










 本文介绍了使用Pytorch实现的Seq2Seq-Attention结构,涵盖了数据处理模块,包括从平行语料库下载和繁体到简体的转换;模型结构模块,定义了Encoder-RNN和AttenDecoderRNN;以及训练模块,涉及编码器、解码器的训练和评估。
本文介绍了使用Pytorch实现的Seq2Seq-Attention结构,涵盖了数据处理模块,包括从平行语料库下载和繁体到简体的转换;模型结构模块,定义了Encoder-RNN和AttenDecoderRNN;以及训练模块,涉及编码器、解码器的训练和评估。
使用Pytorch框架:
使用Seq2Seq-Attention结构

数据处理模块
数据资源下载:平行语料库
- http://www.manythings.org/anki

首先下载的数据集中有繁体,我们在github上找到一个模型(langconv.py)来处理繁体,将繁体转换成简体
langconv.py
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from copy import deepcopy
import re
try:
import psyco
psyco.full()
except:
pass
try:
from zh_wiki import zh2Hant, zh2Hans
except ImportError:
from zhtools.zh_wiki import zh2Hant, zh2Hans
import sys
py3k = sys.version_info >= (3, 0, 0)
if py3k:
UEMPTY = ''
else:
_zh2Hant, _zh2Hans = {}, {}
for old, new in ((zh2Hant, _zh2Hant), (zh2Hans, _zh2Hans)):
for k, v in old.items():
new[k.decode('utf8')] = v.decode('utf8')
zh2Hant = _zh2Hant
zh2Hans = _zh2Hans
UEMPTY = ''.decode('utf8')
# states
(START, END, FAIL, WAIT_TAIL) = list(range(4))
# conditions
(TAIL, ERROR, MATCHED_SWITCH, UNMATCHED_SWITCH, CONNECTOR) = list(range(5))
MAPS = {}
class Node(object):
def __init__(self, from_word, to_word=None, is_tail=True,
have_child=False):
self.from_word = from_word
if to_word is None:
self.to_word = from_word
self.data = (is_tail, have_child, from_word)
self.is_original = True
else:
self.to_word = to_word or from_word
self.data = (is_tail, have_child, to_word)
self.is_original = False
self.is_tail = is_tail
self.have_child = have_child
def is_original_long_word(self):
return self.is_original and len(self.from_word)>1
def is_follow(self, chars):
return chars != self.from_word[:-1]
def __str__(self):
return '<Node, %s, %s, %s, %s>' % (repr(self.from_word),
repr(self.to_word), self.is_tail, self.have_child)
__repr__ = __str__
class ConvertMap(object):
def __init__(self, name, mapping=None):
self.name = name
self._map = {}
if mapping:
self.set_convert_map(mapping)
def set_convert_map(self, mapping):
convert_map = {}
have_child = {}
max_key_length = 0
for key in sorted(mapping.keys()):
if len(key)>1:
for i in range(1, len(key)):
parent_key = key[:i]
have_child[parent_key] = True
have_child[key] = False
max_key_length = max(max_key_length, len(key))
for key in sorted(have_child.keys()):
convert_map[key] = (key in mapping, have_child[key],
mapping.get(key, UEMPTY))
self._map = convert_map
self.max_key_length = max_key_length
def __getitem__(self, k):
try:
is_tail, have_child, to_word = self._map[k]
return Node(k, to_word, is_tail, have_child)
except:
return Node(k)
def __contains__(self, k):
return k in self._map
def __len__(self):
return len(self._map)
class StatesMachineException(Exception): pass
class StatesMachine(object):
def __init__(self):
self.state = START
self.final = UEMPTY
self.len = 0
self.pool = UEMPTY
def clone(self, pool):
new = deepcopy(self)
new.state = WAIT_TAIL
new.pool = pool
return new
def feed(self, char, map):
node = map[self.pool+char]
if node.have_child:
if node.is_tail:
if node.is_original:
cond = UNMATCHED_SWITCH
else:
cond = MATCHED_SWITCH
else:
cond = CONNECTOR
else:
if node.is_tail:
cond = TAIL
else:
cond = ERROR
new = None
if cond == ERROR:
self.state = FAIL
elif cond == TAIL:
if self.state == WAIT_TAIL and node.is_original_long_word():
self.state = FAIL
else:
self.final += node.to_word
self.len += 1
self.pool = UEMPTY
self.state = END
elif self.state == START or self.state == WAIT_TAIL:
if cond == MATCHED_SWITCH:
new = self.clone(node.from_word)
self.final += node.to_word
self.len += 1
self.state = END
self.pool = UEMPTY
elif cond == UNMATCHED_SWITCH or cond == CONNECTOR:
if self.state == START:
new = self.clone(node.from_word)
self.final += node.to_word
self.len += 1
self.state = END
else:
if node.is_follow(self.pool):
self.state = FAIL
else:
self.pool = node.from_word
elif self.state == END:
# END is a new START
self.state = START
new = self.feed(char, map)
elif self.state == FAIL:
raise StatesMachineException('Translate States Machine '
'have error with input data %s' % node)
return new
def __len__(self):
return self.len + 1
def __str__(self):
return '<StatesMachine %s, pool: "%s", state: %s, final: %s>' % (
id(self), self.pool, self.state, self.final)
__repr__ = __str__
class Converter(object):
def __init__(self, to_encoding):
self.to_encoding = to_encoding
self.map = MAPS[to_encoding]
self.start()
def feed(self, char):
branches = []
for fsm in self.machines:
new = fsm.feed(char, self.map)
if new:
branches.append(new)
if branches:
self.machines.extend(branches)
self.machines = [fsm for fsm in self.machines if fsm.state != FAIL]
all_ok = True
for fsm in self.machines:
if fsm.state != END:
all_ok = False
if all_ok:
self._clean()
return self.get_result()
def _clean(self):
if len(self.machines):
self.machines.sort(key=lambda x: len(x))
# self.machines.sort(cmp=lambda x,y: cmp(len(x), len(y)))
self.final += self.machines[0].final
self.machines = [StatesMachine()]
def start(self):
self.machines = [StatesMachine()]
self.final = UEMPTY
def end(self):
self.machines = [fsm for fsm in self.machines
if fsm.state == FAIL or fsm.state == END]
self._clean()
def convert(self, string):
self.start()
for char in string:
self.feed(char)
self.end()
return self.get_result()
def get_result(self):
return self.final
def registery(name, mapping):
global MAPS
MAPS[name] = ConvertMap(name, mapping)
registery('zh-hant', zh2Hant)
registery('zh-hans', zh2Hans)
del zh2Hant, zh2Hans
def run():
import sys
from optparse import OptionParser
parser = OptionParser()
parser.add_option('-e', type='string', dest='encoding',
help='encoding')
parser.add_option('-f', type='string', dest='file_in',
help='input file (- for stdin)')
parser.add_option('-t', type='string', dest='file_out',
help='output file')
(options, args) = parser.parse_args()
if not options.encoding:
parser.error('encoding must be set')
if options.file_in:
if options.file_in == '-':
file_in = sys.stdin
else:
file_in = open(options.file_in)
else:
file_in = sys.stdin
if options.file_out:
if options.file_out == '-':
file_out = sys.stdout
else:
file_out = open(options.file_out, 'wb')
else:
file_out = sys.stdout
c = Converter(options.encoding)
for line in file_in:
# print >> file_out, c.convert(line.rstrip('\n').decode(
file_out.write(c.convert(line.rstrip('\n').decode(
'utf8')).encode('utf8'))
if __name__ == '__main__':
run()
zn_wiki.py
一个简繁体转换的语料库,太长了就不显示全了
# -*- coding: utf-8 -*-
# copy fom wikipedia
zh2Hant = {
'呆': '獃',
"打印机": "印表機",
'帮助文件': '說明檔案',
"画": "畫",
"龙": "竜",
·····
"散紙": "散钱",
"笑星": "谐星",
"夜校": "夜学",
"民乐": "华乐",
"住房": "住屋",
"房价": "屋价",
"泡麵": "快速面",
}
工具类utils.py
import matplotlib.pyplot as plt
plt.switch_backend('agg')
import matplotlib.ticker as ticker
import time
import math
import unicodedata
import string
import re
from langconv import *
# Turn a Unicode string to plain ASCII, thanks to
# http://stackoverflow.com/a/518232/2809427
def unicode2Ascii(s):
return ''.join(
c for c in unicodedata.normalize('NFD', s)
if unicodedata.category(c) != 'Mn'
)
def normalizeString(s):
'''
# Lowercase, trim, and remove non-letter characters
:param s:
:return:
'''
s = unicode2Ascii(s.lower().strip())
s = re.sub(r"([.!?])", r" \1", s)
s = re.sub(r"[^a-zA-Z.!?]+", r" ", s)
return s
def cht_to_chs(line):
line = Converter('zh-hans').convert(line)
line.encode('utf-8')
return line
def asMinutes(s):
m = math.floor(s / 60)
s -= m * 60
return '%dm %ds' % (m, s)
def timeSince(since, percent):
now = time.time()
s = now - since
es = s / (percent)
rs = es - s
return '%s (- %s)' % (asMinutes(s), asMinutes(rs))
def showPlot(points):
plt.figure()
fig, ax = plt.subplots()
# this locator puts ticks at regular intervals
loc = ticker.MultipleLocator(base=0.2)
ax.yaxis.set_major_locator(loc)
plt.plot(points)
datasets.py
提取出中文和英文作为语料对 统计字典
import jieba
from utils import normalizeString#字符串处理
from utils import cht_to_chs#繁体字转简体字
#提取出中文和英文作为语料对 统计字典
SOS_token = 0 #起始符和终止符
EOS_token = 1
MAX_LENGTH = 10
class Lang:
def __init__(self,name):
self.name = name
self.word2index = {} #对词语进行编码
self.word2cont = {} #统计字典中每个词出现的频率
self.index2word = { #索引对应的词
0:"SOS", 1:"EOS"
}
self.n_words = 2 #统计当前语料库中的单词数目
#用来对词进行统计,利用word更新字典值
def addWord(self,word):
if word not in self.word2index:
self.word2index[word] = self.n_words#给每个词一个索引值
self.word2cont[word] = 1
self.index2word[self.n_words] = word
self.n_words +=1
else:
self.word2cont[word] +=1
#用来分词
def addSentence(self,sentence):
for word in sentence.split(" "):
self.addWord(word)
#文本解析
def readLangs(lang1, lang2, path):
lines = open(path,encoding="utf-8").readlines()
lang1_cls = Lang(lang1)
lang2_cls = Lang(lang2)
pairs = []
for l in lines:
l = l.split("\t")
sentence1 = normalizeString(l[0]) #英文
sentence2 = cht_to_chs(l[1]) #中文
seg_list = jieba.cut(sentence2, cut_all=False) #分词结果
sentence2 = " ".join(seg_list) #通过空格拼接分词结果
if len(sentence1.split(" ")) > MAX_LENGTH: #过滤长句子
continue
if len(sentence2.split(" ")) > MAX_LENGTH:
continue
pairs.append([sentence1, sentence2])
lang1_cls.addSentence(sentence1)
lang2_cls.addSentence(sentence2)
return lang1_cls, lang2_cls, pairs
lang1 = "en"
lang2 = "cn"
path = "data/en-cn.txt"
lang1_cls, lang2_cls, pairs = readLangs(lang1, lang2, path)
print(len(pairs))
print(lang1_cls.n_words)
print(lang1_cls.index2word)
print(lang2_cls.n_words)
print(lang2_cls.index2word)
运行结果:

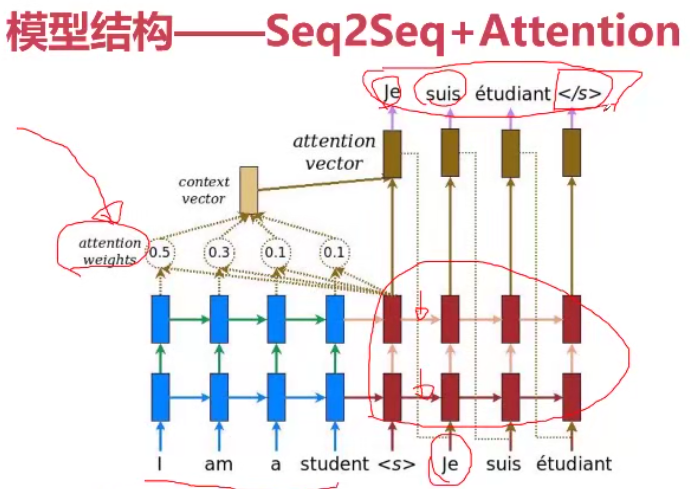
定义模型结构模块
import torch
import torch.nn as nn
import torch.nn.functional as F
from datasets import MAX_LENGTH
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
#编码模块
class EncoderRNN(nn.Module):
def __init__(self, input_size, hidden_size):
super(EncoderRNN, self).__init__()
self.hidden_size = hidden_size
self.embedding = nn.Embedding(input_size, hidden_size)#输入句子的长度,输出编码成词向量的长度
self.gru = nn.GRU(hidden_size, hidden_size)#词向量长度 也可以选择lstm
def forward(self, input, hidden):
embedded = self.embedding(input).view(1, 1, -1)#将编码后的维度传入到最后一个维度上去
output = embedded
output, hidden = self.gru(output,hidden)
return output,hidden #返回gru输出的结果和隐藏层信息
def initHidden(self): #在第一个节点上定义一个默认的隐藏层
return torch.zeros(1, 1, self.hidden_size, device=device)
#解码模块 1.不带attention的结构 2.带attention的结构
class DecoderRNN(nn.Module):
def __init__(self, hidden_size, output_size):
super(DecoderRNN, self).__init__()
self.embedding = nn.Embedding(output_size,hidden_size)
self.gru = nn.GRU(hidden_size, hidden_size)
self.out = nn.Linear(hidden_size, output_size)
self.softmax = nn.Softmax(dim=1)
def forward(self,input, hidden):
output = self.embedding(input).view(1,1,-1)
output = F.relu(output)
output, hidden = self.gru(output, hidden)
output = self.softmax(self.out(output[0]))
return output, hidden #类别的概率分布和隐藏层信息
def initHidden(self): #在第一个节点上定义一个默认的隐藏层
return torch.zeros(1, 1, self.hidden_size, device=device)
#基于attention的解码结构
class AttenDecoderRNN(nn.Module):
def __init__(self, hidden_size, output_size, dropout_p=0.1, max_len=MAX_LENGTH):
super(AttenDecoderRNN, self).__init__()
self.hidden_size = hidden_size
self.output_size = output_size
self.dropout_p = dropout_p
self.max_len = max_len
self.embedding = nn.Embedding(self.output_size, self.hidden_size)
self.attn = nn.Linear(self.hidden_size * 2, self.max_len)#要对两个结果进行连接,因此要乘以2
self.attn_combine = nn.Linear(self.hidden_size *2, self.hidden_size)
self.dropout = nn.Dropout(self.dropout_p)
self.gru = nn.GRU(self.hidden_size,self.hidden_size)
self.out = nn.Linear(self.hidden_size, self.output_size)
def forward(self,input, hidden, encoder_outputs):
embedded = self.embedding(input).view(1, 1, -1)#对输入进行特征抽取转化为词向量
embedded = self.dropout(embedded)
atten_weight = F.softmax(
self.attn(torch.cat([embedded[0], hidden[0]], 1)), #将embedded和hidden进行拼接,来学习attention权重
dim=1
)
att_applied = torch.bmm( #计算两个tensor的矩阵乘法
atten_weight.unsqueeze(0),#取出权重
encoder_outputs.unsqueeze(0)
) #将权重作用到feature上
output = torch.cat([embedded[0],att_applied[0]], dim=1)
output = self.attn_combine(output).unsqueeze(0)
output = F.relu(output)#加入非线性信息
output, hidden = self.gru(output, hidden)
output = F.log_softmax(self.out(output[0]), dim=1)
return output, hidden, atten_weight
def initHidden(self): #在第一个节点上定义一个默认的隐藏层
return torch.zeros(1, 1, self.hidden_size, device=device)
if __name__ == '__main__':
encoder_net = EncoderRNN(5000, 256)
decoder_net = DecoderRNN(256, 5000)
atten_decoder_net = AttenDecoderRNN(256, 5000)
tensor_in = torch.tensor([12, 14, 16, 18], dtype=torch.long).view(-1, 1)#定义输入并调整shape
hidden_in = torch.zeros(1, 1, 256)
#测试编码网络
encoder_out, encoder_hidden = encoder_net(tensor_in[0], hidden_in)
print(encoder_out)
print(encoder_hidden)
#测试解码网络
tensor_in = torch.tensor([100])
hidden_in = torch.zeros(1, 1, 256)
encoder_out = torch.zeros(10,256) #第一维大小取决于MAX_LENGTH,此处为10
out1, out2, out3 = atten_decoder_net(tensor_in, hidden_in, encoder_out)
print(out1, out2, out3)
out1, out2 = decoder_net(tensor_in,hidden_in)
print(out1,out2)
定义训练模块
import random
import time
import torch
import torch.nn as nn
from torch import optim
from datasets import readLangs, SOS_token, EOS_token, MAX_LENGTH
from models import EncoderRNN, AttenDecoderRNN
from utils import timeSince
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
MAX_LENGTH += 1 #添加了终止符
lang1 = "en"
lang2 = "cn"
path = "data/en-cn.txt"
input_lang, output_lang, pairs = readLangs(lang1, lang2, path)
print(len(pairs))
print(input_lang.n_words)
print(input_lang.index2word)
print(output_lang.n_words)
print(output_lang.index2word)
def listTotensor(input_lang, data):
indexes_in = [input_lang.word2index[word] for word in data.split(" ")]
indexes_in.append(EOS_token)
input_tensor = torch.tensor(indexes_in,
dtype=torch.long,
device=device).view(-1, 1)
return input_tensor
#把pairs下的序列转换为输入tensor,并在tensor中插入一个终止符
def tensorsFromPair(pair):
input_tensor = listTotensor(input_lang, pair[0])
output_tensor = listTotensor(output_lang, pair[1])
return (input_tensor, output_tensor)
def loss_func(input_tensor, output_tensor, encoder, decoder,
encoder_optimizer, decoder_optimizer,criterion):
encoder_hidden = encoder.initHidden()#初始化隐藏层
encoder_optimizer.zero_grad()#优化器梯度置零
decoder_optimizer.zero_grad()
input_len = input_tensor.size(0)#输入输出长度
output_len = output_tensor.size(0)
encoder_outputs = torch.zeros(MAX_LENGTH, encoder.hidden_size, device=device)
#每次从input_tensor中取一个出来利用隐藏层信息进行encoder
for ei in range(input_len):
encoder_output, encoder_hidden = encoder(input_tensor[ei], encoder_hidden)
encoder_outputs[ei] = encoder_output[0, 0]#编码结果
decoder_hidden = encoder_hidden
decoder_input = torch.tensor([[SOS_token]], device=device)#第一个解码输入定义为起始符SOS_token
#加入随机因子,随机修改当前隐藏层的输入为真实的label
use_teacher_forcing = True if random.random() < 0.5 else False
loss = 0
if use_teacher_forcing:
for di in range(output_len):
decoder_output, decoder_hidden, decoder_attention = decoder(
decoder_input, decoder_hidden, encoder_outputs
)
loss += criterion(decoder_output, output_tensor[di])
decoder_input = output_tensor[di] #下一次循环的输入直接定义为真实的label
else:
for di in range(output_len):
decoder_output, decoder_hidden, decoder_attention = decoder(
decoder_input, decoder_hidden, encoder_outputs
)
loss += criterion(decoder_output, output_tensor[di])
#定义下一次的输入为当前的预测结果
topV, topi = decoder_output.topk(1)
decoder_input = topi.squeeze().detach()
# 判断解码是否结束
if decoder_input.item() == EOS_token:
break
loss.backward() #梯度传播
encoder_optimizer.step()
decoder_optimizer.step()
return loss.item() / output_len
hidden_size = 256
encoder = EncoderRNN(input_lang.n_words, hidden_size).to(device)
decoder = AttenDecoderRNN(hidden_size, output_lang.n_words,
max_len = MAX_LENGTH,
dropout_p=0.1).to(device)
lr = 0.01
encoder_optimizer = optim.SGD(encoder.parameters(), lr=lr)
decoder_optimizer = optim.SGD(decoder.parameters(), lr=lr)
#设置学习率调整
scheduler_encoder = torch.optim.lr_scheduler.StepLR(encoder_optimizer,
step_size=1,
gamma=0.95)
scheduler_decoder = torch.optim.lr_scheduler.StepLR(decoder_optimizer,
step_size=1,
gamma=0.95)
criterion = nn.NLLLoss()
#生成样本对
n_iters = 1000000
training_pairs = [
tensorsFromPair(random.choice(pairs))for i in range(n_iters)
]
print_every = 100
save_every = 1000
print_loss_total = 0
start = time.time()
for iter in range(1, n_iters+1):
training_pair = training_pairs[iter - 1]
input_tensor = training_pair[0]
output_tensor = training_pair[1]
loss = loss_func(input_tensor,
output_tensor,
encoder,
decoder,
encoder_optimizer,
decoder_optimizer,
scheduler_encoder,
scheduler_decoder,
criterion)
print_loss_total += loss
if iter % print_every == 0:
print_loss_avg = print_loss_total / print_every
print_loss_total = 0
print("{},{},{},{}".format(timeSince(start, iter/n_iters),
iter, iter / n_iters * 100,
print_loss_avg))
#保存模型
if iter % save_every == 0:
torch.save(encoder.state_dict(),
"models/encoder_{}.pth".format(iter))
torch.save(decoder.state_dict(),
"models/decoder_{}.pth".format(iter))
#更新学习率
if iter % 10000:
scheduler_encoder.step()
scheduler_decoder.step()
定义eval模块
利用训练好的模型进行推理计算
复用train.py的代码
去掉loss_func、学习率和优化器等部分代码
加载已经训练好的参数
import random
import torch
import torch.nn as nn
from torch import optim
from datasets import readLangs, SOS_token, EOS_token, MAX_LENGTH
from models import EncoderRNN, AttenDecoderRNN
from utils import timeSince
import time
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
MAX_LENGTH = MAX_LENGTH + 1
lang1 = "en"
lang2 = "cn"
path = "data/en-cn.txt"
input_lang, output_lang, pairs = readLangs(lang1, lang2, path)
print(len(pairs))
print(input_lang.n_words)
print(input_lang.index2word)
print(output_lang.n_words)
print(output_lang.index2word)
def listTotensor(input_lang, data):
indexes_in = [input_lang.word2index[word] for word in data.split(" ")]
indexes_in.append(EOS_token)
input_tensor = torch.tensor(indexes_in,
dtype=torch.long,
device=device).view(-1, 1)
return input_tensor
def tensorsFromPair(pair):
input_tensor = listTotensor(input_lang, pair[0])
output_tensor = listTotensor(output_lang, pair[1])
return (input_tensor, output_tensor)
hidden_size = 256
encoder = EncoderRNN(input_lang.n_words, hidden_size).to(device)
decoder = AttenDecoderRNN(hidden_size,
output_lang.n_words,
max_len = MAX_LENGTH,
dropout_p = 0.1).to(device)
#加载已经训练好的参数
encoder.load_state_dict(torch.load("models/encoder_1000000.pth"))
decoder.load_state_dict(torch.load("models/decoder_1000000.pth"))
n_iters = 10
train_sen_pairs = [
random.choice(pairs) for i in range(n_iters)
]
training_pairs = [
tensorsFromPair(train_sen_pairs[i]) for i in range(n_iters)
]
for i in range(n_iters):
input_tensor, output_tensor = training_pairs[i]
encoder_hidden = encoder.initHidden()
input_len = input_tensor.size(0)
encoder_outputs = torch.zeros(MAX_LENGTH, encoder.hidden_size, device=device)
for ei in range(input_len):
encoder_output, encoder_hidden = encoder(input_tensor[ei], encoder_hidden)
encoder_outputs[ei] = encoder_output[0, 0]
decoder_hidden = encoder_hidden
decoder_input = torch.tensor([[SOS_token]], device=device)
use_teacher_forcing = True if random.random() < 0.5 else False
decoder_words = []
for di in range(MAX_LENGTH):
decoder_output, decoder_hidden, decoder_attention = decoder(
decoder_input, decoder_hidden, encoder_outputs
)
topV, topi = decoder_output.topk(1)
decoder_input = topi.squeeze().detach()
#如果预测结果==终止符
if topi.item() == EOS_token:# 加入终止符
decoder_words.append("<EOS>")
break
else:#加入预测结果
decoder_words.append(output_lang.index2word[topi.item()])
print(train_sen_pairs[i][0]) #input
print(train_sen_pairs[i][1]) #output
print(decoder_words)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









