









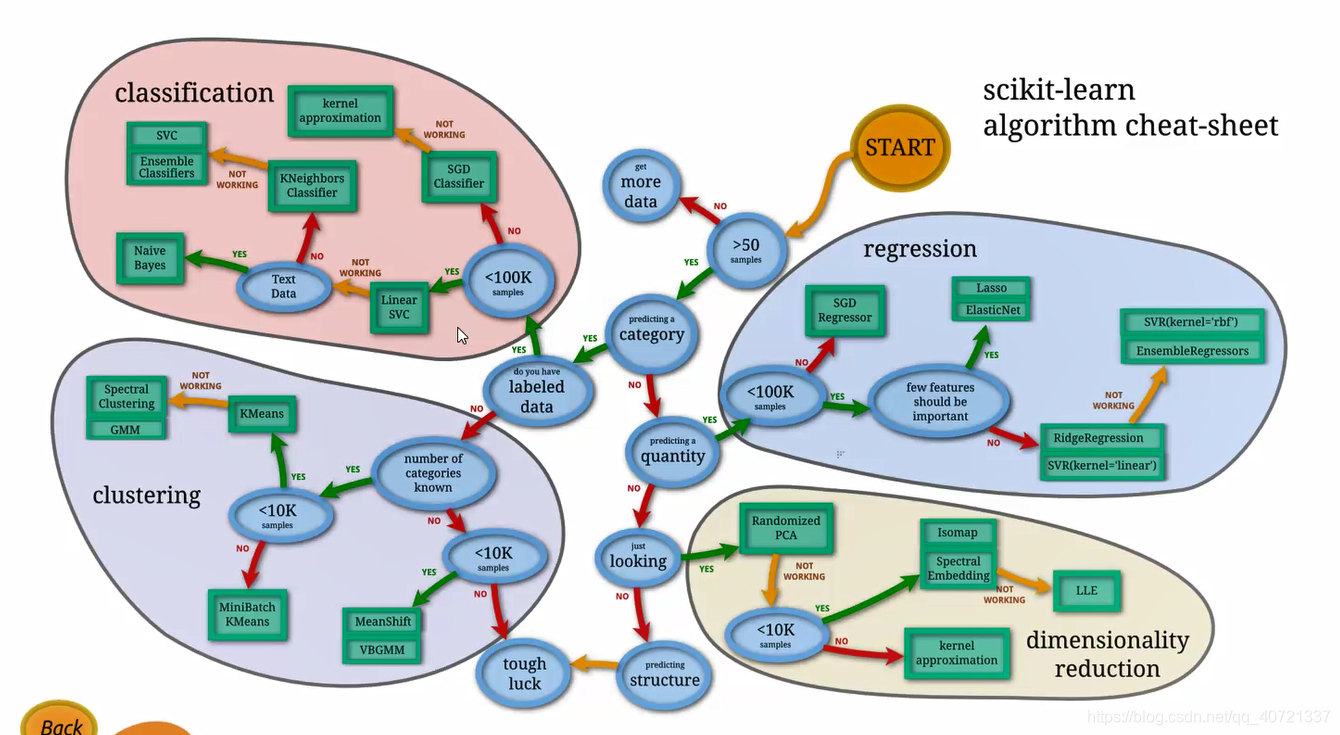
文章目录
- “鸢尾花”的3D散点图
from sklearn import datasets
import pandas as pd
import pyecharts as pec
import numpy as np
#获取鸢尾花数据集
iris=datasets.load_iris()
#花瓣的长宽,茎的长宽
# print(iris.data) #150*4
# print(iris.data.shape)
# print(len(iris.data))
#花的3种类别标签
#print(iris.target)
#三类鸢尾花的3D散点图
iris_df=pd.DataFrame(
{
'x0':[iris.data[i][0] for i in range(len(iris.data))],
'x1':[iris.data[i][1] for i in range(len(iris.data))],
'x2':[iris.data[i][2] for i in range(len(iris.data))],
'x3':[iris.data[i][3] for i in range(len(iris.data))],
'type':iris.target
})
df_type0=iris_df[iris_df.type==0]
# print(df_type0)
df_type1=iris_df[iris_df.type==1]
df_type2=iris_df[iris_df.type==2]
data_type0=df_type0.drop(labels=['type','x3'],axis=1).values
print(data_type0)
data_type1=df_type1.drop(labels=['type','x3'],axis=1).values
data_type2=df_type2.drop(labels=['type','x3'],axis=1).values
range_color=['#313695','#ffffbf','#a50026']
scatter3D=pec.Scatter3D('3D散点图',width=1280,height=720)
scatter3D.add('',data_type0)
scatter3D.add('',data_type1)
scatter3D.add('',data_type2)
scatter3D.render(path='iris_sdscatter.html')

- LinearSVC分类器的训练及预测
from sklearn import datasets
from sklearn import svm
from sklearn.model_selection import train_test_split
#获取鸢尾花数据集
iris=datasets.load_iris()
X=iris.data
y=iris.target
#test_size=0.3测试集占总样本个数的30%
#random_state=0确保每次都按照一样的顺序挑选数据
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.3,random_state=0)
#LinearSVC是SVM的一种
#创建分类器/回归器
#clf.fit()
#clf.predict()
clf=svm.LinearSVC()
clf.fit(X_train,y_train)
print('测试OA:{}'.format(clf.score(X_test,y_test)))
#测试集类别标签
print(clf.predict(X_test))
print(y_test)
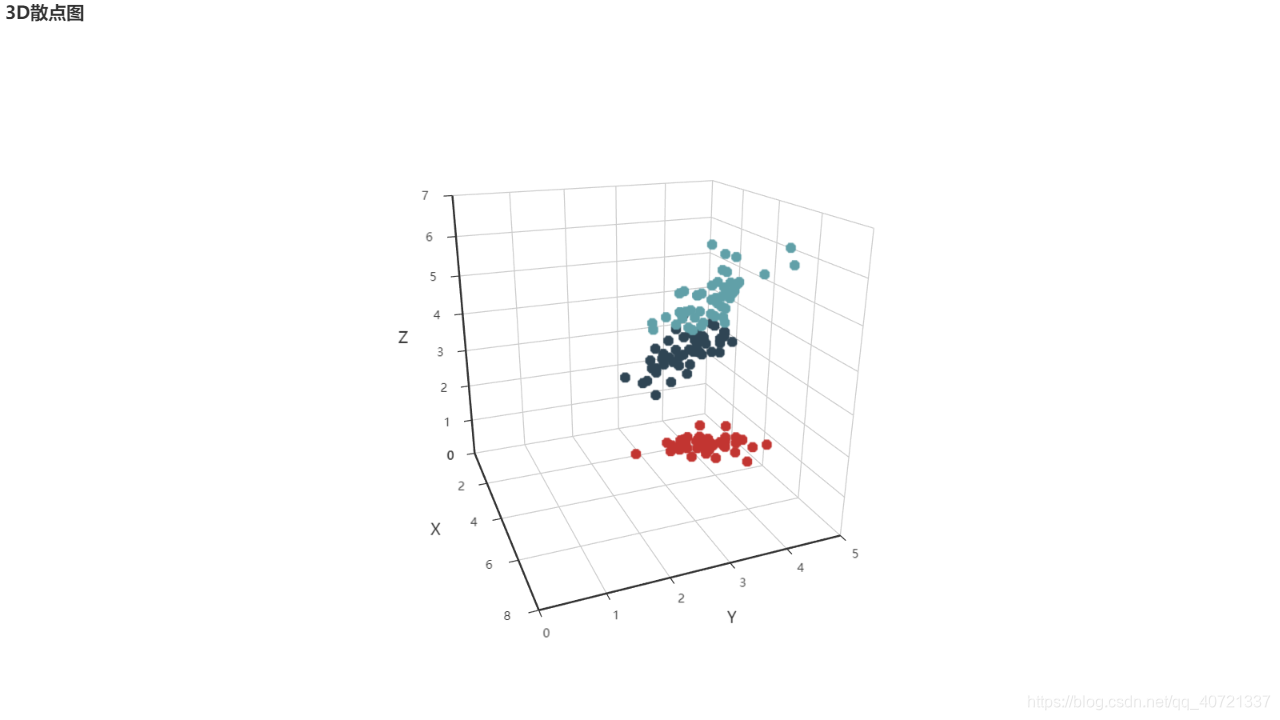
- “波士顿”的散点图
from sklearn import datasets
import pyecharts as pec
#波士顿数据,506行数据,13个属性+房价
boston=datasets.load_boston()
# print(boston.feature_names)
# print(boston.target.shape)
#绘制每一个‘属性-房价’的散点图
scatter_list=[]
for i in range(13):
scatter=pec.Scatter(boston.feature_names[i],title_pos='center')
scatter.add('',boston.data[:,i],boston.target)
scatter_list.append(scatter)
page=pec.Page()
for i in range(13):
page.add(scatter_list[i])
page.render()
- Lasso回归与网格搜索
from sklearn import datasets
from sklearn import linear_model
from sklearn import model_selection
from sklearn.metrics import mean_squared_error
import numpy as np
boston=datasets.load_boston()
X_train,X_test,y_train,y_test=model_selection.train_test_split(boston.data,boston.target,test_size=0.3,random_state=13)
#GridSearchCV网格搜索
alpha_range=np.arange(0,1,0.05)
param_grid={'alpha':alpha_range}
# print(param_grid)
lasso=linear_model.Lasso()
lasso_search=model_selection.GridSearchCV(lasso,param_grid)
lasso_search.fit(X_train,y_train)
# for result in lasso_search.cv_results_:#grid_scores_弃用了
# print(result)
print(lasso_search.best_score_)
print(lasso_search.best_params_)
print(lasso_search.best_estimator_)#保存最佳的模型,以便下回调用
# lasso.fit(X_train,y_train)
# # print(lasso.predict(X_test))
# #均方根误差
# mse=mean_squared_error(y_test,lasso.predict(X_test))
# print('MSE:',mse)
# #OA
# score=lasso.score(X_test,y_test)
# print('score:',score)
'''
各种回归模型
lasso=linear_model.Lasso()
eln_reg=linear_model.ElasticNet()
svr_reg=scm.SVR()
nusvr_reg=svm.NuSVR()
ridge_reg=linear_model.Ridge()
gbr_reg=ensemble.GradientBoostingRegressor()
'''
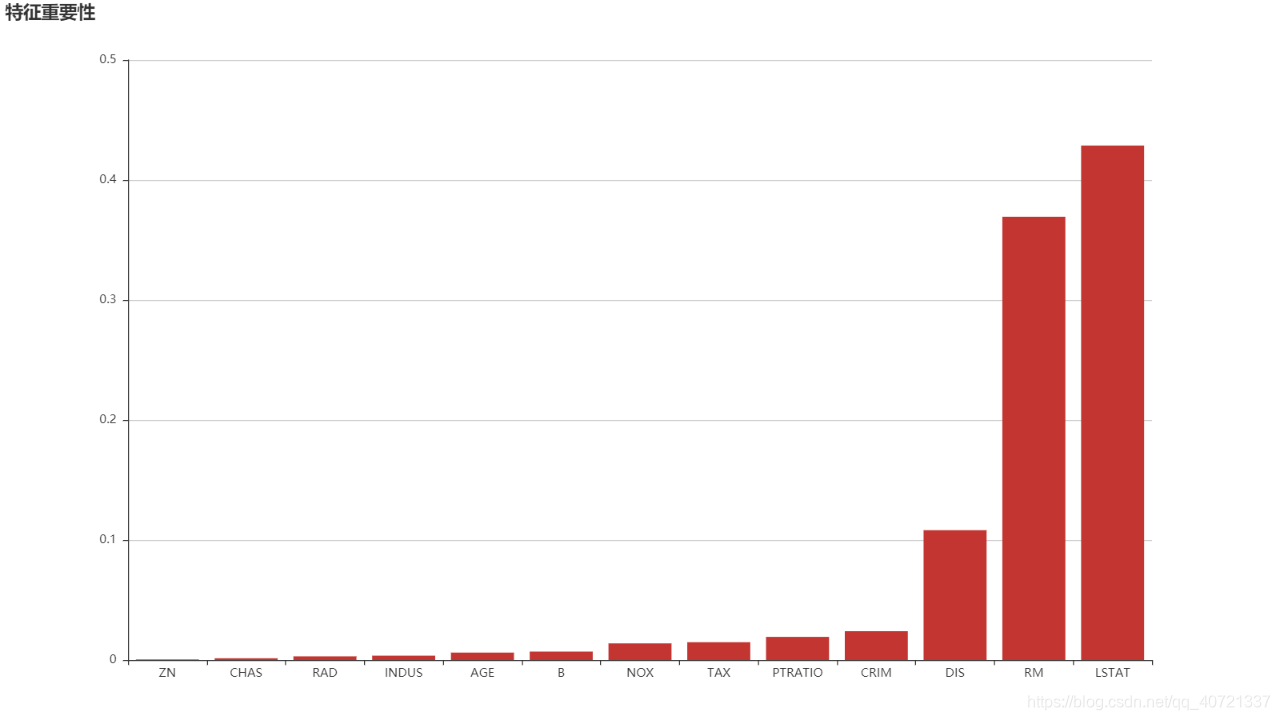
- 特征重要性(gradientboostingregressor)之条形图
from sklearn import datasets
from sklearn import linear_model
from sklearn import model_selection
from sklearn.metrics import mean_squared_error
import numpy as np
from sklearn import ensemble
import pandas as pd
import pyecharts as pec
boston=datasets.load_boston()
X_train,X_test,y_train,y_test=model_selection.train_test_split(boston.data,boston.target,test_size=0.3,random_state=13)
gbr_reg=ensemble.GradientBoostingRegressor()
gbr_reg.fit(X_train,y_train)
print(gbr_reg.feature_importances_)
feature_importance_df=pd.DataFrame({
'name':boston.feature_names,
'importance':gbr_reg.feature_importances_
})
feature_importance_df.sort_values(by='importance',inplace=True)
bar=pec.Bar('特征重要性',width=1280,height=720)
bar.add('',feature_importance_df['name'],feature_importance_df['importance'])
bar.render('feature_importance.html')
- 网格搜索(GridSearchCV) VS 随机搜索(RandomizedSearchCV)
from sklearn import datasets
from sklearn import linear_model
from sklearn import model_selection
from sklearn.metrics import mean_squared_error
import numpy as np
from sklearn import ensemble
import pandas as pd
import pyecharts as pec
boston=datasets.load_boston()
X_train,X_test,y_train,y_test=model_selection.train_test_split(boston.data,boston.target,test_size=0.3,random_state=13)
# 随机搜索
n_estimators_range=np.arange(10,1000,10)
max_depth_range=np.arange(1,10)
learning_rate_range=[0.001,0.01,0.1]
param_grid={
'n_estimators':n_estimators_range,
'max_depth':max_depth_range,
'learning_rate':learning_rate_range
}
gbr_reg=ensemble.GradientBoostingRegressor()
# n_iter:测试30次
gbr_search=model_selection.RandomizedSearchCV(gbr_reg,param_grid,n_iter=30)
gbr_search.fit(X_train,y_train)
print(gbr_search.best_score_)
print(gbr_search.best_params_)
print(gbr_search.best_estimator_)
- 作业:“糖尿病”数据预测
from sklearn import datasets
import pandas as pd
import pyecharts as pec
from sklearn import ensemble,model_selection
import pandas as pd
import numpy as np
from sklearn.svm import SVR
diabetes=datasets.load_diabetes()
X_train,X_test,y_train,y_test=model_selection.train_test_split(diabetes.data,diabetes.target,test_size=0.3)
# 绘制“属性-患病预测值”散点图
#print(diabetes.DESCR)#442*11,10 attributes,1 target
# diabetes_df=diabetes.data.T[:9]
# temp_list=[]
# for i in range(len(diabetes_df)):
# temp=diabetes_df[i]
# temp_list.append(temp)
# scatter_list=[]
# for i in range(len(diabetes_df)):
# scatter=pec.Scatter(diabetes.feature_names[i],title_pos='center')
# scatter.add('',temp_list[i],diabetes.target)
# scatter_list.append(scatter)
# page=pec.Page()
# for i in range(len(diabetes_df)):
# page.add(scatter_list[i])
# page.render('diabetes_scatter.html')
# 首先创建回归模型,然后随机搜索参数,最后进行预测
# n_estimators_range=(10,1000,10)
# max_depth_range=np.arange(1,10)
# learning_rate_range=[0.001,0.01,0.1]
# param_grid={
# 'n_estimators':n_estimators_range,
# 'max_depth':max_depth_range,
# 'learning_rate':learning_rate_range
# }
# gbr=ensemble.GradientBoostingRegressor()
# gbr_search=model_selection.RandomizedSearchCV(gbr,param_grid,n_iter=40)
# gbr_search.fit(X_train,y_train)
# print(gbr_search.best_score_)
# print(gbr_search.best_params_)
# print(gbr_search.best_estimator_)
gamma_range=[0.05,0.1,0.2,0.3,0.4,0.5]
C_range=[1e1,1e2,1e3,1e4,1e5,1e6]
param_grid={
'gamma':gamma_range,
'C':C_range
}
svr=SVR(kernel='rbf')
svr_search=model_selection.RandomizedSearchCV(svr,param_grid,n_iter=40)
svr_search.fit(X_train,y_train)
print(svr_search.best_score_)
print(svr_search.best_params_)
过年每天都要运动,学习,少吃饭——2020年1月20日12:09:11



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











