







打算分为三部分来写:数据处理,模型搭建,损失及计算,这是第一部分
一.停用词
想去掉每行中的\n,不用readline(),而用.read().splitlines()
stopWords = open('data/stopwords.txt').read().splitlines()
print("取停用词完成")
for i in range(len(data_text)):
temp = data_text[i].split(' ')
datatext.append([t for t in temp if t not in stopWords])
Python splitlines() 按照行(’\r’, ‘\r\n’, \n’)分隔,返回一个包含各行作为元素的列表,如果参数 keepends 为 False,不包含换行符,如果为 True,则保留换行符。
二.pytorch 调用tensorboard
可以看到有很多的writer,记录了损失,cd到这个目录下,然后输入下面这个命令
log % tensorboard --logdir=’./TextRCNN’
浏览器打开 http://localhost:6006/
就可以看到可视化图了
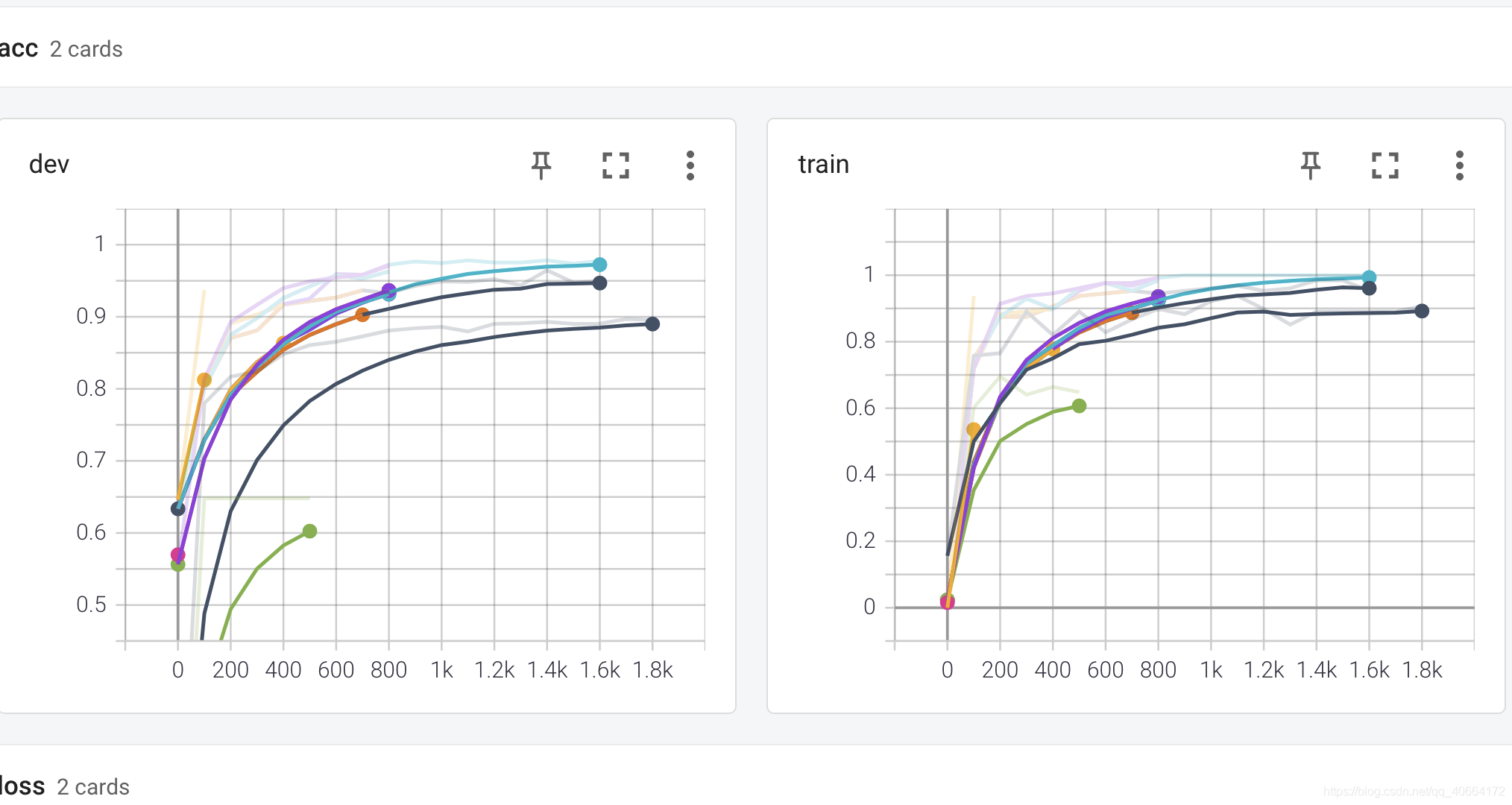
虽然现在的菜鸡水平认为tensorboard远没有log出我print的内容,或者存我最优的训练模型有用……


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









