







1 决策树简介
决策树是一种常见的机器学习算法,用于分类和回归任务。它通过构建一棵树状结构来进行决策,并根据输入数据的特征逐步进行分裂,最终达到对数据进行分类或者回归的目的。决策树的一个重要任务是为了理解数据中所蕴含的知识信息,因此可以使用不熟悉的数据集合,并从中提取出一系列规则;根据数据集创建规则的过程,就是机器学习的过程。
决策树的一些关键概念和特点:
- 树状结构: 决策树由节点(nodes)和边(edges)组成,其中节点分为内部节点(internal nodes)和叶节点(leaf nodes)。内部节点表示对数据的某个特征进行测试,叶节点表示最终的分类或回归结果。
- 特征选择: 决策树在每个内部节点上选择最佳的特征来进行数据分割。选择标准通常是根据信息增益(Information Gain)、基尼不纯度(Gini Impurity)等指标来衡量分裂后的数据纯度或不确定性的减少,本文使用信息增益(Information Gain)指标进行评估。
- 递归分割: 决策树的构建是一个递归的过程,在每个内部节点上选择最佳特征进行分裂,直到满足某个停止条件(如达到最大深度、节点包含的样本数低于阈值等)为止。
- 预测与分类: 当新的样本经过决策树时,根据其特征值从根节点开始,沿着树的分支一直到达叶节点,最终将样本分类到相应的类别中。
- 易解释性: 决策树具有很好的可解释性,因为它们的决策过程可以直观地呈现为树形结构,可以清晰地显示每个特征对于最终结果的影响。
- 过拟合问题: 决策树容易过拟合训练数据,特别是在树的深度较大时。为了减轻过拟合,可以通过剪枝(pruning)等技术来限制树的复杂度。
- 集成: 决策树还可以通过集成方法(如随机森林、梯度提升树等)来提高预测性能,通过组合多个决策树的预测结果来减少过拟合并提高泛化能力。
2 构造决策树
检测数据集中的每个子项是否属于同一分类:
If so return类标签
Else
寻找划分数据集的最好特征
划分数据集
创建分支节点
for每个划分的子集
调用函数createBranch并增加返回结果到分支节点中
return分支节点构造决策树时需要解决的第一个问题:当前数据集上哪个特征在划分数据分类时起决定性作用?
为了找到决定性的特征,划分出最好的结果,我们必须评估每个特征,选出最好的特征。
信息增益(information gain)的计算过程
原始数据集:D;类别标签集合:C;特征集合:V
- 计算原始熵:K为类别标签总数
- 计算条件熵:n为特征总数
- 计算信息增益
一般而言,信息增益越大,则意味着使用属性a来进行划分所获得的“纯度提升”越大。
信息增益计算过程的python代码:
# 计算原始熵
def calcShannonEnt(dataSet):
numEntries = len(dataSet) # 计算数据集的实例总数
# 计算每个标签出现的频数并存储在字典中
labelCounts = {}
for featVec in dataSet:
# 数据集最后一列为样本标签
currentLabel = featVec[-1]
# 如果字典中没有此标签,扩展字典
if currentLabel not in labelCounts.keys():
labelCounts[currentLabel] = 0
labelCounts[currentLabel] += 1
# 计算熵
shannonEnt = 0.0
for key in labelCounts:
prob = float(labelCounts[key]) / numEntries
shannonEnt -= prob * log(prob, 2)
return shannonEnt# 按照给定特征划分数据集
# 参数列表:待划分的数据集、划分数据集的特征、需要返回的特征的值
def splitDataSet(dataSet, axis, value):
retDataSet = []
for featVec in dataSet:
if featVec[axis] == value:
# 将符合特征的数据抽取出来存入reDataSet列表
reducedFeatVec = featVec[:axis] # chop out axis used for splitting
reducedFeatVec.extend(featVec[axis + 1:])
retDataSet.append(reducedFeatVec)
return retDataSet# 选择最好的划分数据集的特征
def chooseBestFeatureToSplit(dataSet):
# 计算特征个数
numFeatures = len(dataSet[0]) - 1
# 计算原始数据集的香农熵
baseEntropy = calcShannonEnt(dataSet)
# 初始化
bestInfoGain = 0.0
bestFeature = -1
for i in range(numFeatures): # 遍历所有特征
# 得出特征i的所有可能的值
featList = [example[i] for example in dataSet]
# 剔除重复的值,得到一个唯一属性值的集合
uniqueVals = set(featList)
# 计算按特征i的属性值划分数据集后的新熵
newEntropy = 0.0
for value in uniqueVals:
subDataSet = splitDataSet(dataSet, i, value)
prob = len(subDataSet) / float(len(dataSet))
newEntropy += prob * calcShannonEnt(subDataSet)
# 计算信息增益
infoGain = baseEntropy - newEntropy
# 比较所有特征的信息增益,选择最好的特征
if infoGain > bestInfoGain:
bestInfoGain = infoGain
bestFeature = i
return bestFeature用递归构建决策树
决策树分类的工作原理:获取原始数据集,然后基于最好的属性值划分数据集,由于特征值可能多于两个,因此可能存在大于两个分支的数据集划分。第一次划分之后,数据将被向下传递到树分支的下一个节点;在这个节点上,我们可以再次划分数据。因此可以采用递归的方式处理数据集。
递归结束的条件:程序遍历完所有划分数据集的属性,或者每个分支下的所有实例都具有相同的分类。如果所有实例具有相同的分类,则得到一个叶子节点或者终止块。任何到达叶子节点的数据必然属于叶子节点的分类。
def createTree(dataSet, labels):
classList = [example[-1] for example in dataSet]
# 如果所有实例属于相同的分类,停止继续划分
if classList.count(classList[0]) == len(classList):
return classList[0]
# 如果使用完所有的特征仍然不能将数据集划分成仅包含唯一类别的分组,停止继续划分
if len(dataSet[0]) == 1:
return majorityCnt(classList)
bestFeat = chooseBestFeatureToSplit(dataSet)
bestFeatLabel = labels[bestFeat]
myTree = {bestFeatLabel: {}}
del (labels[bestFeat])
featValues = [example[bestFeat] for example in dataSet]
uniqueVals = set(featValues)
for value in uniqueVals:
subLabels = labels[:]
myTree[bestFeatLabel][value] = createTree(splitDataSet(dataSet, bestFeat, value), subLabels)
return myTree3 代码测试
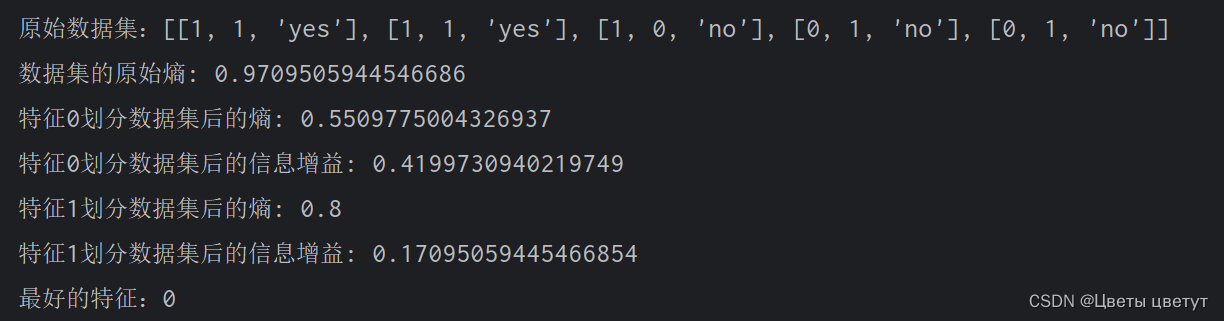
def createDataSet():
dataSet = [[1, 1, 'yes'],
[1, 1, 'yes'],
[1, 0, 'no'],
[0, 1, 'no'],
[0, 1, 'no']]
labels = ['no surfacing', 'flippers']
return dataSet, labels
# 测试
myDat, labels = createDataSet()
print("原始数据集:{}".format(myDat))
print("myTree:{}".format(createTree(myDat, labels)))运行结果:
![]()


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









