







一.理论介绍
(一).模型拟合状态
在开始之前,我们先来认识一下拟合的一些概念,包括欠拟合,过拟合,和刚好三种状态:
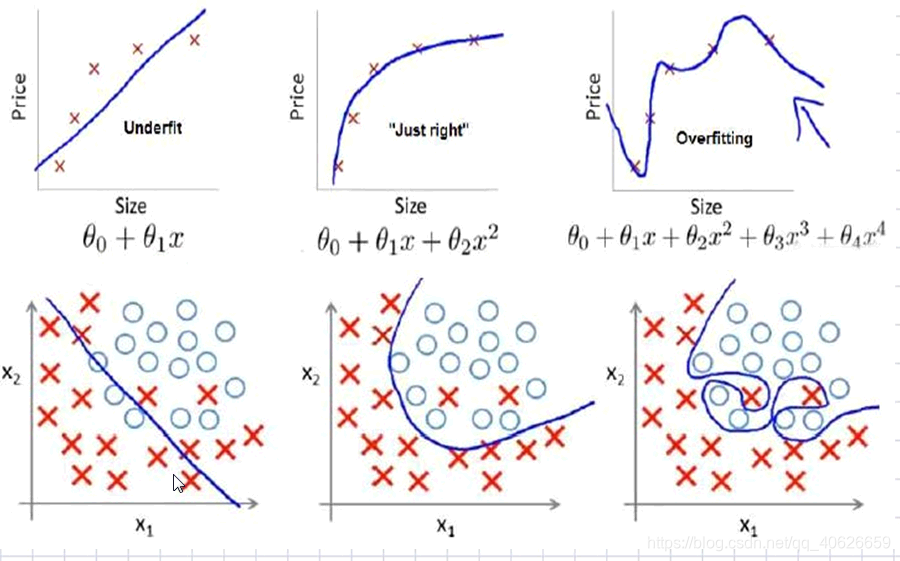
第一个模型有许多错分的数据,不能很好地适应我们的训练集,属于欠拟合;
第三个模型是很复杂的模型,很完美的拟合了训练集的每个数据.但是过于强调拟合原始数据,而丢失了算法的本质:预测新数据。我们可以看出,若给出一个新的值使之预测,它将表现的很差,是过拟合
第二个模型虽然有个别错误数据点,但是预测新数据效果很好
(二).过拟合及原因
通过认识上面的模型,我们会发现在模型拟合的过程中,有些模型在训练集上表现的很好,但在遇到最新数据时表现的不太出色,这种情况我们一般称之为:过拟合,也就是上图中的第三种状态.
出现过拟合的原因一般有两种:
1.训练数据中存在噪音
2.训练数据太少
(三).过拟合的处理方法
面对这种情况,我们处理的方法一般为:
1.丢弃一些不能帮助我们正确与预测的特征,可以的手工选择保留哪些特征,也可以用一些模型选择的算法来帮助我们进行选择,如PCA
2.正则化,即保留所有特征,但是会减小参数的大小(magnitude)
J
(
θ
)
=
1
2
m
[
∑
i
=
1
m
(
h
θ
(
x
i
)
−
y
i
)
2
+
λ
∑
j
=
1
n
θ
j
2
]
J(\theta )=\frac{1}{2m}[\sum_{i=1}^{m}(h_{\theta }(x^{i})-y^{i})^{2}+\lambda \sum_{j=1}^{n}\theta _{j}^{2}]
J(θ)=2m1[i=1∑m(hθ(xi)−yi)2+λj=1∑nθj2]
修改后:
m
i
n
θ
⋅
1
2
m
[
∑
i
=
1
m
(
h
θ
(
x
i
)
−
y
i
)
2
+
1000
θ
3
2
+
10000
θ
4
2
]
min\theta \cdot \frac{1}{2m}[\sum_{i=1}^{m}(h_{\theta }(x^{i})-y^{i})^{2}+1000\theta _{3}^{2}+10000\theta _{4}^{2}]
minθ⋅2m1[i=1∑m(hθ(xi)−yi)2+1000θ32+10000θ42]
通过代价函数选出的θ3和θ4对预测结果的影响则比之前小很多
带正则化项的参数更新公式:
θ
j
:
=
θ
j
−
α
[
1
m
∑
i
=
1
m
(
h
θ
(
x
i
)
−
y
i
)
x
j
i
+
λ
m
θ
j
]
\theta _{j}:= \theta _{j}-\alpha [ \frac{1}{m}\sum_{i=1}^{m}(h_{\theta }(x^{i})-y^{i})x_{j}^{i}+\frac{\lambda }{m}\theta _{j}]
θj:=θj−α[m1i=1∑m(hθ(xi)−yi)xji+mλθj]
正则化的两种形式:
L1正则化:
J
(
θ
)
=
1
2
m
[
∑
i
=
1
m
(
h
θ
(
x
i
)
−
y
i
)
2
+
λ
∑
j
=
1
n
θ
j
2
]
−
−
−
−
L
a
s
s
o
J(\theta )=\frac{1}{2m}[\sum_{i=1}^{m}(h_{\theta }(x^{i})-y^{i})^{2}+\lambda \sum_{j=1}^{n}\theta _{j}^{2}] ----Lasso
J(θ)=2m1[i=1∑m(hθ(xi)−yi)2+λj=1∑nθj2]−−−−Lasso
L2正则化:
J
(
θ
)
=
1
2
m
[
∑
i
=
1
m
(
h
θ
(
x
i
)
−
y
i
)
2
+
λ
∑
j
=
1
n
∣
θ
j
∣
]
−
−
−
−
R
i
d
g
e
岭
回
归
J(\theta )=\frac{1}{2m}[\sum_{i=1}^{m}(h_{\theta }(x^{i})-y^{i})^{2}+\lambda \sum_{j=1}^{n}|\theta _{j}|] ----Ridge 岭回归
J(θ)=2m1[i=1∑m(hθ(xi)−yi)2+λj=1∑n∣θj∣]−−−−Ridge岭回归
两正则化的区别:
1.L1是模型各个参数的绝对值之和.
2.L2是模型各个参数的平方和的开方值.
3.L1会趋向于产生少量的特征,而其他的特征都是0,因为最优的参数值很大概率出现在坐标轴上,这样就会导致某一维的权重为0,产生稀疏权重矩阵
4.L2会选择更多的特征,这些特征都会接近于0,最优的参数值很小概率出现在坐标轴上,因此每一维的参数都不会是0,档最小化||w||时,就会使每一项趋近于0.
(四).拟合评估
1.是否过拟合:
在知道了如何处理过拟合之后,那么我们如何来评估我们的假设函数是否过拟合呢?
我们可以用交叉验证集来解决这个问题,帮助选择模型,即60%数据作为训练集,20%数据作为交叉验证集,剩余的20%作为测试集,需要注意的是,此处的百分比仅供参考,具体使用时可以根据自己的数据量进行调整,若数据集比较大或很大时,可以增大训练集的比例,同时降低交叉验证集和测试集的百分比.
比较重要的一点是:在进行数据选取时,我们通常会进行数据’洗牌’,这样做的目的是使三种不同的数据集都包含不同类型的数据,即整体数据中不同类型的数据需要出现在每个数据集合中.
在sklearn中,我们借助的是train_test_split(random_state=x)来对数据进行洗牌并划分数据集.
2.评估拟合程度
在知道假设函数没有过拟合或欠拟合的情况下,我们再来学习一下如何评估假设函数的拟合程度吧
我们都知道,假设空间是包含很多个模型的,在众多模型中,表现不理想模型的情况大致有两种:
1.偏差比较大,即欠拟合
2.方差比较大,即过拟合
对此,我们可以借助学习曲线来查看模型的拟合情况
(五).学习曲线
学习曲线(Learning curve):
如果有10000行数据,我们从1行数据开始,逐渐学习更多行的数据.
方法:数据集的大小为横轴,训练误差为纵轴,绘制训练集曲线和验证集曲线
结果:当训练较少行数据的时候,训练的模型将能够非常完美地适应较少的训练数据,那么训练集的误差很小,但是训练出来的模型却不能很好地适应交叉验证集数据或测试集数据,反应到学习曲线上的结果就是验证集的误差较大.
随着数据集的增长,训练集的误差会增大,验证集的误差会减小,直至收敛
训练集,交叉验证集,测试集的学习曲线函数分别为:
Training error (训练集错误)
J
t
r
a
i
n
(
θ
)
=
1
2
m
∑
i
=
1
m
(
h
θ
(
x
i
)
−
y
i
)
2
J_{train}(\theta)= \frac{1}{2m}\sum_{i=1}^{m}(h_{\theta }(x^{i})-y^{i})^{2}
Jtrain(θ)=2m1i=1∑m(hθ(xi)−yi)2
Cross Validation error(交叉验证集错误)
J
c
v
(
θ
)
=
1
2
m
c
v
∑
i
=
1
m
(
h
θ
(
x
c
v
i
)
−
y
c
v
i
)
2
J_{cv}(\theta)= \frac{1}{2m_{cv}}\sum_{i=1}^{m}(h_{\theta }(x_{cv}^{i})-y_{cv}^{i})^{2}
Jcv(θ)=2mcv1i=1∑m(hθ(xcvi)−ycvi)2
Test error(测试集错误)
J
t
e
s
t
(
θ
)
=
1
2
m
t
e
s
t
∑
i
=
1
m
t
e
s
t
(
h
θ
(
x
c
v
i
)
−
y
c
v
i
)
2
J_{test}(\theta)= \frac{1}{2m_{test}}\sum_{i=1}^{m_{test}}(h_{\theta }(x_{cv}^{i})-y_{cv}^{i})^{2}
Jtest(θ)=2mtest1i=1∑mtest(hθ(xcvi)−ycvi)2
二.代码实现
在了解了相关概念之后,我们再一起来用代码实现一下:
首先,惯例,导包和设置存储地址,这里就不多赘述了.
接着再创建一组数据
m = 100
X = 6* np.random.rand(m,1) - 3
y = 0.5 * X **2 + X + 2 + np.random.randn(m,1)
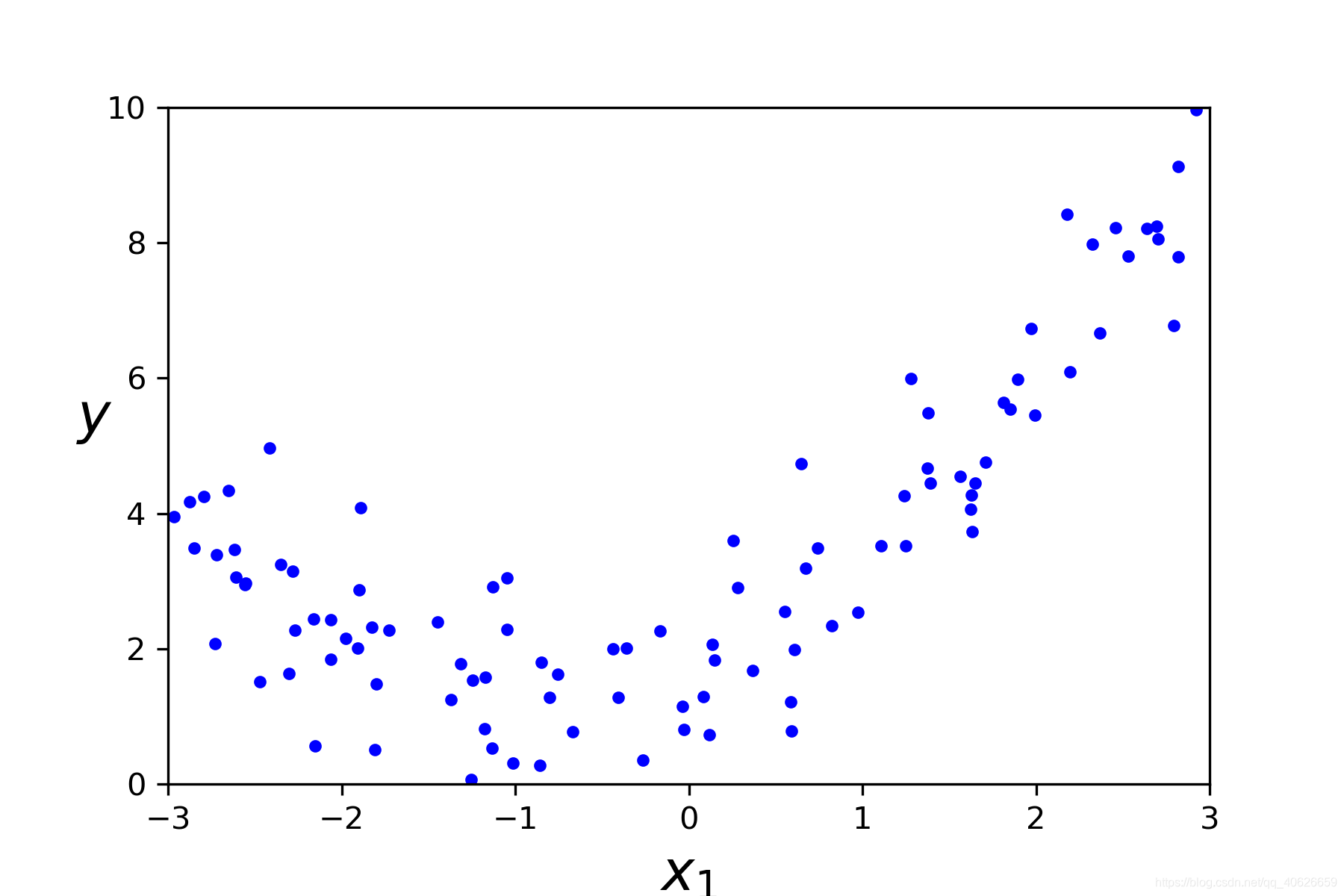
绘制出原数据的图形来看一下原数据的形状:
plt.plot(X,y,'b.')
plt.xlabel('$x_1$',fontsize=18)
plt.ylabel('$y$',rotation = 0,fontsize = 18)
plt.axis([-3,3,0,10])
save_fig('quadratic_data_plot')
plt.show()
(一).导包绘制
导入另外两个包
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import LinearRegression
创建特征值和特征向量
poly_features = PolynomialFeatures(degree=2,include_bias=False)
X_poly = poly_features.fit_transform(X)
poly_features
PolynomialFeatures(degree=2, include_bias=False, interaction_only=False,order='C')
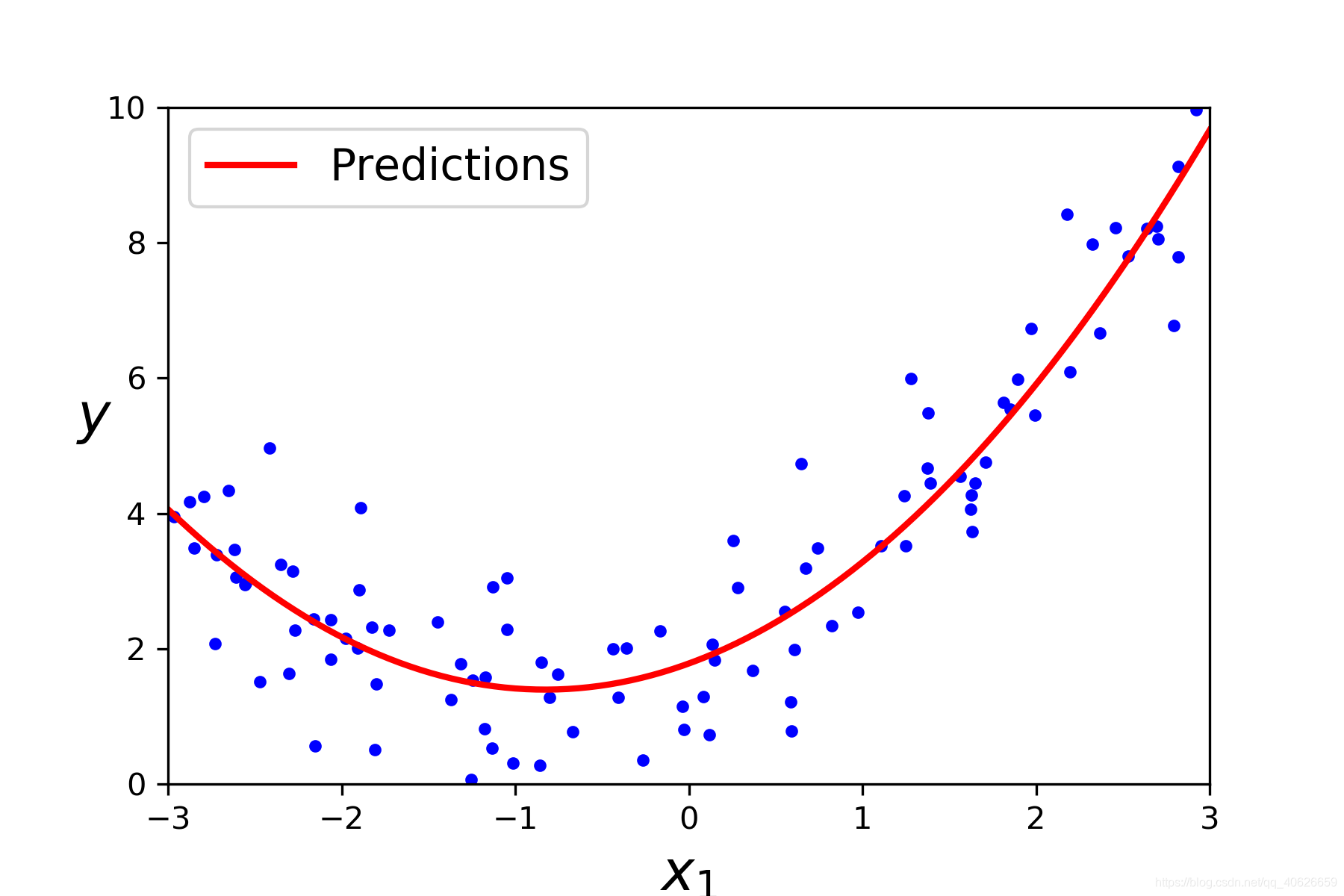
绘制模型
lin_reg = LinearRegression() # 初始化一个线性分类器
lin_reg.fit(X_poly,y) # 分类器拟合多项特征
lin_reg.intercept_,lin_reg.coef_ # 获取参数
X_new = np.linspace(-3,3,100).reshape(100,1)
X_new_poly = poly_features.transform(X_new)
y_new = lin_reg.predict(X_new_poly)
plt.plot(X,y,'b.')
plt.plot(X_new,y_new,'r-',linewidth=2,label='Predictions')
plt.xlabel('$x_1$',fontsize=18)
plt.ylabel('$y$',rotation=0,fontsize=18)
plt.legend(loc='upper left',fontsize=14)
plt.axis([-3,3,0,10])
save_fig('quadratic_predictions_plot')
plt.show()
最终绘制效果:
(二).手写代码实现拟合曲线
from sklearn.preprocessing import StandardScaler # 从预处理包里导入标准化处理模块
from sklearn.preprocessing import MinMaxScaler # 导入归一化处理模块
from sklearn.pipeline import Pipeline # 导入流水线处理模块
for style,width,degree in (('g-',1,300),('b--',2,2),('r-+',2,1)): #遍历三种画图方式
polybig_features = PolynomialFeatures(degree=degree,include_bias=False) #初始化多项式特征对象
std_scaler = StandardScaler() # 数据标准化
mm_scaler = MinMaxScaler()
lin_reg = LinearRegression() # 初始化线性分类器
polynomial_regression = Pipeline([
('poly_features',polybig_features), # pipeline第一步 处理特征
('std_scaler',std_scaler), # 标准化数据
('lin_reg',lin_reg), # 初始化线性回归器
])
polynomial_regression.fit(X,y) # 训练模型
y_newbig = polynomial_regression.predict(X_new) # 预测数据
plt.plot(X_new,y_newbig,style,label=str(degree),linewidth=width) # 画拟合好的3个曲线中的一个
plt.plot(X,y,'b.',linewidth=3) # 画原始数据点
plt.legend(loc='upper left')
plt.xlabel('$x_1$',fontsize=18)
plt.ylabel('$y$',rotation=0,fontsize=18)
plt.axis([-3,3,0,10])
save_fig('high_degree_polynomials_plot')
plt.show()
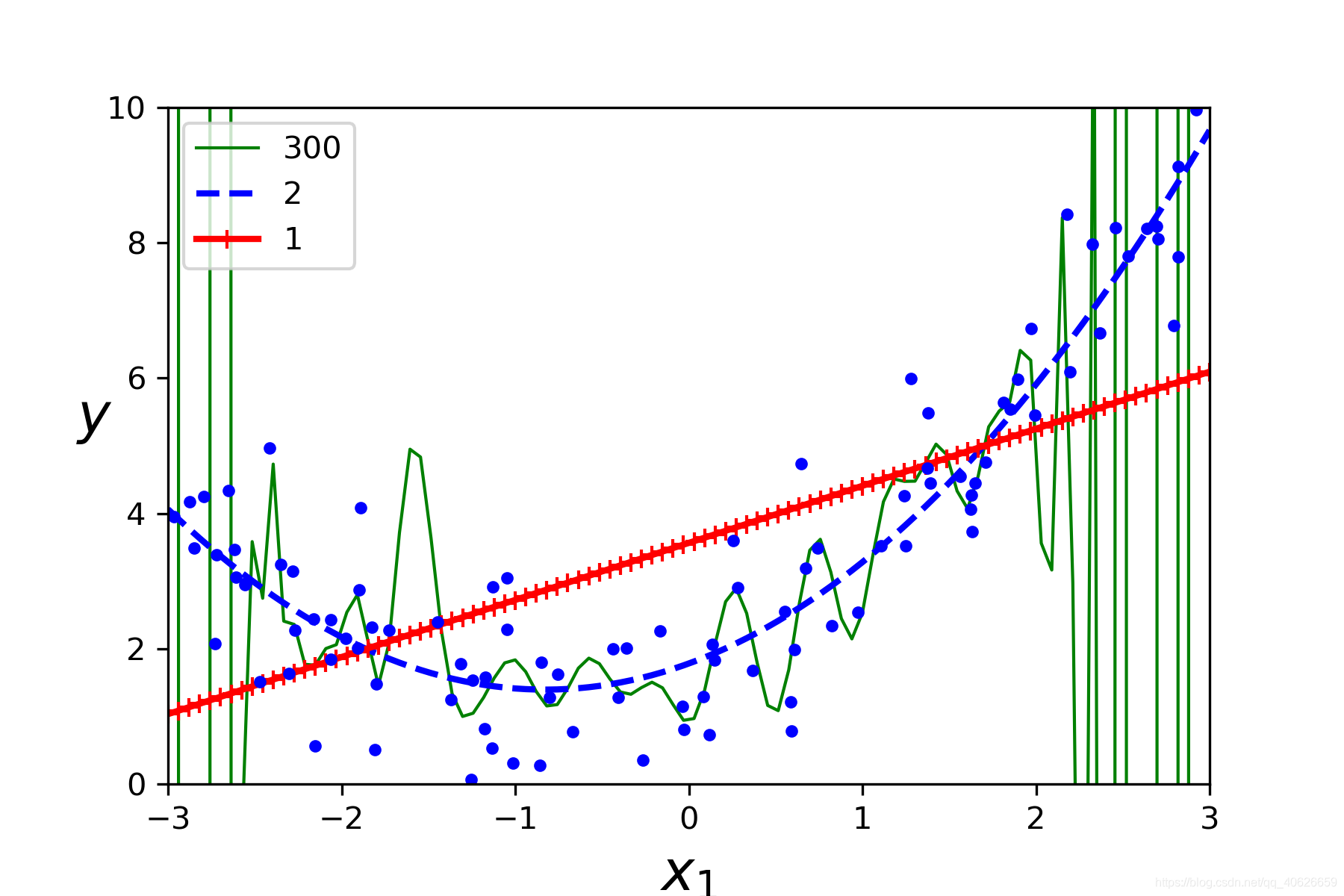
我们绘制了三种图形,分别是欠拟合,过拟合,和较好模型,
如下图的结果所示:
红色为欠拟合状态,
绿色为过拟合状态,线上包含所有初始值,
而蓝色则为较好拟合状态,能较好地反映出原始数据的趋势并拟合新数据
接着我们再定义函数
from sklearn.metrics import mean_squared_error # 从度量包里导入均方误差的度量模块
from sklearn.model_selection import train_test_split # 从模型选择包导入数据集切分模块
def plot_learning_curves(model,X,y):
X_train,X_val,y_train,y_val = train_test_split(X,y,test_size = 0.2,random_state=10) # 切分数据集,训练集80%,验证集20%,指定随机种子
train_errors = [] # 收集训练误差
val_errors = [] # 收集验证误差
for m in range(1,len(X_train)): # 遍历训练集数据
model.fit(X_train[:m],y_train[:m]) # 拟合数据
y_train_predict = model.predict(X_train[:m]) # 预测训练集的值
y_val_predict = model.predict(X_val) # 预测验证集的值
train_errors.append(mean_squared_error(y_train[:m],y_train_predict)) # 计算真实值和训练值之间的均方误差并收集
val_errors.append(mean_squared_error(y_val,y_val_predict)) # 计算真实值和验证集预测值之间的均方误差并收集
plt.plot(np.sqrt(train_errors),'r-+',linewidth=2,label='train')
plt.plot(np.sqrt(val_errors),'b-',linewidth=3,label='val')
plt.legend(loc='upper right',fontsize=14)
plt.xlabel('Training set size',fontsize=14)
plt.ylabel('RMSE',fontsize=14)
调用函数绘制曲线
lin_reg = LinearRegression() # 初始化线性回归器
plot_learning_curves(lin_reg,X,y) # 调用函数
plt.axis([0,80,0,3])
save_fig('underfitting_learning_curves_plot')
plt.show()
最终结果:
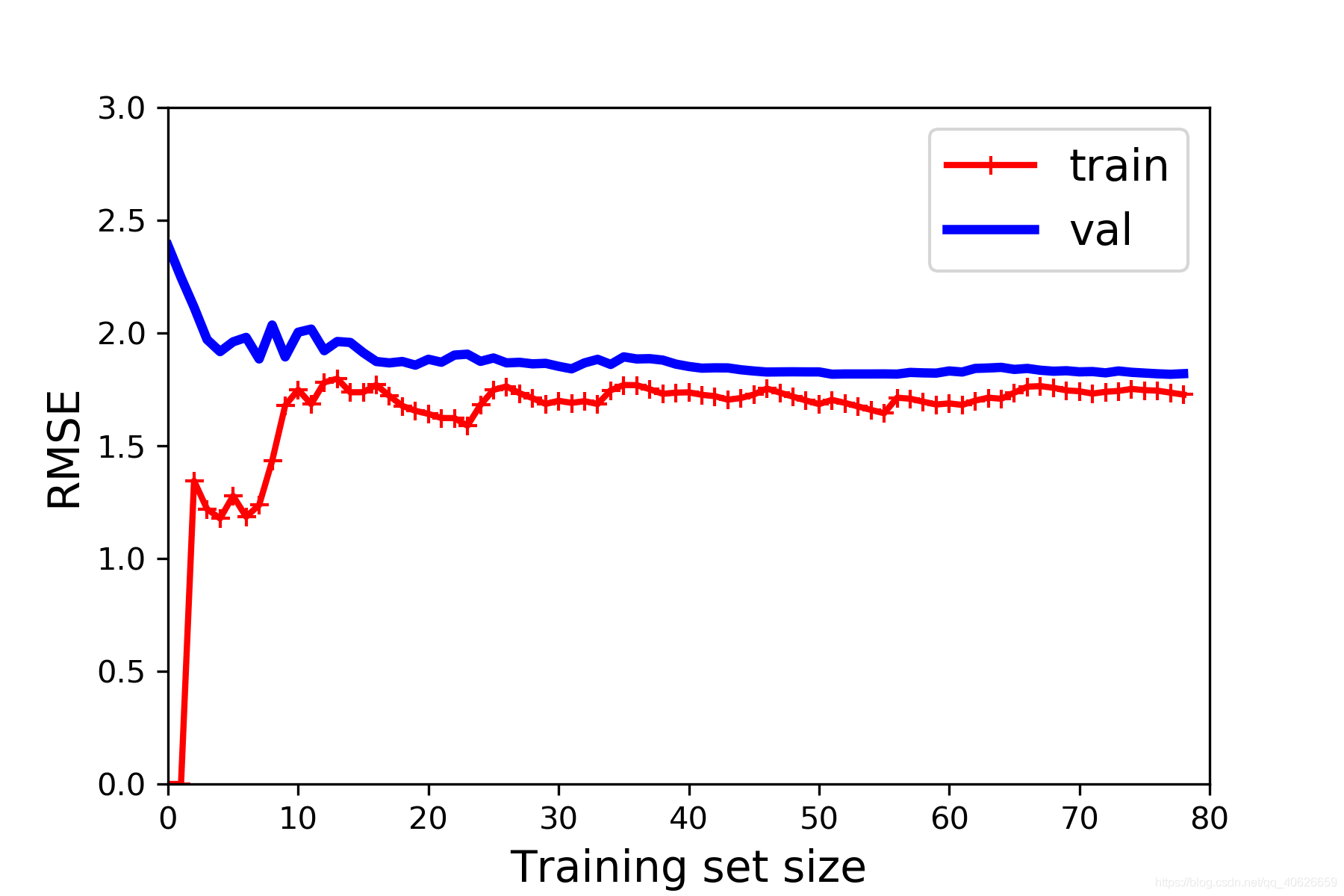
从上图,我们便可以借助训练集和验证集的拟合程度,来评估我们绘制出的假设函数是否拟合.
总结:
为了能够更好地拟合数据的模型,我们采取了正则化的形式,通过减小参数的大小保留了数据的所有特征,之后选取了交叉验证集来帮助选择模型,选出后借用学习曲线查看拟合的模型,评估假设函数拟合程度,这些便是以上内容的过程总结了.
此外我们再来补充几个零散的概念:
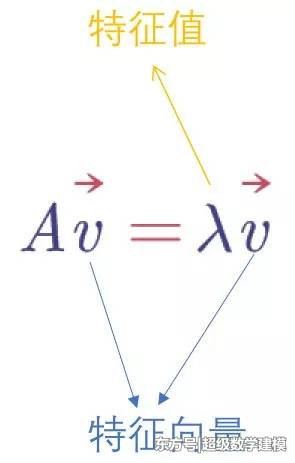
简而言之:特征值就是运动的速度,特征向量就是运动的方向.
此处借用网上一张图借以说明,出处见图右下角

















 1105
1105

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









