







方式一:
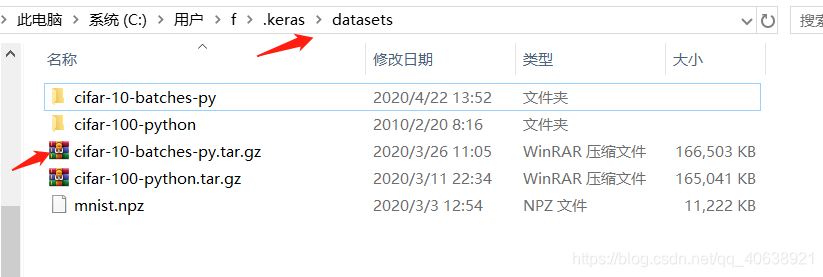
通过代码直接加载压缩文件获取,这里以cifar10为例。首先压缩文件应放在相应的位置,然后通过代码实现加载并获取数据。注意两点:
- 这种加载方式看不到图片
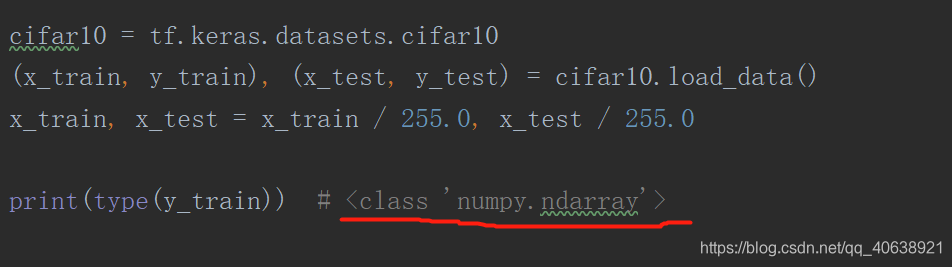
- 正如代码中所提示的那样,你所加载出的数据格式为<class 'numpy.ndarray'>
方式二:
通过本地加载图片数据,并对图片进行预处理来实现数据的输入。所需要解决的问题如下:
- 如何将压缩包中的文件转换成图片
- 拿到真正的图片后如何对图片进行预处理(主要是实现图片与标签的绑定,成为可用的训练数据)
首先压缩包中文件格式如下:
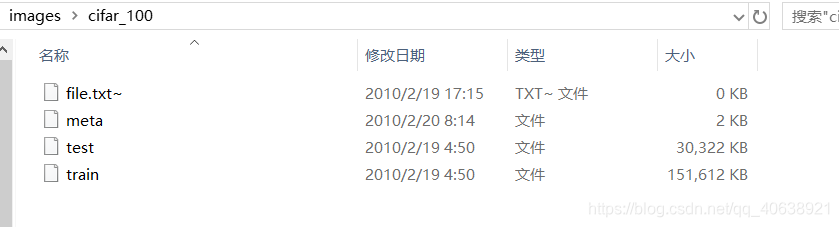
直接上转换为可用图片的代码。只需要注意,需要转换的图片数量,文件路径,根据图片标签建立目录即可。
import pickle as p
import numpy as np
from PIL import Image
import os
def load_cifar10(filename, num):
with open(filename, 'rb')as f:
datadict = p.load(f, encoding='latin1')
images = datadict['data']
labels = datadict['labels']
images = images.reshape(num, 3, 32, 32)
labels = np.array(labels)
return images, labels.tolist()
def load_cifar100(filename, num):
'''
字典属性:
b’firename’:图片的文件名
b’batch_label’:图片对应批次
b’fine_labels’:0~99,对应图像分类的标签
b’coarse_labels’:0~19,对应图像超类的标签
b’data’:10000X3072的NumPy数组,每行表示一个图片实例,其中每个实例都以32(长)X32(宽)X3(RGB)表示。
'''
with open(filename, 'rb')as f:
datadict = p.load(f, encoding='latin1')
images = datadict['data']
labels = datadict['fine_labels']
images = images.reshape(num, 3, 32, 32)
labels = np.array(labels)
return images, labels.tolist()
def load_labels_name(filename):
with open(filename, 'rb') as f:
lines = [x for x in f.readlines()]
print(lines)
if __name__ == "__main__":
# test/train/
num = 50000 # 网络上得知训练集共有50000张图片
load_labels_name("./images/cifar_100/meta")
image 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1164
1164

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









