net_ {} --bottom_net_ {} --center_net_ {} > result{}'\
.format(full_net,right_net,left_net,up_net,bottom_net,center_net,num_result))
num_result+=1
Last Modified time: 2020年2月27日14:54:36



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











