







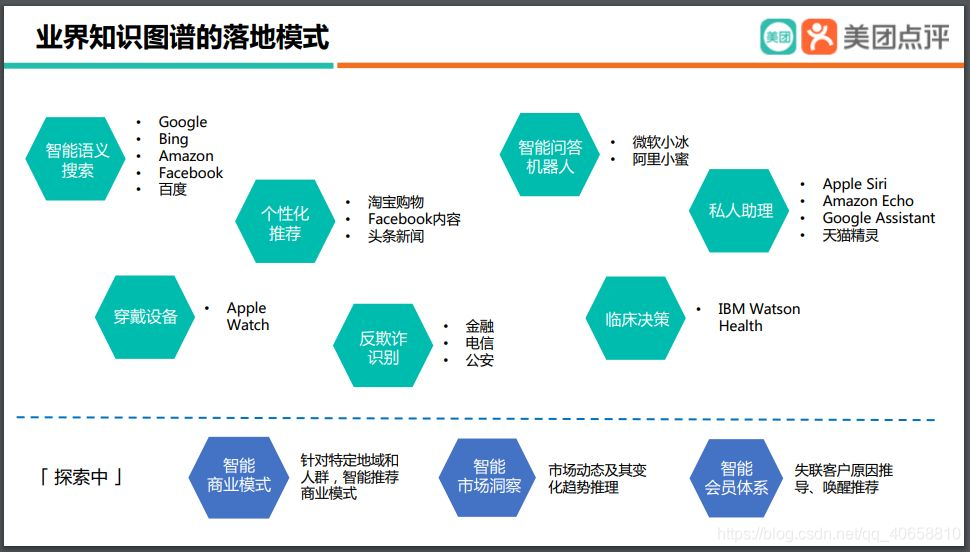
文章目录
一、当前应用
示例:pandas 是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的。
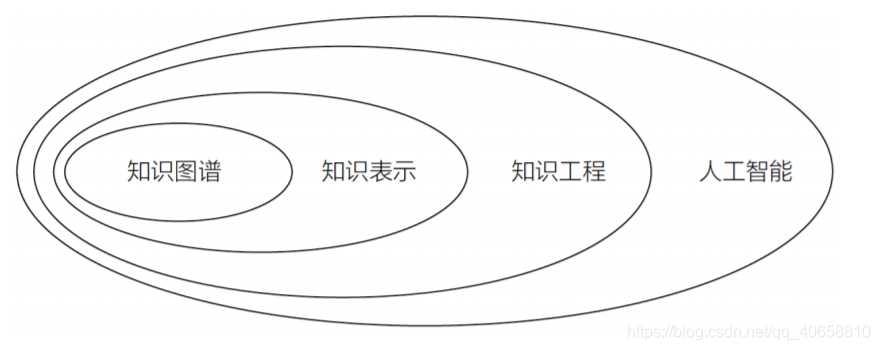
二、知识图谱定义
知识图谱是由 Google 公司在 2012 年提出来的一个新的概念。从学术的角度,我们可以对知识图谱给一个这样的定义:“知识图谱本质上是语义网络(Semantic Network)的知识库”。但这有点抽象,所以换个角度,从实际应用的角度出发其实可以简单地把知识图谱理解成多关系图(Multi-relational Graph)。
1.图
将实际中的人、物、地点等,抽闲为节点,它们彼此之间的关系为边。
2.架构(schema)
介绍:限定欲加入知识图谱的数据格式,里面包含了该领域内有意义的概念类型以及这些类型的属性。
作用:规范结构化数据的表达,一条数据必须满足Schema预先定义好的实体对象及其类型,才被允许更新到知识图谱中, 一图胜千言。
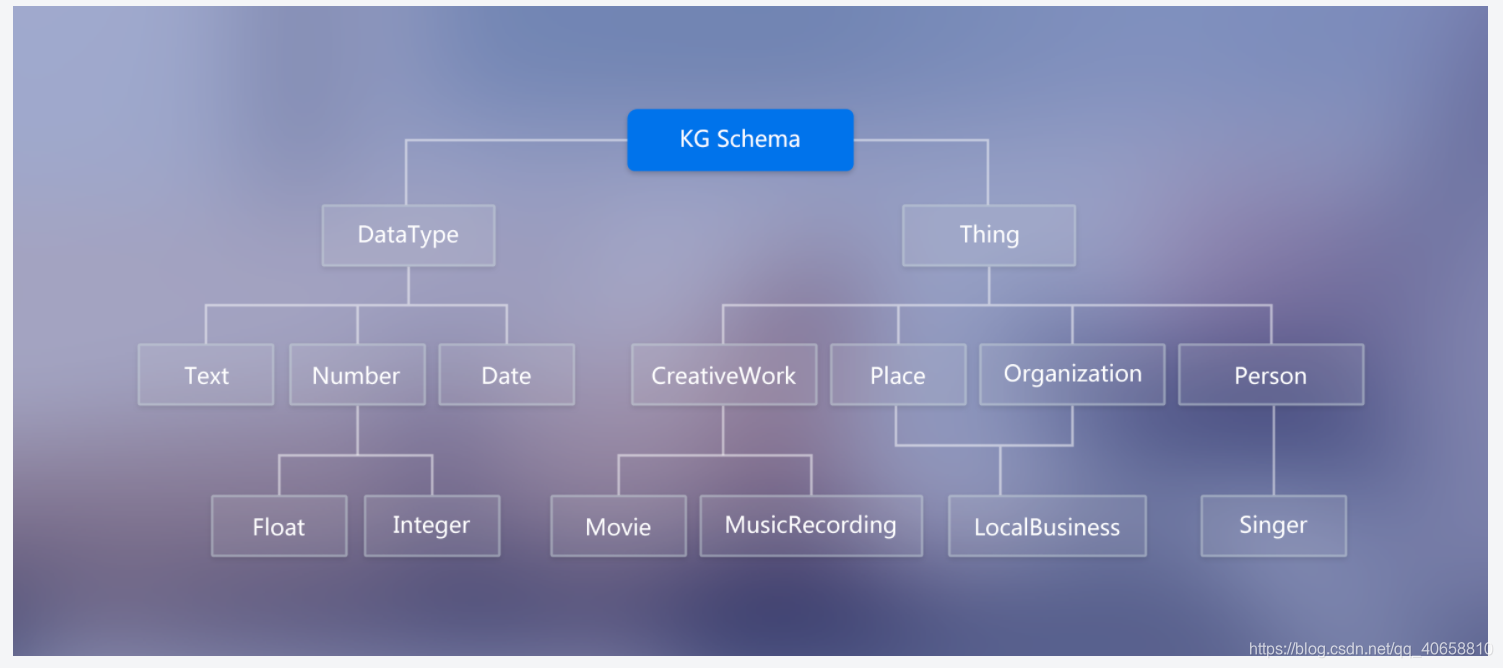
图中的DataType限定了知识图谱节点值的类型为文本、日期、数字(浮点型与整型)
图中的Thing限定了节点的类型及其属性(图中的边)
三、构建知识图谱
1.数据来源
①业务本身的数据
②网页公开数据
2.信息抽取难点:处理非结构化数据
3.构建知识图谱需要的技术
实体命名识别(Name Entity Recognition):简称NER ,目标:就是从文本里提取出实体并对每个实体做分类/打标签;
关系抽取(Relation Extraction):简称 RE,通过关系抽取技术,把实体间的关系从文本中提取出来
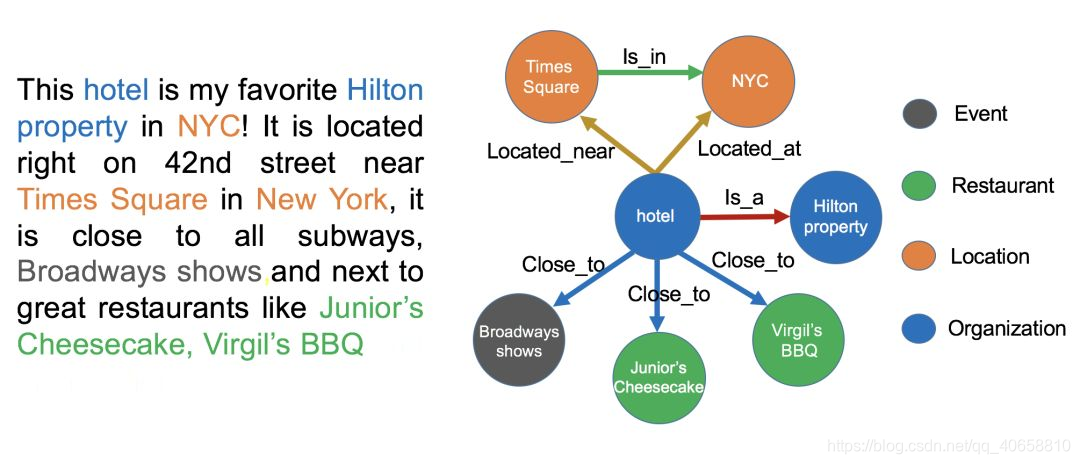
实体统一(Entity Resolution):简称 ER,介绍:对于有些实体写法上不一样,但其实是指向同一个实体;举例说明:比如“NYC”和“New York”表面上是不同的字符串,但其实指的都是纽约这个城市,需要合并。价值:实体统一不仅可以减少实体的种类,也可以降低图谱的稀疏性(Sparsity);
指代消解(Coreference Resolution):介绍:文本中出现的“it”, “he”, “she”这些词到底指向哪个实体,比如在本文里两个被标记出来的“it”都指向“hotel”这个实体。
…
4.具体构建技术
四、知识图谱的存储
知识图谱主要有两种存储方式:一种是基于RDF的存储;另一种是基于图数据库的存储。

五、环境配置
参考:https://blog.youkuaiyun.com/qq_32507417/article/details/112403721
注意:下载JDK时在对应的系统里面下载,之前我在win系统里面注册了账号,想直接下载Linux版本的jdk,发现下载一直报错,后来到Ubuntu里面浏览器下载就好了。在Ubuntu上装老是出问题后面我又在win10下装了,安装好jdk后,安装neo4j,注意解压目录不能有空格(我开始放在有空格的文件夹下后面运行时报错),添加环境变量和path,之后按Ctrl+shift+ESC,点文件新建任务,勾选以管理员身份运行,输入cmd进入命令行,输入neo4j.bat console,然后在浏览器中打开http://localhost:7474/
Cypher查询语言:是Neo4J的声明式图形查询语言,允许用户不必编写图形结构的遍历代码,就可以对图形数据进行高效的查询。
设计目的:类似SQL,适合于开发者以及在数据库上做点对点模式(ad-hoc)查询的专业操作人员。
其具备的能力包括:
创建、更新、删除节点和关系
通过模式匹配来查询和修改节点和关系 - 管理索引和约束等
六、neo4j实战
删除库
MATCH (n) DETACH DELETE n
创建人物节点
CREATE (n:Person {
name:'John'}) RETURN n
提示:CREATE是创建操作,Person是标签,代表节点的类型。
花括号{}代表节点的属性,属性类似Python的字典。
这条语句的含义就是创建一个标签为Person的节点,该节点具有一个name属性,属性值是John。
同样,再创建5个人物节点
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 6563
6563

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









