






网易云课堂课程链接:https://study.163.com/course/courseMain.htm?courseId=1211017803
文章目录
- 一、模板引擎 mustache
- 1.1 什么是模板引擎
- 1.2 数组join()介绍
- 1.3 反引号法
- 1.4 mustache的基本语法
- 1.5 正则表达式思路简介
- 1.6 底层tokens思想
- 1.7 手写实现mustache环境配置
- 1.8 手写实现Scanner类
- 1.9 手写将HTML变为tokens
- 1.10 手写将tokens嵌套起来
- 1.11 手写将tokens注入数据
- 1.12 手写lookup函数
- 二、虚拟DOM和Diff算法
- 2.1 snabbdom简介和测试环境搭建
- 2.2 虚拟DOM和h函数
- 2.3 手写h函数
- 2.4 感受Diff算法
- 2.5 diff处理新旧节点不是同一个节点时
- 2.6 手写第一次上树时
- 2.7 手写递归创建子节点
- 2.8 diff处理新旧节点是同一个节点时
- 2.9 手写新旧节点text的不同情况
- 2.10 尝试书写diff更新子节点(错误尝试,为了突出后续diff算法的优势)
- 2.11 diff算法的子节点更新策略
- 2.12 手写子节点更新策略
- 三、数据响应式原理
- 四、AST抽象语法树
- 五 指令和生命周期
一、模板引擎 mustache
1.1 什么是模板引擎
模板引擎是将数据要变为视图的解决方案。

- 纯DOM法:非常笨拙,没有实战价值
- 数组join法:曾经非常流行,是曾经的前端必会知识
- ES6反引号法:ES6中新增的`${a}`语法糖
模板引擎:解决数据变为视图的最优雅的方法
纯DOM法代码实现:
let arr = [
{ "name": "小赵", "age": 10, "sex": "男" },
{ "name": "小钱", "age": 11, "sex": "女" },
{ "name": "小孙", "age": 12, "sex": "男" }
]
let list = document.getElementById('list');
for (let i = 0; i < arr.length; i++) {
//每遍历一项,都要用DOM方法去创建li标签
let oLi = document.createElement('li');
//创建hd这个div
let hdDiv = document.createElement('div');
hdDiv.className = "hd";
hdDiv.innerText = arr[i].name + "的基本信息";
//创建bd这个div
let bdDiv = document.createElement('div');
bdDiv.className = "bd";
//创建三个p标签放在bdDiv里
let p1 = document.createElement('p');
p1.innerText = "姓名: " + arr[i].name;
let p2 = document.createElement('p');
p2.innerText = "年龄: " + arr[i].age;
let p3 = document.createElement('p');
p3.innerText = "性别: " + arr[i].sex;
//创建的节点是孤儿节点,所以必须要上树才能被用户看见
bdDiv.append(p1, p2, p3);
//创建的节点是孤儿节点,所以必须要上树才能被用户看见
oLi.append(hdDiv, bdDiv)
list.appendChild(oLi);
}
非常复杂,有很多DOM操作
1.2 数组join()介绍
let list = document.getElementById('list');
for (let i = 0; i < arr.length; i++) {
let oLi = [
'<li>',
' <div class="hd">' + arr[i].name + '的基本信息</div>',
' <div>',
' <p>姓名:' + arr[i].name + '</p>',
' <p>年龄:' + arr[i].age + '</p>',
' <p>性别:' + arr[i].sex + '</p>',
' </div>',
'</li>'
].join('');
list.innerHTML += oLi;
}
1.3 反引号法
let list = document.getElementById('list');
for (let i = 0; i < arr.length; i++) {
list.innerHTML += `<li>
<div class="hd">${arr[i].name}的基本信息</div>
<div>
<p>姓名:${arr[i].name}</p>
<p>年龄:${arr[i].age}</p>
<p>性别:${arr[i].sex}</p>
</div>
</li>`;
}
1.4 mustache的基本语法
介绍
- mustache官方git:https://github.com/janl/mustache.js
- mustache是“胡子”的意思,因为它的嵌入标记{{ }}非常像胡子
- {{ }}的语法也被vue沿用
- mustache是最早的模板引擎库,比Vue诞生的早多了,它的底层实现机理在当时是非常有创造性的、轰动性的,为后续模板引擎的发展提供了崭新的思路
基本使用
- 必须要引入mustache库,可以在bootcdn.com上找到它(UMD及通用的,在Node环境能用,在浏览器也可以用)
- mustache的模板语法很简单,如下:
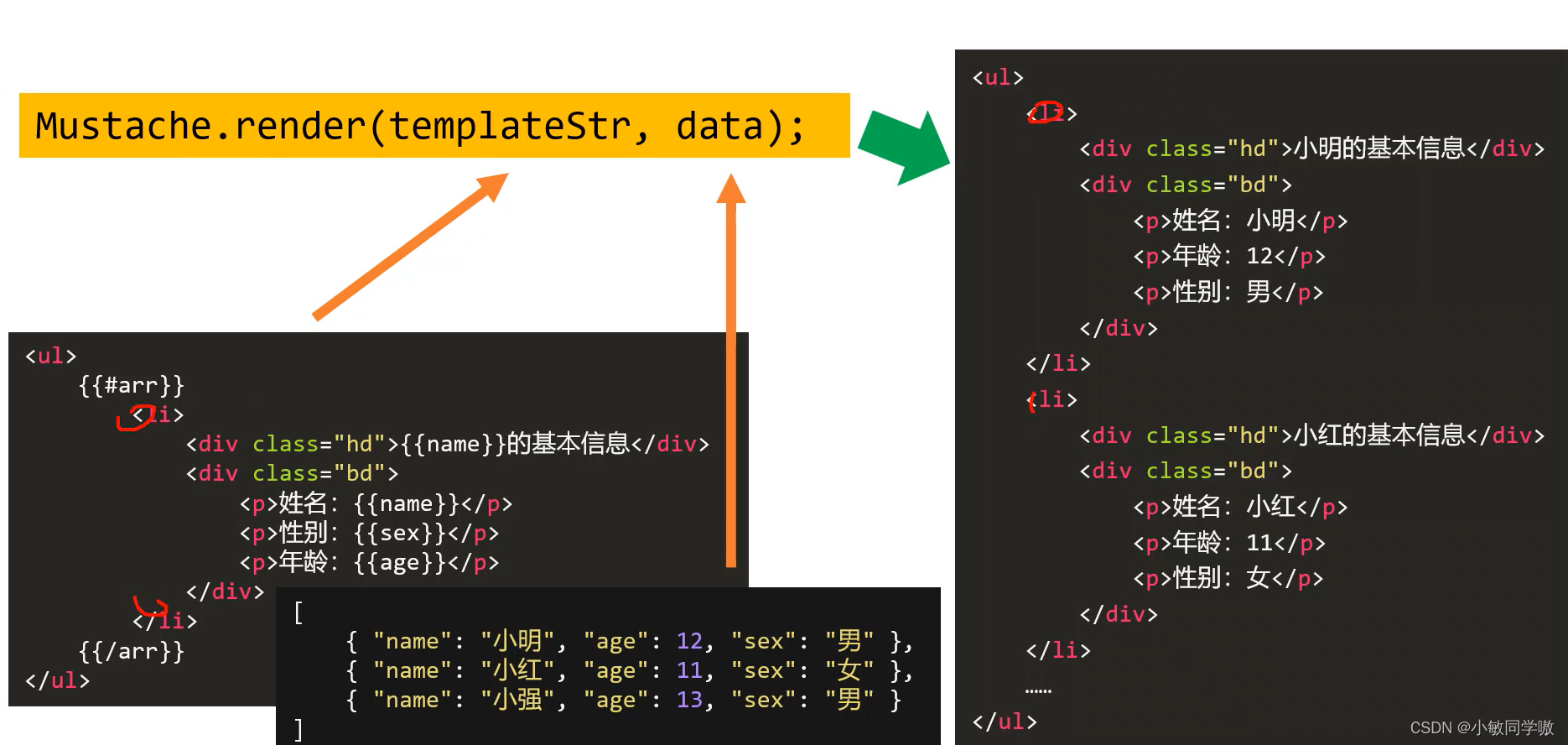
循环用法
//1.对象数组
let data = {
arr: [
{ "name": "小赵", "age": 10, "sex": "男" },
{ "name": "小钱", "age": 11, "sex": "女" },
{ "name": "小孙", "age": 12, "sex": "男" }
]
}
let templateStr = `
<ul>
{{#arr}}
<li>
<div class="hd">{{name}}的基本信息</div>
<div>
<p>姓名:{{name}}</p>
<p>年龄:{{age}}</p>
<p>性别:{{sex}}</p>
</div>
</li>
{{/arr}}
</ul>`
let domStr = Mustache.render(templateStr, data);
//2.简单数组,用{{.}}来表示元素
let data = {
arr: [1, 2, 3, 4]
}
let templateStr = `
{{#arr}}
<p>{{.}}<p>
{{/arr}}`
let domStr = Mustache.render(templateStr, data);
//3.嵌套数组
let data = {
arr: [{ "name": "小周", "hobbies": ["摄影", "睡觉"] }],
flag: true
}
let templateStr = `
<ul>
{{#arr}}
<li>
姓名:{{name}},{{#flag}} 爱好如下:{{/flag}}
<ol>
{{#hobbies}}
<li>{{.}}</li>
{{/hobbies}}
</ol>
</li>
{{/arr}}
</ul>`
let domStr = Mustache.render(templateStr, data);
不循环用法
let templateStr = `
<p>姓名:{{name}},年龄:{{age}}</p>
`
let data = {
name:"小李",
age:20
}
let domStr = Mustache.render(templateStr, data);
1.5 正则表达式思路简介
仅适用于简单场景,复杂场景无法实现,Mustache原理并不是简单的正则匹配。
let templateStr = '<h1>今天买了一个{{thing}},我的心情很{{mood}}</h1>';
let data = {
thing: '好看的裙子',
mood: '开心'
}
mockMustacheRender(templateStr, data);
// 最简单的模板引擎实现机理,利用的是正则表达式中的replace()方法
//
function mockMustacheRender(templateStr, data) {
//(\w+):\w是字母,+号代表多个字母
//$1是代表(\w+)的值,即匹配到的字符串
return templateStr.replace(/\{\{(\w+)\}\}/g, (findStr, $1) => {
return data[$1]
})
}
1.6 底层tokens思想
- tokens是一个JS的嵌套数组,即模板字符串的js表示
- 它是”抽象语法树“、”虚拟节点“等的开山鼻祖
tokens思想
1. 模板字符串编译为tokens
2. tokens结合数据解析为dom字符串
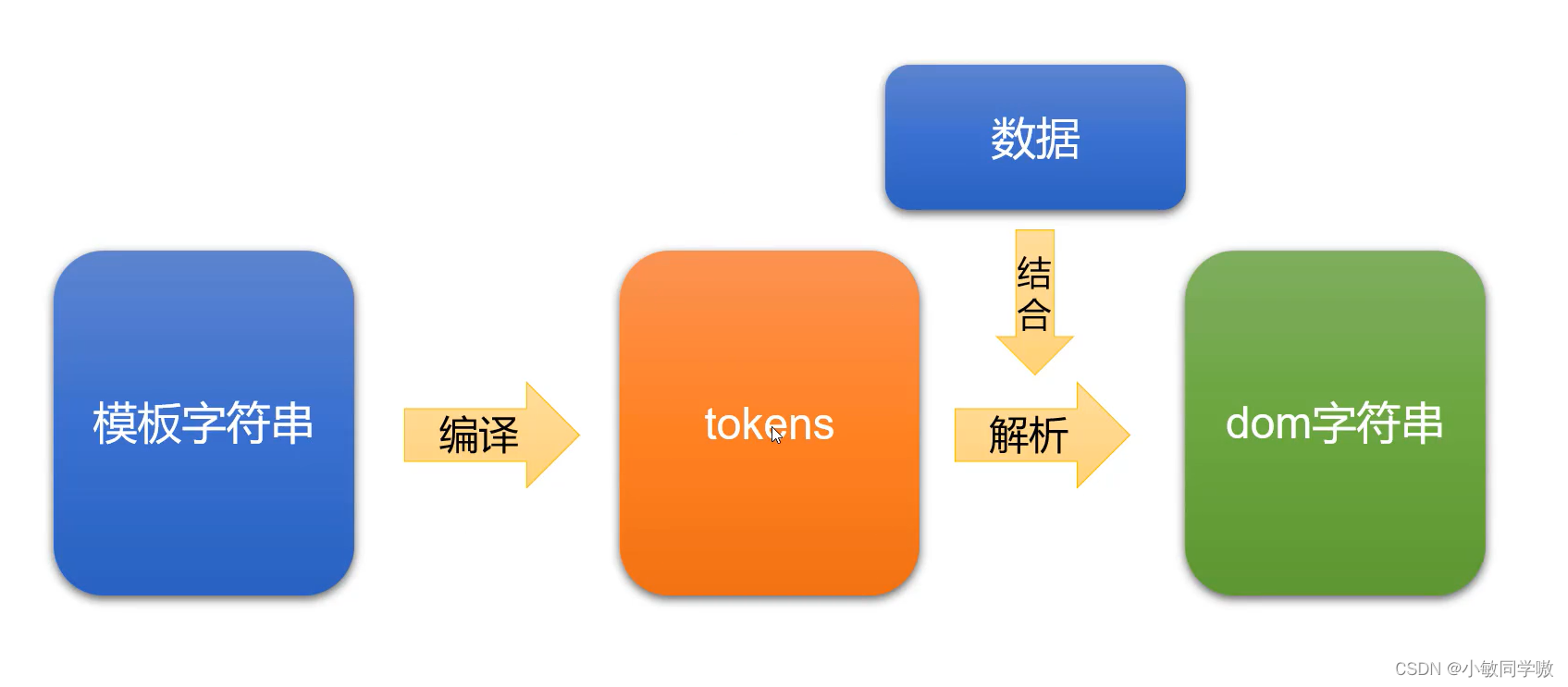
1.6.1 简单模板字符串编译为tokens(手动模拟)
- 模板字符串
`<h1>今天买了一个{{thing}},很{{mood}}</h1>`
- 编译为tokens
[
["text", "<h1>今天买了一条"],
["name", "thing"],
["text", ",很"],
["name", "mood"],
["text", "</h1>"]
]
- 数据
{
thing: '好看的裙子',
mood: '开心'
}
- 结合数据解析为dom字符串
<h1>今天买了一条好看的裙子,很开心</h1>
1.6.2 循环嵌套模板字符串编译为tokens(手动模拟)
- 模板字符串
`<ul>
{{#arr}}
<li>
{{name}}的爱好如下:
<ol>
{{#hobbies}}
<li>{{.}}</li>
{{/hobbies}}
</ol>
</li>
{{/arr}}
</ul>`
- 编译为tokens
[
["text", "<ul>"],
["#", "arr",[
["text", "<li>"],
["name", "name"],
["text", "的爱好如下:<ol>"],
["#", "hobbies", [
["text", "<li>"],
["name", "."],
["text", "</li>"]
]],
["text", "</ol></li>"]
]],
["text", "</ul>"]
]
- 数据
[
{ "name": "小周", "hobbies": ["摄影", "睡觉"] },
{ "name": "小吴", "hobbies": ["看书", "音乐"] },
{ "name": "小郑", "hobbies": ["旅游", "电影"] }
]
- 结合数据解析为dom字符串
<ul>
<li>
小周的爱好如下:
<ol>
<li>摄影</li>
<li>睡觉</li>
</ol>
</li>
<li>
小吴的爱好如下:
<ol>
<li>看书</li>
<li>音乐</li>
</ol>
</li>
<li>
小郑的爱好如下:
<ol>
<li>旅游</li>
<li>电影</li>
</ol>
</li>
</ul>
1.6.3 查看Mustache编译的真实tokens
- 在mustache.js中修改parse方法,打印tokens
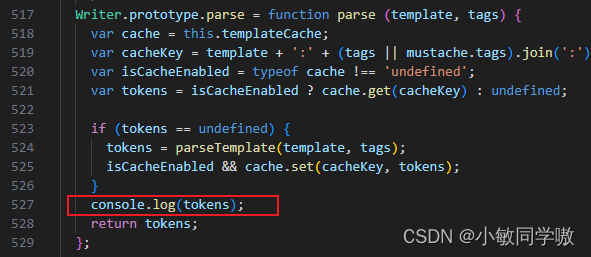
- 控制台查看结果
每个token的数字表示的是该token的起始和结束位置
[
["text", "\n<ul>\n", 0, 6],
["#", "arr", 8, 16, [
["text", " <li>\n ", 17, 28],
["name", "name", 28, 36],
["text", "的爱好如下:\n <ol>\n", 36, 52],
["#", "hobbies", 58, 70, [
["text", " <li>", 71, 81],
["name", ".", 81, 86],
["text", "</li>\n", 86, 92]
], 98],
["text", " </ol>\n </li>\n", 111, 129]
], 131],
["text", "</ul>", 140, 145]
]
1.7 手写实现mustache环境配置
- 模块化打包工具有webpack、rollup、Parcel等
- mustache官方库使用的rollup,我使用的是webpack,因为webpack在浏览器控制台更好调试
- 生成库是UMD的,意味着可以在Node.js中使用(即可以通过npm下载),也可以在浏览器环境使用(即通过script标签引入)。实现UMD不难,只需要一个“通用头即可”
配置环境搭建
- 初始化项目
npm init
- 安装依赖
npm i -D webpack webpack-dev-server webpack-cli
都使用的默认版本,版本如下:
3. 项目目录
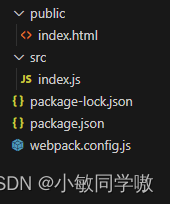
5. 添加webpack.config.js文件
const path = require('path');
module.exports = {
// 模式:开发模式
mode: 'development',
// 入口文件
entry: './src/index.js',
// 打包后文件
output: {
filename: 'bundle.js',
publicPath: "/js"
},
// webpack-dev-server配置
devServer: {
historyApiFallback: true,
static: {
// 被用来决定应该从哪里提供 bundle
directory: path.join(__dirname, 'public'),
},
// 不压缩
compress: false,
// 端口号
port: 8080,
}
};
- 在html里引入js文件
<script src="./js/bundle.js"></script>
- 修改package.json
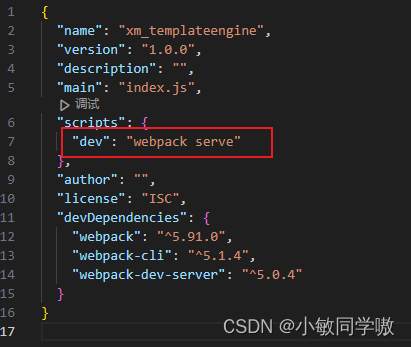
- 运行项目
npm run dev
1.8 手写实现Scanner类
Scanner.js
/*
扫描器类
*/
export default class Scanner {
constructor(templateStr) {
this.templateStr = templateStr;
//指针
this.pos = 0;
//指针当前位置至模板字符串末尾
this.tail = templateStr;
}
// 仅走过指定内容,无需返回值
scan(tag) {
if (this.tail.indexOf(tag) === 0) {
//将指针向后移,tag多长就移几位,跳过"{{"
this.pos += tag.length;
this.tail = this.templateStr.substring(this.pos)
}
}
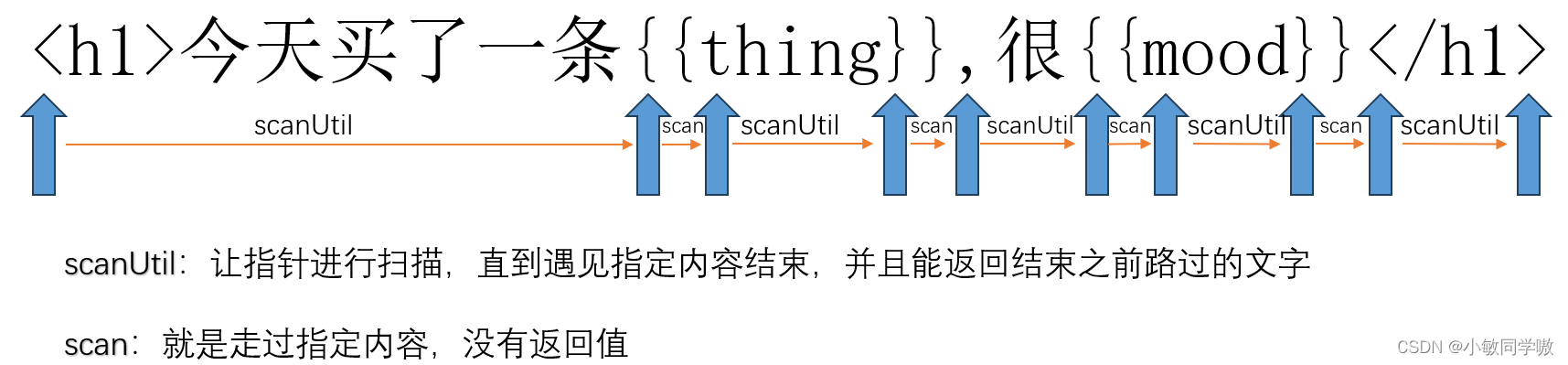
//让指针进行扫描,直到遇见指定内容结束,并且返回结束之前路过的文字
scanUtil(stopTag) {
//记录执行该方法时,pos的值
let pos_start = this.pos;
//当剩余字符串首位不是指定内容时,指针向后移动1位
while (!this.eos() && this.tail.indexOf(stopTag) !== 0) {
this.pos++;
// 取指针当前位置至模板字符串末尾
this.tail = this.templateStr.substring(this.pos)
}
return this.templateStr.substring(pos_start, this.pos);
}
//判断指针是否到末尾,true到末尾了 false没到末尾 eos:end of string
eos() {
return this.pos >= this.templateStr.length;
}
}
index.js
import Scanner from "./Scanner"
window.XM_TemplateEngine = {
render: function (templateStr, data) {
// 实例化一个扫描器,构造函数所需参数为模板字符串
// 这个扫描器就是针对这个模板字符串工作的
const scanner = new Scanner(templateStr);
// 指针不在末尾时
while (!scanner.eos()) {
scanner.scanUtil("{{");
scanner.scan("{{");
scanner.scanUtil("}}");
scanner.scan("}}");
}
}
}
1.9 手写将HTML变为tokens
index.js
import parseTemplateToTokens from "./parseTemplateToTokens";
window.XM_TemplateEngine = {
render: function (templateStr, data) {
//调用方法将模板字符串编译为tokens数组
let tokens = parseTemplateToTokens(templateStr);
console.log(tokens)
}
}
parseTemplateToTokens.js
//parseTemplateToTokens.js
import Scanner from "./Scanner"
/**
* 将模板字符串变为tokens数组
* @param {string} template
* @returns {array} tokens
*/
export default function parseTemplateToTokens(template) {
// 实例化一个扫描器,构造函数所需参数为模板字符串
// 这个扫描器就是针对这个模板字符串工作的
const scanner = new Scanner(templateStr);
let tokens = [];
// 指针不在末尾时,扫描器工作
while (!scanner.eos()) {
// 收集
let word1 = scanner.scanUtil("{{");
let token1 = word1 ? ["text", word1] : null;
token1 ? tokens.push(token1) : {};
scanner.scan("{{");
let words2 = scanner.scanUtil("}}");
if (words2 !== "") {
let token2 = [];
//words2是{{}}中间的变量名,判断首字符是不是#,#开头是数组
if (words2[0] === "#") {
token2 = ["#", words2.substring(1)]
} else if (words2[0] === "/") {
// 是数组结尾
token2 = ["/", words2.substring(1)]
} else {
token2 = ["name", words2];
}
tokens.push(token2);
}
scanner.scan("}}");
}
return tokens;
}
1.10 手写将tokens嵌套起来

栈:是一种先进后出的的数据结构,栈中只有两种基本操作,也就是插入和删除,也就是入栈和出栈操作,栈只有一端可以进行入栈和出栈操作,我们将其称为栈顶,另一端称其为栈底;First In Last Out (FILO)
tokens嵌套逻辑:遇到#就入栈,遇到/就出栈
注意:以下方法并未实现最终效果,仅提供初始思路
nestTokens.js(尝试版)
//nestTokens.js
/**
* 将tokens折叠,变成多层嵌套的tokens(多层数组嵌套的模板字符串)
* @param {Array} originTokens
* @returns {Array} nestedTokens
*/
export default function nestTokens(originTokens) {
// 折叠后的tokens
let nestedTokens = [];
// 栈结构,存放小tokens
let sections = [];
originTokens.forEach(token => {
switch (token[0]) {
case "#":
// 给当前token创建第三项,默认为空数组,里面存放嵌套的tokens
token[2] = [];
// 入栈
sections.push(token);
break;
case "/":
// 出栈
let section = sections.pop();
// 将该token存到nestedTokens中
nestedTokens.push(section);
break;
default:
if (sections.length === 0) {
// 如果当前sections没有元素,证明还没有到数组循环内,直接将token添加到nestedTokens即可
nestedTokens.push(token);
} else {
// 如果当前sections有元素,证明当前token是section嵌套内部的token,添加到当前section的第三项的数组里
// 当前section就是sections的最后一项
sections[sections.length - 1][2].push(token)
}
break;
}
})
return nestedTokens;
}
nestTokens.js(成功版)
该版添加了一个collector收集器,收集器默认指向nestedTokens,中间如果遇到"#"则指向该项token(即section)的第三项,普通"text"项继续push进该collector;如果遇到"/"collector指回上一个section的第三项;如果没有section了,则指回nestedTokens。
提示:可以打断点调试,更清晰
/**
* 将tokens折叠,变成多层嵌套的tokens(多层数组嵌套的模板字符串)
* @param {Array} originTokens
* @returns {Array} nestedTokens
*/
export default function nestTokens(originTokens) {
// 折叠后的tokens
let nestedTokens = [];
// 收集器,初始指向结果数组nestedTokens
let collector = nestedTokens;
// 栈结构,存放小tokens
let sections = [];
originTokens.forEach(token => {
switch (token[0]) {
case "#":
// 入栈
sections.push(token);
// 添加到收集器里(即push进了nestedTokens里)
collector.push(token);
// 给当前token创建第三项,默认为空数组,里面存放嵌套的tokens
// 将collector指向token的第三项[],["#","arr",[]]
collector = token[2] = [];
break;
case "/":
// 出栈
sections.pop();
//修改collector的指向,指向sections最后一个token的第三项,或者指向nestedTokens
collector = sections.length > 0 ? sections[sections.length - 1][2] : nestedTokens;
break;
default:
collector.push(token);
break;
}
})
return nestedTokens;
}
1.11 手写将tokens注入数据
templateRender.js
/**
* 将tokens结合data变为dom字符串
* @param {array} tokens
* @param {object} data
* @returns
*/
import lookup from "./lookup"
export default function renderTemplate(tokens, data) {
let domStr = "";
tokens.forEach(token => {
// token第一项项是标记,可能为:"text" | "name" | "#"
let tag = token[0];// token第二项是data的属性名,此时tag是 "name" | "#"
switch (tag) {
case "text":
// 普通token,直接将值添加到domStr
domStr += token[1];
break;
case "name":
// 当tag是name时,通过lookup函数从data中取对应的属性值,token[1]即data的属性名
domStr += lookup(data, token[1]);
break;
case "#":
// 当tag是#时,当前是数组,token[1]是该数组在data里的属性名,通过lookup从data取子数组的数据
//
lookup(data, token[1]).forEach(item => {
// 递归调用,token[2]就是当前token的子token
domStr += renderTemplate(token[2], item);
})
break;
}
})
return domStr;
}
1.12 手写lookup函数
lookup.js
/**
* 查找data里key对应的属性值 data[keyStr] 兼容三种情况:1.data['.'] 2.data['a.b.c'] 3.data['a']
* @param {object} data
* @param {string} keyStr
*/
export default function lookup(data, keyStr) {
// 1.data['.'] 模板字符串是:{{.}} 当双括号里是.时,代表数组循环的其中一项,为简单数组
if (keyStr === '.') {
return data;
}
// 2.data['a.b.c'] 模板字符串是:{{a.b.c}} 当双括号是多个.时,代表是多层对象属性,data["a.b.c"]是无法取到对应值的,需要处理成:data[a][b][c]
if (keyStr.indexOf('.') !== -1) {
let value = data;
let keyArr = keyStr.split('.');
keyArr.forEach(key => {
value = value[key]
})
return value;
}
// 3.data['a'] 模板字符串是:{{a}} 普通情况,直接返回
return data[keyStr];
}
完整代码:https://gitee.com/xiao-min-1996/xm-template-engine
二、虚拟DOM和Diff算法
2.1 snabbdom简介和测试环境搭建
Vue源码借鉴了snabbdom的思想,snabbdom是著名的虚拟DOM库,是diff算法的鼻祖。
官方git:https://github.com/snabbdom/snabbdom
- 1.初始化项目
npm init
- 2.git上的源码是用typescript写的,如果要使用js版本,可以从npm上下载
npm i -S snabbdom
- 3.snabbdom库是DOM库,当然不能在nodejs环境运行,所以我妈需要搭建webpack和webpack-dev-server开发环境,好消息是不需要安装任何loader
npm i -D webpack webpack-dev-server webpack-cli
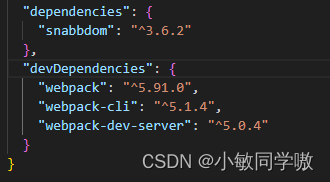
- 4.webpack.config.js
const path = require('path');
module.exports = {
mode: 'development',
// 入口
entry: './src/index.js',
output: {
// 说明:https://www.webpackjs.com/configuration/output/#outputpublicpath
publicPath: "/js",
filename: 'bundle.js',
},
devServer: {
port: 8080,
static: {
directory: path.join(__dirname, 'public')
}
}
};
- 5.使用snabbdom官方示例
/src/index.js
import {
init,
classModule,
propsModule,
styleModule,
eventListenersModule,
h
} from "snabbdom";
const patch = init([
// Init patch function with chosen modules
classModule, // makes it easy to toggle classes
propsModule, // for setting properties on DOM elements
styleModule, // handles styling on elements with support for animations
eventListenersModule // attaches event listeners
]);
const container = document.getElementById("container");
const vnode = h(
"div#container.two.classes",
{ on: { click: () => console.log("div clicked") } },
[
h("span", { style: { fontWeight: "bold" } }, "This is bold"),
" and this is just normal text",
h("a", { props: { href: "/foo" } }, "I'll take you places!")
]
);
// Patch into empty DOM element – this modifies the DOM as a side effect
patch(container, vnode);
const newVnode = h(
"div#container.two.classes",
{ on: { click: () => console.log("updated div clicked") } },
[
h(
"span",
{ style: { fontWeight: "normal", fontStyle: "italic" } },
"This is now italic type"
),
" and this is still just normal text",
h("a", { props: { href: "/bar" } }, "I'll take you places!")
]
);
// Second `patch` invocation
patch(vnode, newVnode); // Snabbdom efficiently updates the old view to the new state
/public/index.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>diff算法解析</title>
</head>
<body>
<div id="container"></div>
<script src="./js/bundle.js"></script>
</body>
</html>
package.json
{
"name": "study-snabbdom",
"version": "1.0.0",
"description": "",
"main": "index.js",
"scripts": {
"dev": "webpack-dev-server"
},
"author": "",
"license": "ISC",
"dependencies": {
"snabbdom": "^3.6.2"
},
"devDependencies": {
"webpack": "^5.91.0",
"webpack-cli": "^5.1.4",
"webpack-dev-server": "^5.0.4"
}
}
2.2 虚拟DOM和h函数
- 虚拟DOM:用javascript对象描述DOM的层次结构。DOM中的一切属性都在虚拟DOM中有对应的属性。
(注:diff算法是发生在虚拟DOM上的)
//虚拟节点的属性
{
children: undefined,// 子节点
data: {},// 节点属性
elm: undefined,// 虚拟节点对应的真实DOM
key: undefined,// 唯一标识
sel: "",// 标签名称
text: ""// 文本
}
- h函数: h函数用来产生虚拟节点(vnode),可以去嵌套使用,从而得到虚拟DOM树。
调用h函数:
h('a', { props: { href: "https://www.baidu.com/"}}, '百度一下');
得到的虚拟节点:
{
"sel": "a",
"data":{
props: { href: "https://www.baidu.com/"}
},
"text": "百度一下"
}
真正的DOM节点:
<a href="https://www.baidu.com/">百度一下</a>
2.3 手写h函数
h.js
import vnode from "./vnode";
/**
* 低配版的h函数,该函数必须接受3个参数,缺一不可(省略函数重载)
* 形态1: h('div',{},'文字')
* 形态2: h('div',{},[])
* 形态3: h('div',{},h())
* @param {*} sel
* @param {*} data
* @param {*} c
* @returns
*/
export default function h(sel, data, c) {
// 检查参数的个数
if (arguments.length !== 3) {
throw new Error("h数只能传入3个参数")
}
// 形态1
if (typeof c === 'string' || typeof c === "number") {
// return vnode(sel, data, children, text, elm)
return vnode(sel, data, undefined, c, undefined);
}
let children = [];
// 形态2
if (Array.isArray(c)) {
// 遍历c
c.forEach(item => {
if (!item instanceof Object || !item.hasOwnProperty('sel')) {
throw new Error("传入的数组参数中有项不是h函数");
}
// 收集children
children.push(item);
})
return vnode(sel, data, children, undefined, undefined);
}
// 形态3
if (typeof c == 'function' && c.hasOwnProperty('sel')) {
// 传入的c是唯一的children
let children = [c];
return vnode(sel, data, children, undefined, undefined);
}
throw new Error("传入的第三个参数不正确!");
}
vnode.js
/**
* 把传入的5个参数组合成对象返回
* @param {string} sel
* @param {object} data
* @param {Array} children
* @param {string} text
* @param {object} elm
* @returns
*/
export default function vnode(sel, data, children, text, elm) {
return {
sel,
data,
children,
text,
elm
}
}
2.4 感受Diff算法
- key是节点的唯一标识,告诉diff算法在更改前后它们是同一个DOM节点
- 只有是同一个虚拟节点才进行精细化比较,否则就是暴力删除旧的、插入新的(选择器相同&key相同才是同一个节点)
- 只进行同层比较,不会进行跨层比较
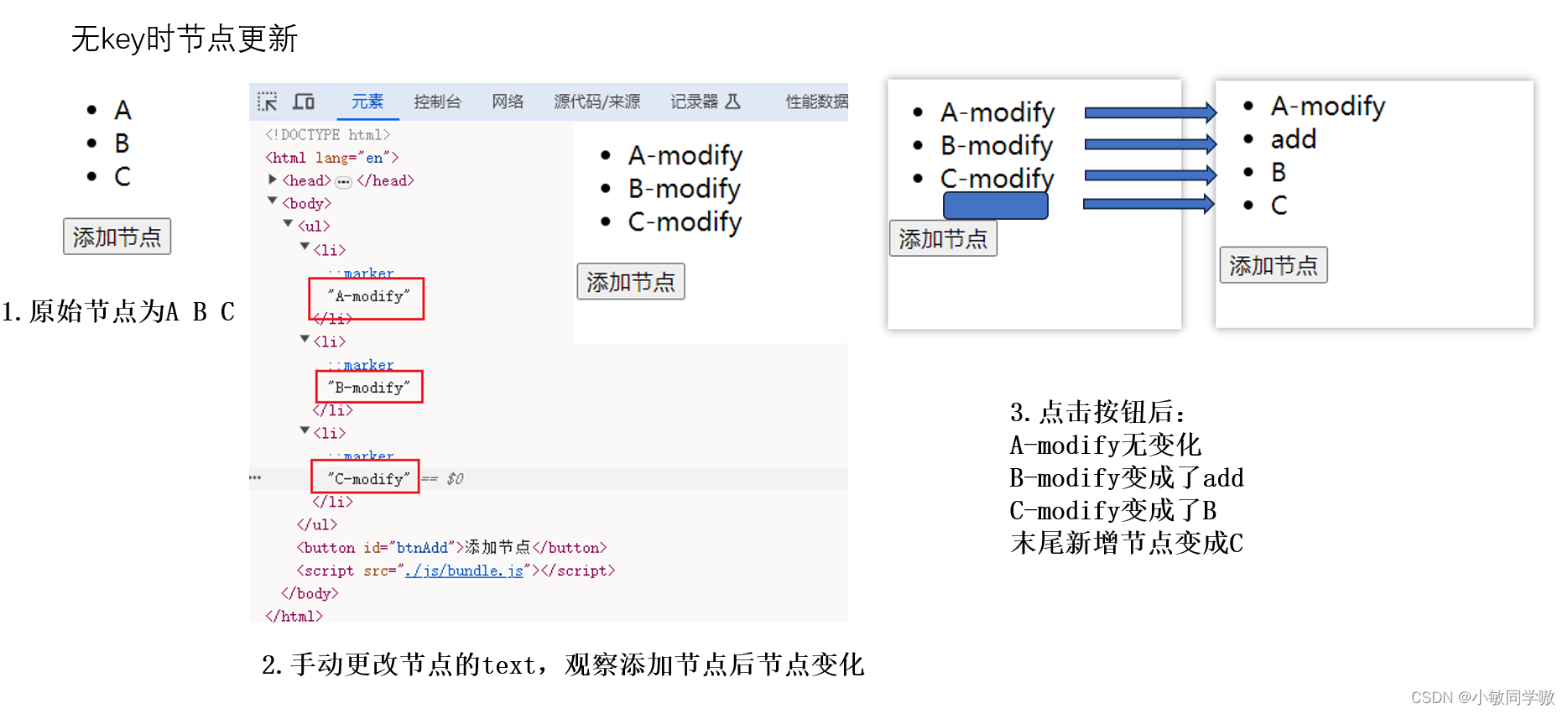
2.4.1 虚拟节点无key值时
import {
init,
classModule,
propsModule,
styleModule,
eventListenersModule,
h
} from "snabbdom";
const patch = init([
// Init patch function with chosen modules
classModule, // makes it easy to toggle classes
propsModule, // for setting properties on DOM elements
styleModule, // handles styling on elements with support for animations
eventListenersModule // attaches event listeners
]);
const container = document.getElementById("container");
const vnode1 = h(
'ul',
{},
[
h('li', {}, 'A'),
h('li', {}, 'B'),
h('li', {}, 'C')
]
);
// Patch into empty DOM element – this modifies the DOM as a side effect
patch(container, vnode1);
const vnode2 = h(
'ul',
{},
[
h('li', {}, 'A'),
h('li', {}, 'add'),
h('li', {}, 'B'),
h('li', {}, 'C')
]
);
const btnAdd = document.getElementById("btnAdd");
btnAdd.addEventListener('click', () => {
patch(vnode1, vnode2);
})
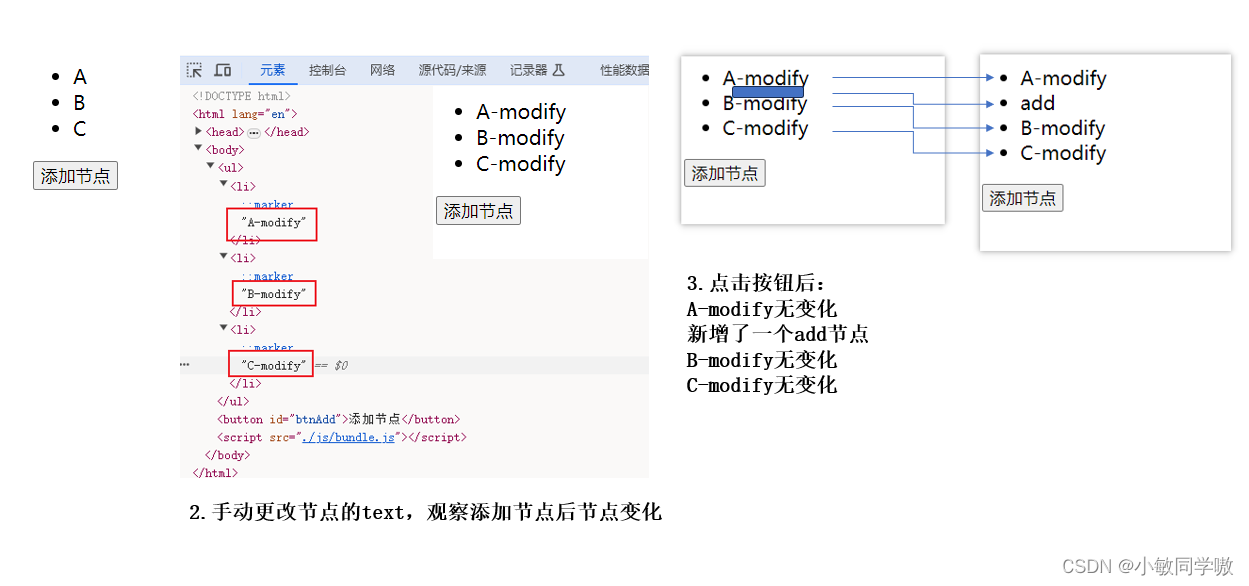
2.4.2 虚拟节点添加key值
import {
init,
classModule,
propsModule,
styleModule,
eventListenersModule,
h
} from "snabbdom";
const patch = init([
// Init patch function with chosen modules
classModule, // makes it easy to toggle classes
propsModule, // for setting properties on DOM elements
styleModule, // handles styling on elements with support for animations
eventListenersModule // attaches event listeners
]);
const container = document.getElementById("container");
const vnode1 = h(
'ul',
{},
[
h('li', { key: 'A' }, 'A'),
h('li', { key: 'B' }, 'B'),
h('li', { key: 'C' }, 'C')
]
);
// Patch into empty DOM element – this modifies the DOM as a side effect
patch(container, vnode1);
const vnode2 = h(
'ul',
{},
[
h('li', { key: 'A' }, 'A'),
h('li', { key: 'add' }, 'add'),
h('li', { key: 'B' }, 'B'),
h('li', { key: 'C' }, 'C')
]
);
const btnAdd = document.getElementById("btnAdd");
btnAdd.addEventListener('click', () => {
patch(vnode1, vnode2);
})
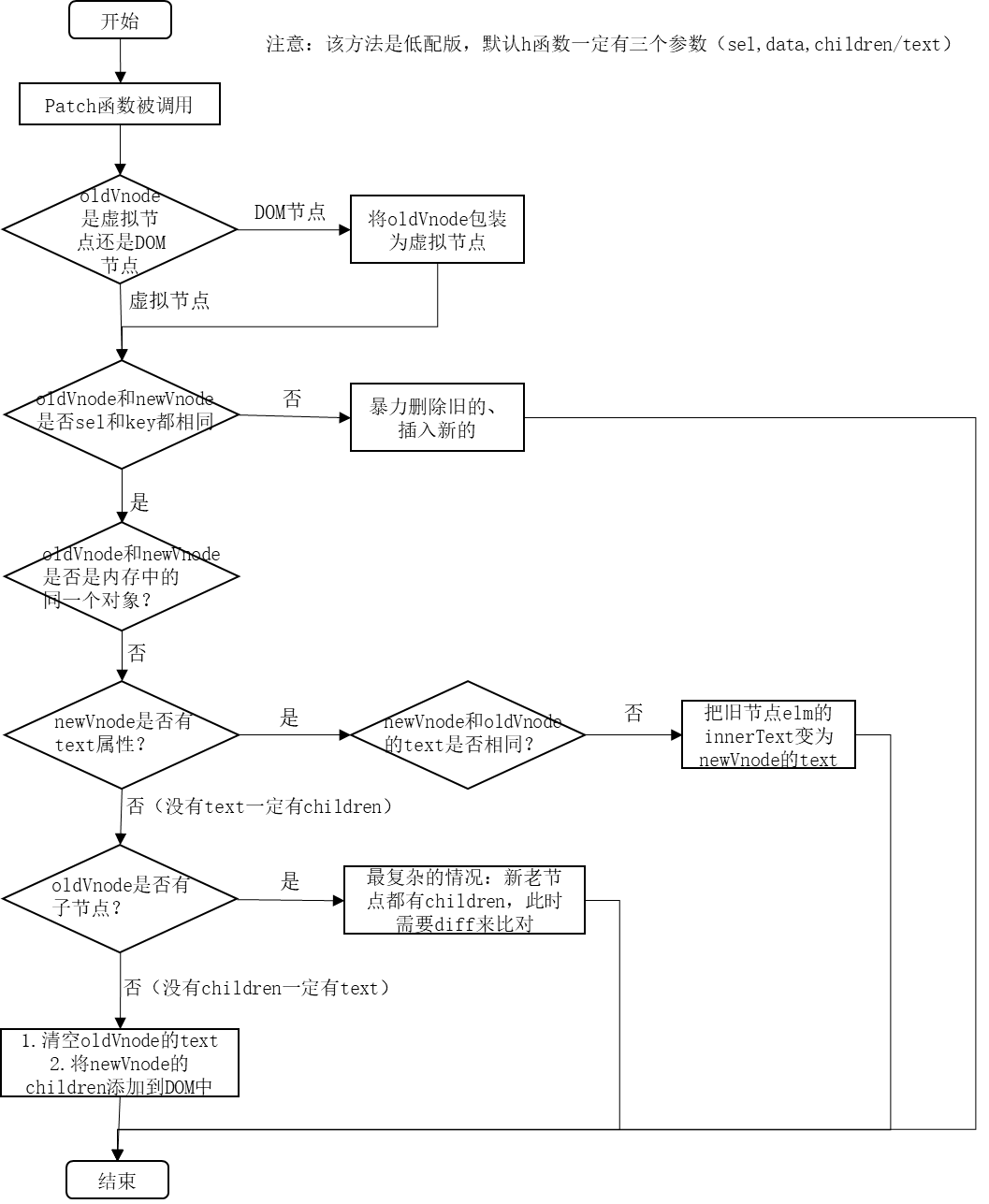
2.5 diff处理新旧节点不是同一个节点时
2.6 手写第一次上树时
patch.js
import vnode from "./vnode";
import createElement from "./createElement";
export default function patch(oldVnode, newVnode) {
// 判断oldVnode是虚拟节点还是DOM节点
if (oldVnode.sel == "" || oldVnode.sel == undefined) {
oldVnode = documentToVnode(oldVnode);
}
// 判断oldVnode和newVnode是否是同一个节点
if (sameVnode(oldVnode, newVnode)) {
console.info('是同一个节点,精细化比较')
} else {
// 暴力插入新的节点,删除旧的节点
console.info('不是同一个节点,暴力插入新的节点,删除旧的节点');
let newVnodeElm = createElement(newVnode, oldVnode.elm);
// 插入到老节点之前
oldVnode.elm.parentNode.insertBefore(newVnodeElm, oldVnode.elm);
// 删除老节点
oldVnode.elm.parentNode.removeChild(oldVnode.elm);
}
}
// 根据DOM节点创建虚拟节点(低配版)
function documentToVnode(node) {
// 选择器
const sel = node.tagName.toLowerCase();
// 类名
const className = node.className;
// id
const id = node.id;
// 子节点
const children = [];
for (let i = 0; i < node.children.length; i++) {
children.push(documentToVnode(node.children[i]));
}
// 文本
const text = node.textContent;
// 实际的DOM节点
const elm = node;
const data = {
props: {
class: className,
id
}
}
return vnode(sel, data, children, text, elm);
}
//判断是否是同一个节点
function sameVnode(oldVnode, newVnode) {
return oldVnode.sel === newVnode.sel && oldVnode.key === newVnode.key
}
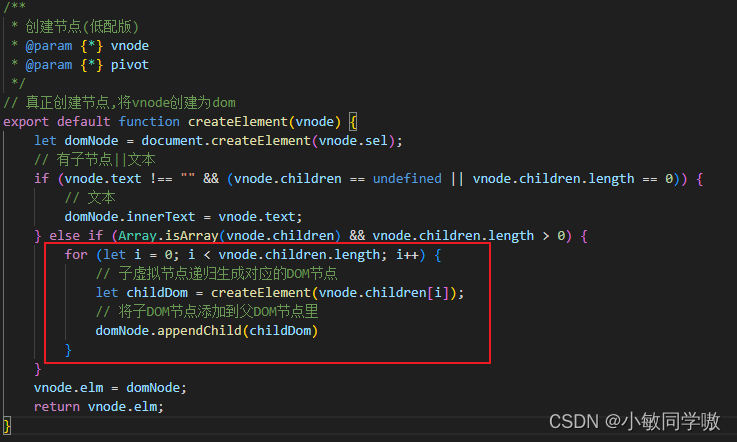
createElement.js
/**
* 创建节点(低配版)
* @param {*} vnode
* @param {*} pivot
*/
// 真正创建节点,将vnode创建为dom
export default function createElement(vnode) {
let domNode = document.createElement(vnode.sel);
// 有子节点||文本
if (vnode.text !== "" && (vnode.children == undefined || vnode.children.length == 0)) {
// 文本
domNode.innerText = vnode.text;
} else if (Array.isArray(vnode.children) && vnode.children.length > 0) {
// 待递归子节点
}
vnode.elm = domNode;
return vnode.elm;
}
2.7 手写递归创建子节点
createElement.js
2.8 diff处理新旧节点是同一个节点时
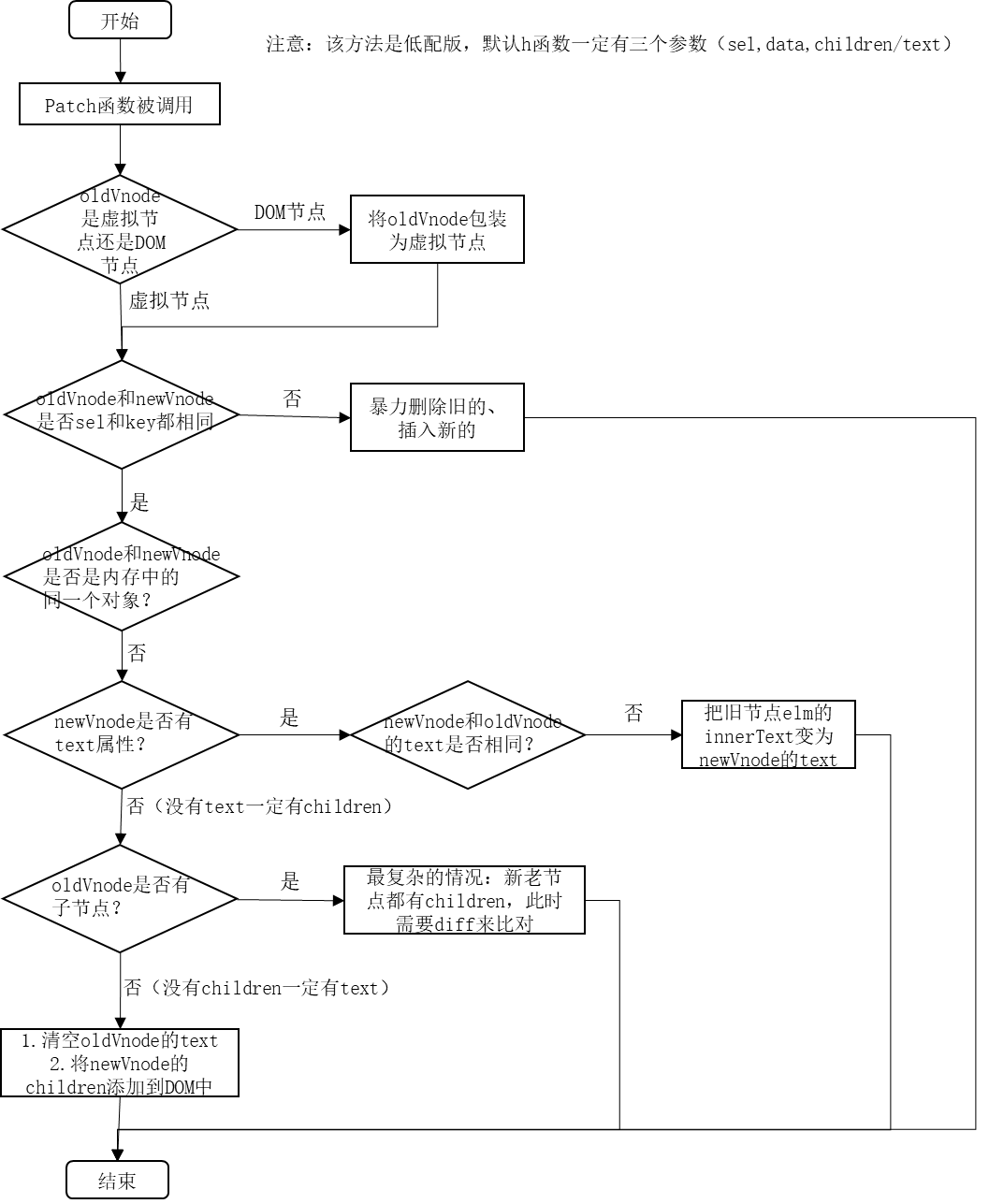
2.9 手写新旧节点text的不同情况
import vnode from "./vnode";
import createElement from "./createElement";
export default function patch(oldVnode, newVnode) {
// 判断oldVnode是虚拟节点还是DOM节点
if (oldVnode.sel == "" || oldVnode.sel == undefined) {
oldVnode = documentToVnode(oldVnode);
}
// oldVnode和newVnode是同一个节点
if (sameVnode(oldVnode, newVnode)) {
//判断newVnode和oldVnode是否是同一个对象
if (oldVnode === newVnode) return;
// newVnode有text属性,没有children
if (newVnode.text && (!newVnode.children || newVnode.children.length === 0)) {
// newVnode的text属性不等于oldVnode的text属性
if (newVnode.text !== oldVnode.text) {
// 将oldVnode的elm.innerText变为newVnode的text
oldVnode.elm.innerText = newVnode.text;
}
} else {
// newVnode有children,没有text属性
// oldVnode有children
if (Array.isArray(oldVnode.children) && oldVnode.children.length > 0) {
// diff 待补充
} else {
// oldVnode没有children
// 清空oldVnode的text属性
oldVnode.elm.innerText = null;
// 遍历newVnode的子节点
for (let i = 0; i < newVnode.children.length; i++) {
let newVnodeElm = createElement(newVnode.children[i]);
// 将新增的子节点添加到oldVnode的DOM节点上
oldVnode.elm.appendChild(newVnodeElm);
}
}
}
} else {
// oldVnode和newVnode不是同一个节点
// 暴力插入新的节点,删除旧的节点
console.info('不是同一个节点,暴力插入新的节点,删除旧的节点');
let newVnodeElm = createElement(newVnode, oldVnode.elm);
if (oldVnode.elm.parentNode && newVnodeElm) {
// 插入到老节点之前
oldVnode.elm.parentNode.insertBefore(newVnodeElm, oldVnode.elm);
// 删除老节点
oldVnode.elm.parentNode.removeChild(oldVnode.elm);
}
}
}
// 根据DOM节点创建虚拟节点
function documentToVnode(node) {
// 选择器
const sel = node.tagName.toLowerCase();
// 类名
const className = node.className;
// id
const id = node.id;
// 子节点
const children = [];
for (let i = 0; i < node.children.length; i++) {
children.push(documentToVnode(node.children[i]));
}
// 文本
const text = node.textContent;
// 实际的DOM节点
const elm = node;
const data = {
props: {
class: className,
id
}
}
return vnode(sel, data, children, text, elm);
}
//判断是否是同一个节点
function sameVnode(oldVnode, newVnode) {
return oldVnode.sel === newVnode.sel && oldVnode.key === newVnode.key
}
2.10 尝试书写diff更新子节点(错误尝试,为了突出后续diff算法的优势)
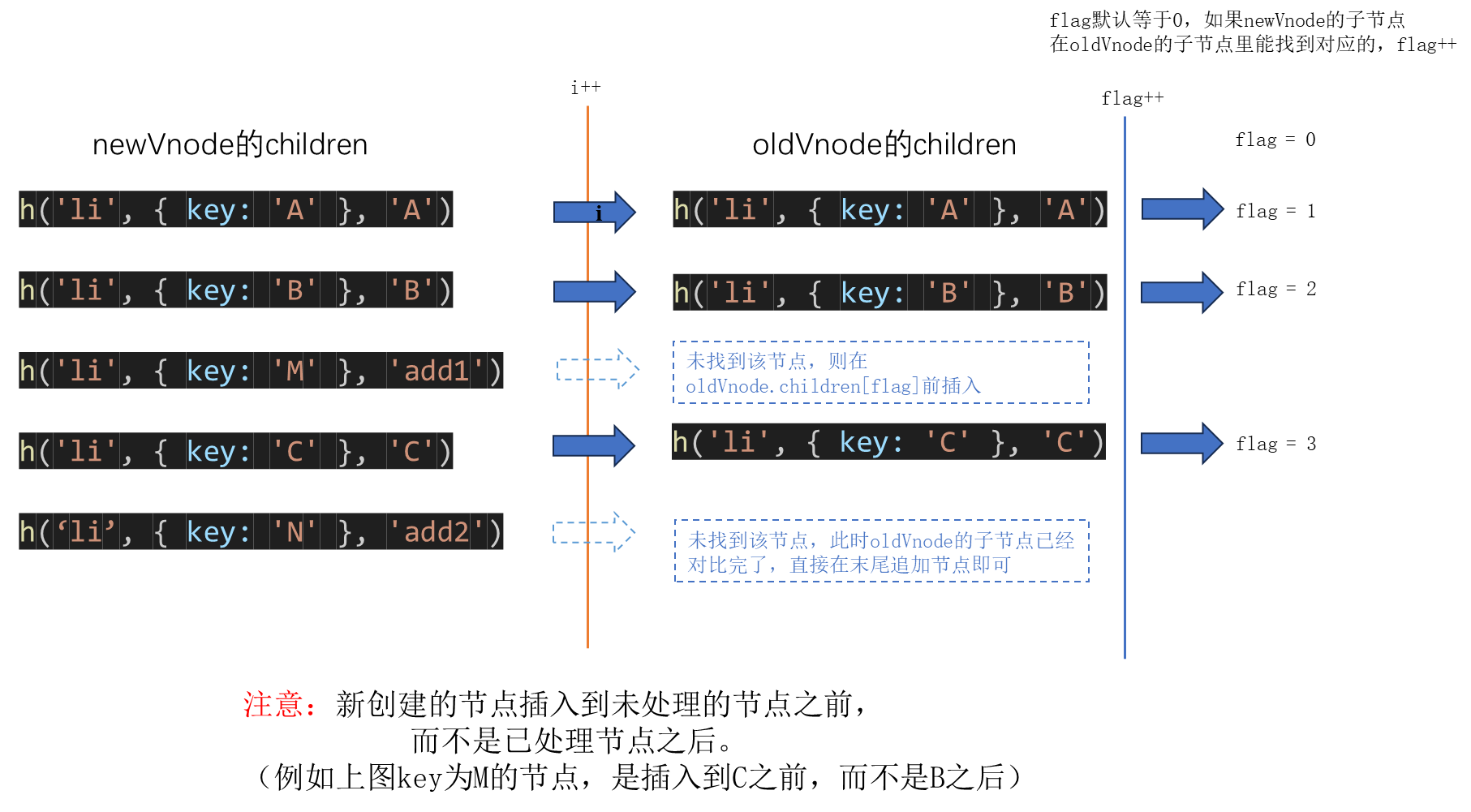
当前思路无法处理以下所有情况:
- 新增了节点在中间/开头
- 新增了节点在末尾
- 删除了节点
- 节点移动了位置
- 节点内容更新了
patchNode.js(当前思路无法处理所有情况)
import createElement from "./createElement";
export default function patchVnode(oldVnode, newVnode) {
//判断newVnode和oldVnode是否是同一个对象
if (oldVnode === newVnode) return;
// newVnode有text属性,没有children
if (newVnode.text && (!newVnode.children || newVnode.children.length === 0)) {
// newVnode的text属性不等于oldVnode的text属性
if (newVnode.text !== oldVnode.text) {
// 将oldVnode的elm.innerText变为newVnode的text
oldVnode.elm.innerText = newVnode.text;
}
} else {
// newVnode有children,没有text属性
// oldVnode有children
if (Array.isArray(oldVnode.children) && oldVnode.children.length > 0) {
// diff比较
let flag = 0;// 未处理的节点的开头
for (let i = 0; i < newVnode.children.length; i++) {
let new_child = newVnode.children[i];
let isExist = false;// oldVnode中是否存在new_child子节点
// 遍历oldVnode
for (let j = 0; j < oldVnode.children.length; j++) {
let old_child = oldVnode.children[j];
if (new_child.sel === old_child.sel && new_child.key === old_child.key) {
// 存在该节点
isExist = true;
patchVnode(old_child, new_child);
}
}
if (!isExist) {
// oldVnode中不存在new_child
// 为这个新节点创建新的DOM节点
let dom_child = createElement(new_child);
new_child.elm = dom_child;
if (flag < oldVnode.children.length) {
// 如果flag小于oldVnode子节点的长度
// 在剩余节点前插入该新节点
oldVnode.elm.insertBefore(dom_child, oldVnode.children[flag].elm)
} else {
// oldVnode没有剩余子节点了,直接将新节点添加在末尾
oldVnode.elm.appendChild(dom_child);
}
} else {
flag++;
//todo: 如果节点只是移动位置,待处理
}
}
} else {
// oldVnode没有children
// 清空oldVnode的text属性
oldVnode.elm.innerText = null;
// 遍历newVnode的子节点
for (let i = 0; i < newVnode.children.length; i++) {
let newVnodeElm = createElement(newVnode.children[i]);
// 将新增的子节点添加到oldVnode的DOM节点上
oldVnode.elm.appendChild(newVnodeElm);
}
}
}
}
2.11 diff算法的子节点更新策略
这一节光看文字比较难理解,建议还是看视频,跟着视频画图理解。
经典的diff算法的优化策略(四种命中方式): 顺序就是按如下顺序来的
- 新前与旧前
- 新后与旧后
- 新后与旧前(如果命中了,新后指向的节点要移动到旧后之后)
- 新前与旧后(如果命中了,新前指向的节点要移动到旧前之前)
(如果这4种都没命中,则循环遍历oldVnode,找到节点改为undefined,并将新节点移动到旧前之前。)
新前(newStart):newVnode里第一个未处理的节点
新后(oldEnd):newVnode里最后一个未处理的节点
旧前(oldStart):oldVnode里第一个未处理的节点
旧后(oldEnd):oldVnode里最后一个未处理的节点
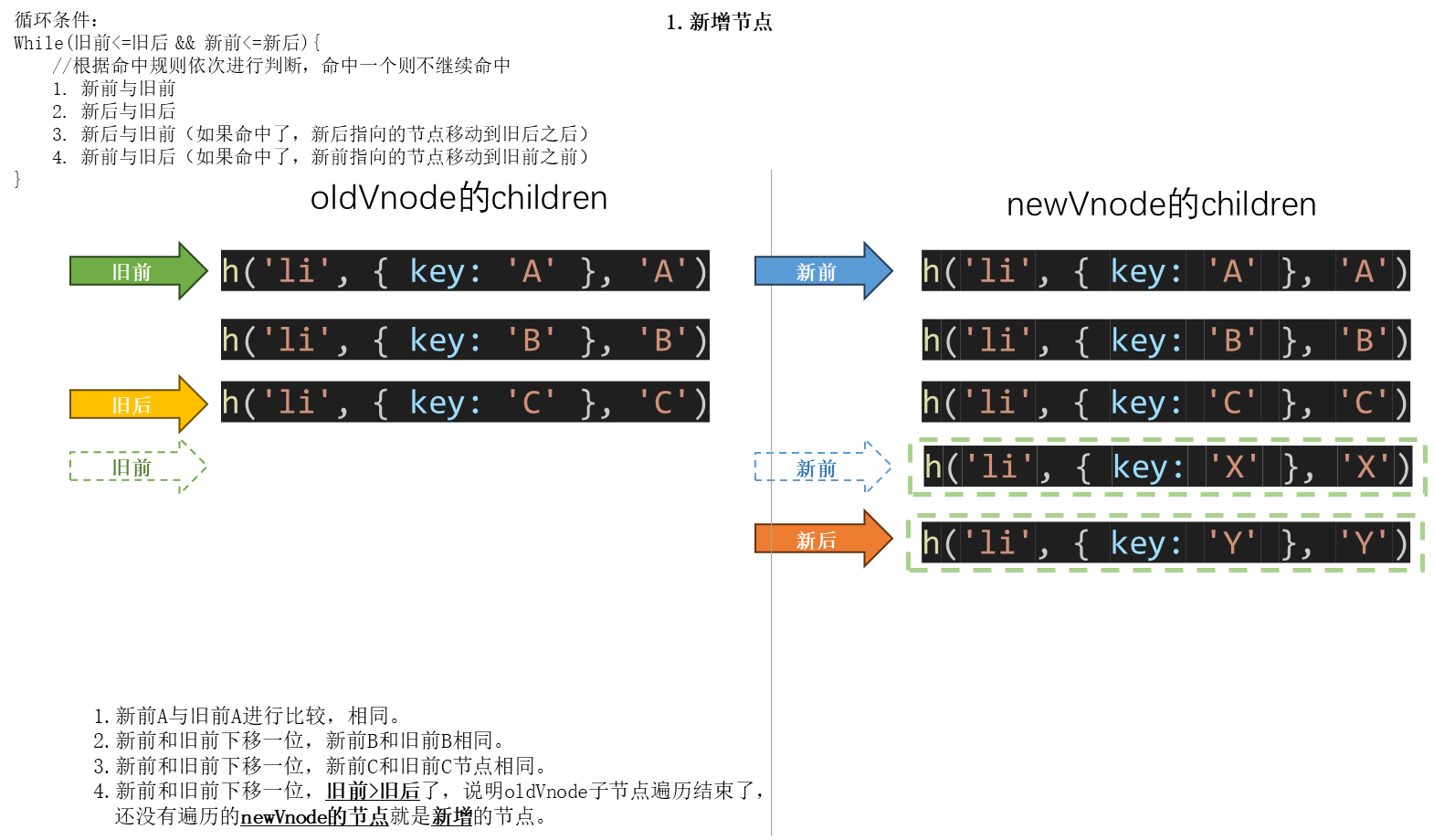
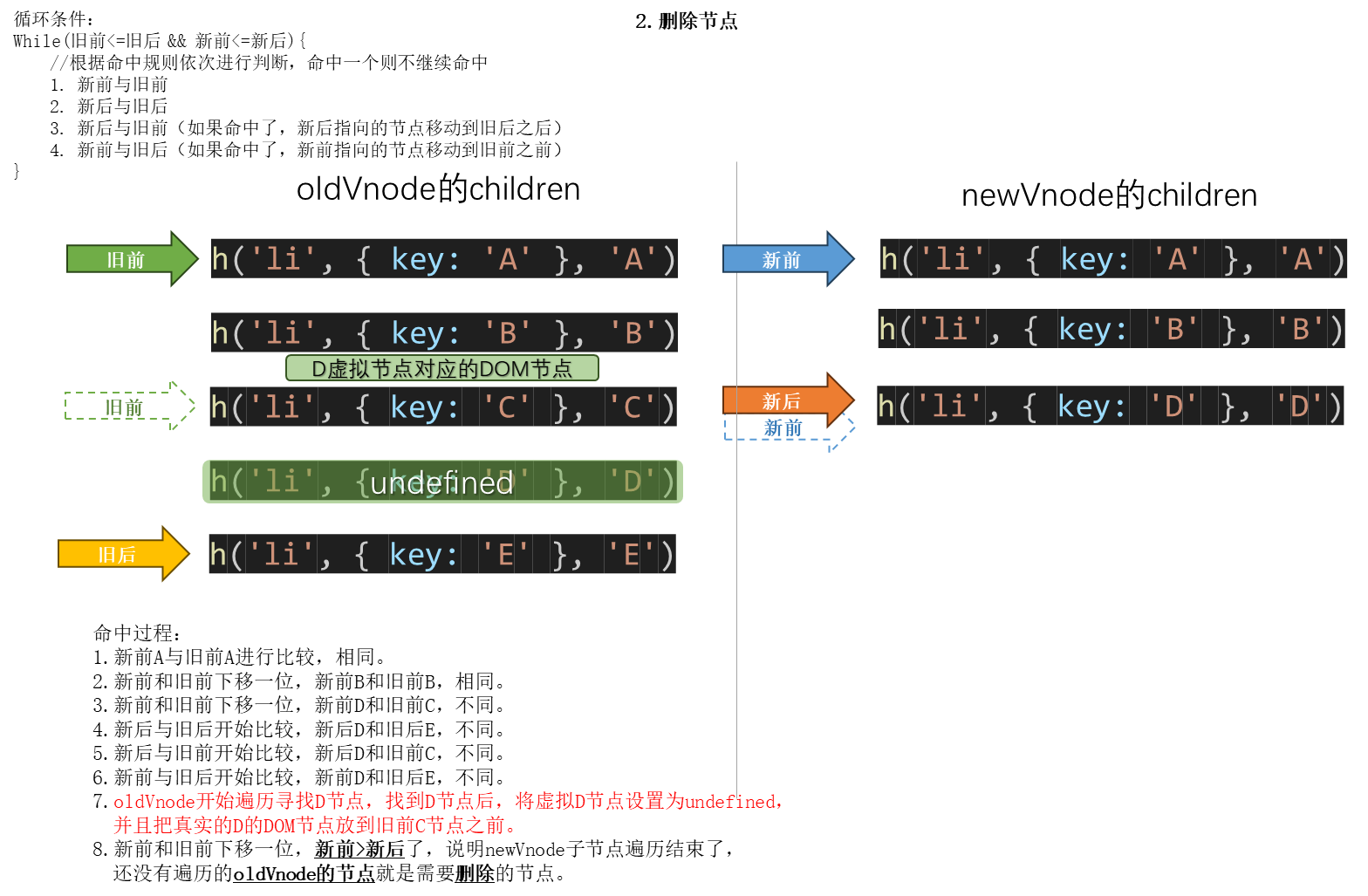
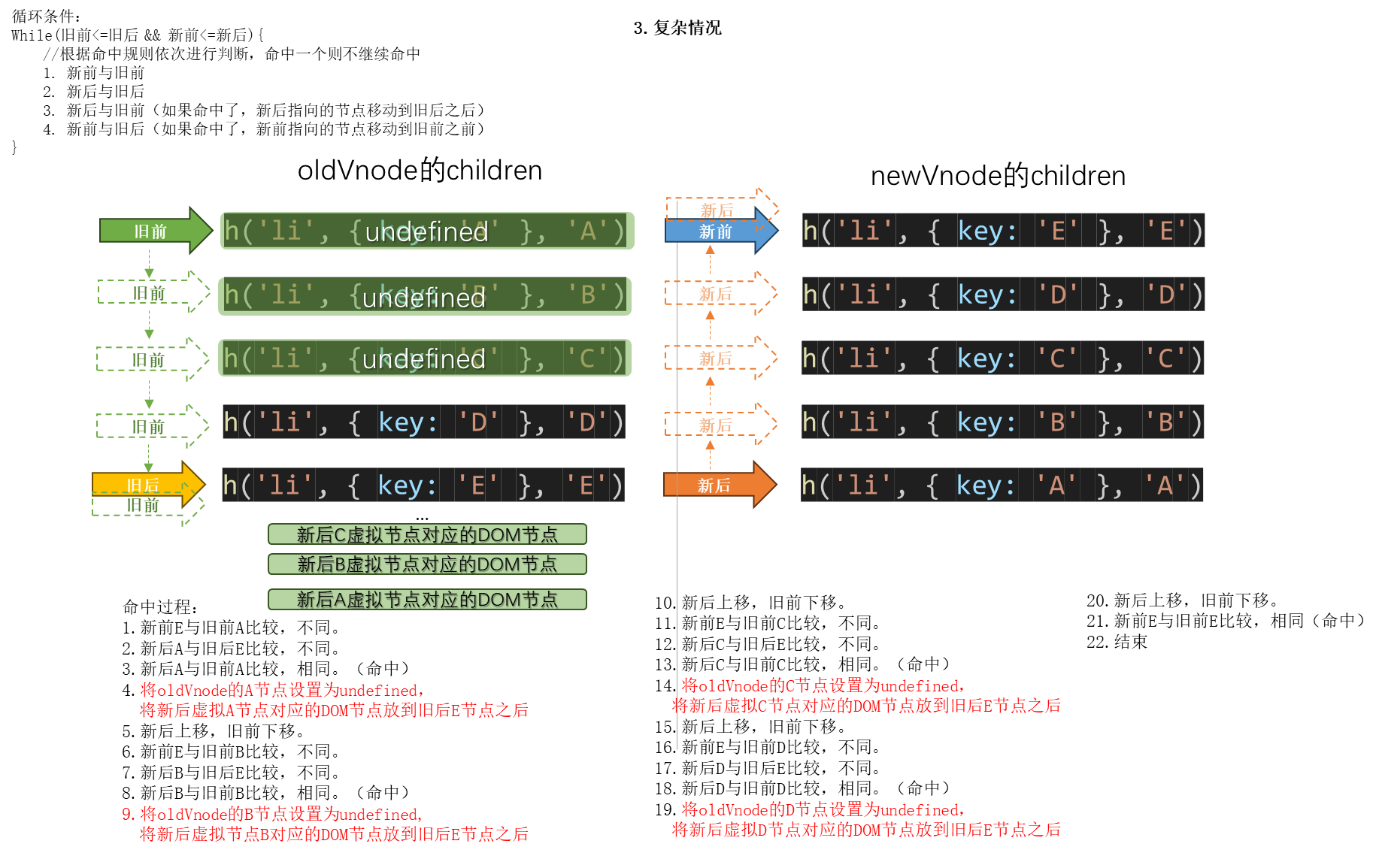
2.12 手写子节点更新策略
完整代码:https://gitee.com/xiao-min-1996/my-snabbdom
patch.js
import vnode from "./vnode";
import createElement from "./createElement";
import patchVnode from "./patchVnode";
export default function patch(oldVnode, newVnode) {
// 判断oldVnode是虚拟节点还是DOM节点
if (oldVnode.sel == "" || oldVnode.sel == undefined) {
oldVnode = documentToVnode(oldVnode);
}
// oldVnode和newVnode是同一个节点
if (sameVnode(oldVnode, newVnode)) {
// 调用patchVnode处理
patchVnode(oldVnode, newVnode);
} else {
// oldVnode和newVnode不是同一个节点
// 暴力插入新的节点,删除旧的节点
let newVnodeElm = createElement(newVnode, oldVnode.elm);
if (oldVnode.elm.parentNode && newVnodeElm) {
// 插入到老节点之前
oldVnode.elm.parentNode.insertBefore(newVnodeElm, oldVnode.elm);
// 删除老节点
oldVnode.elm.parentNode.removeChild(oldVnode.elm);
}
}
}
// 根据DOM节点创建虚拟节点
function documentToVnode(node) {
// 选择器
const sel = node.tagName.toLowerCase();
// 类名
const className = node.className;
// id
const id = node.id;
// 子节点
const children = [];
for (let i = 0; i < node.children.length; i++) {
children.push(documentToVnode(node.children[i]));
}
// 文本
const text = node.textContent;
// 实际的DOM节点
const elm = node;
const data = {
props: {
class: className,
id
}
}
return vnode(sel, data, children, text, elm);
}
//判断是否是同一个节点
function sameVnode(oldVnode, newVnode) {
return oldVnode.sel === newVnode.sel && oldVnode.key === newVnode.key
}
patchVnode.js
import createElement from "./createElement";
import updateChildren from "./updateChildren";
export default function patchVnode(oldVnode, newVnode) {
//判断newVnode和oldVnode是否是同一个对象
if (oldVnode === newVnode) return;
// newVnode有text属性,没有children
if (newVnode.text && (!newVnode.children || newVnode.children.length === 0)) {
// newVnode的text属性不等于oldVnode的text属性
if (newVnode.text !== oldVnode.text) {
// 将oldVnode的elm.innerText变为newVnode的text
oldVnode.elm.innerText = newVnode.text;
}
} else {
// newVnode有children,没有text属性
// oldVnode有children
if (Array.isArray(oldVnode.children) && oldVnode.children.length > 0) {
updateChildren(oldVnode.elm, oldVnode.children, newVnode.children);
} else {
// oldVnode没有children
// 清空oldVnode的text属性
oldVnode.elm.innerText = null;
// 遍历newVnode的子节点
for (let i = 0; i < newVnode.children.length; i++) {
let newVnodeElm = createElement(newVnode.children[i]);
// 将新增的子节点添加到oldVnode的DOM节点上
oldVnode.elm.appendChild(newVnodeElm);
}
}
}
newVnode.elm = oldVnode.elm;
}
updateChildren.js
import createElement from "./createElement";
import patchVnode from "./patchVnode";
export default function updateChildren(parentElm, oldCh, newCh) {
let newStartIdx = 0;// 新前
let oldStartIdx = 0;// 旧前
let newEndIdx = newCh.length - 1;// 新后
let oldEndIdx = oldCh.length - 1;// 旧后
let newStartVnode = newCh[0];// 新前节点
let oldStartVnode = oldCh[0];// 旧前节点
let newEndVnode = newCh[newEndIdx];// 新后节点
let oldEndVnode = oldCh[oldEndIdx];// 旧后节点
let keyMap = null;// 保存未处理节点的key
// 循环
while (newStartIdx <= newEndIdx && oldStartIdx <= oldEndIdx) {
if (oldStartVnode == null) {
oldStartVnode = oldCh[++oldStartIdx];
}
else if (oldEndVnode == null) {
oldEndVnode = oldCh[--oldEndIdx];
} else if (newStartVnode == null) {
newStartVnode = newCh[++newStartIdx];
}
else if (newEndVnode == null) {
newEndVnode = newCh[--newEndIdx];
}
// 新前与旧前
else if (sameVnode(newStartVnode, oldStartVnode)) {
patchVnode(oldStartVnode, newStartVnode);
newStartVnode = newCh[++newStartIdx];
oldStartVnode = oldCh[++oldStartIdx];
}
// 新后与旧后
else if (sameVnode(newEndVnode, oldEndVnode)) {
patchVnode(oldEndVnode, newEndVnode);
newEndVnode = newCh[--newEndIdx];
oldEndVnode = oldCh[--oldEndIdx];
}
// 新后与旧前
else if (sameVnode(newEndVnode, oldStartVnode)) {
patchVnode(oldStartVnode, newEndVnode);
// 新后指向的节点移动到旧后之后
parentElm.insertBefore(oldStartVnode.elm, oldEndVnode.elm.nextSibling);
oldStartVnode = oldCh[++oldStartIdx];
newEndVnode = newCh[--newEndIdx];
}
// 新前与旧后
else if (sameVnode(newStartVnode, oldEndVnode)) {
patchVnode(oldEndVnode, newStartVnode);
// 新前指向的节点移动到旧前之前
parentElm.insertBefore(oldEndVnode.elm, oldStartVnode.elm);
oldEndVnode = oldCh[--oldEndVnode];
newStartVnode = newCh[++newStartIdx];
} else {
// 如果keyMap不存在,创建一个
if (!keyMap) {
keyMap = {};
for (let i = oldStartIdx; i <= oldEndIdx; i++) {
const key = oldCh[i].key;
if (key !== undefined) {
keyMap[i] = oldCh[i].key;
}
}
}
// 通过当前项的key寻找keyMap里的序号
let idxInOld = keyMap[newStartVnode.key];
let before = oldStartVnode.elm;
if (idxInOld !== undefined) {
// 旧节点里有这个节点,更新节点并移动到旧前之前
patchVnode(oldCh[idxInOld], newStartVnode);
parentElm.insertBefore(oldCh[idxInOld].elm, before);
oldCh[idxInOld] = undefined;
} else {
// 新增的节点,旧后之后
parentElm.insertBefore(createElement(newStartVnode), before);
}
newStartVnode = newCh[++newStartIdx];
}
}
// 如果新前小于新后,说明还有新增节点
if (newStartIdx <= newEndIdx) {
// 插入的位置
let before = newCh[newEndIdx + 1] == null ? null : newCh[newEndIdx + 1].elm;
for (let i = newStartIdx; i <= newEndIdx; i++) {
parentElm.insertBefore(createElement(newCh[i]), before);
}
} else if (oldStartIdx <= oldEndIdx) {
// 如果旧前小于旧后,还有删除节点
for (let j = oldStartIdx; j <= oldEndIdx; j++) {
if (oldCh[j]?.elm) {
parentElm.removeChild(oldCh[j].elm);
}
}
}
}
//判断是否是同一个节点
function sameVnode(vnode1, vnode2) {
return vnode1.sel === vnode2.sel && vnode1.key === vnode2.key
}
三、数据响应式原理
3.1 Object.defineProperty()方法
Object.defineProperty方法会直接在一个对象上定义一个新属性,或者修改一个对象的现有属性,并返回此对象。
- 该方法可以设置对象的隐藏属性(例如enumerable、writable等)。
let obj = {};
Object.defineProperty(obj, 'a', {
value: 3,
writable: false
})
Object.defineProperty(obj, 'b', {
value: 5
})
obj.a++;// wirtable为false, a属性不可以修改
console.log(obj)// {a:3, b:5}
- getter和setter
get
用作属性 getter 的函数,如果没有 getter 则为 undefined。当访问该属性时,将不带参地调用此函数,并将 this 设置为通过该属性访问的对象(因为可能存在继承关系,这可能不是定义该属性的对象)。返回值将被用作该属性的值。默认值为 undefined。
set
用作属性 setter 的函数,如果没有 setter 则为 undefined。当该属性被赋值时,将调用此函数,并带有一个参数(要赋给该属性的值),并将 this 设置为通过该属性分配的对象。默认值为 undefined。
getter和setter需要变量周转才能工作。
let obj = {};
let temp;
Object.defineProperty(obj, 'a', {
get() {
return temp;
},
set(newValue) {
temp = newValue;
}
})
Object.defineProperty(obj, 'b', {
value: 5
})
obj.a = 3;
obj.a++;
console.log(obj.a)// 4
3.2 defineReactive函数
function defineReactive(data, key, val) {
Object.defineProperty(data, key, {
configurable: true,// 可配置
enumerable: true,// 可枚举
get() {
return val;
},
set(newValue) {
if (val === newValue) {
return;
}
val = newValue;
}
})
}
let obj = {};
defineReactive(obj, 'a', 3)
obj.a++;
console.log(obj.a)// 4
3.3 递归侦测对象全部属性
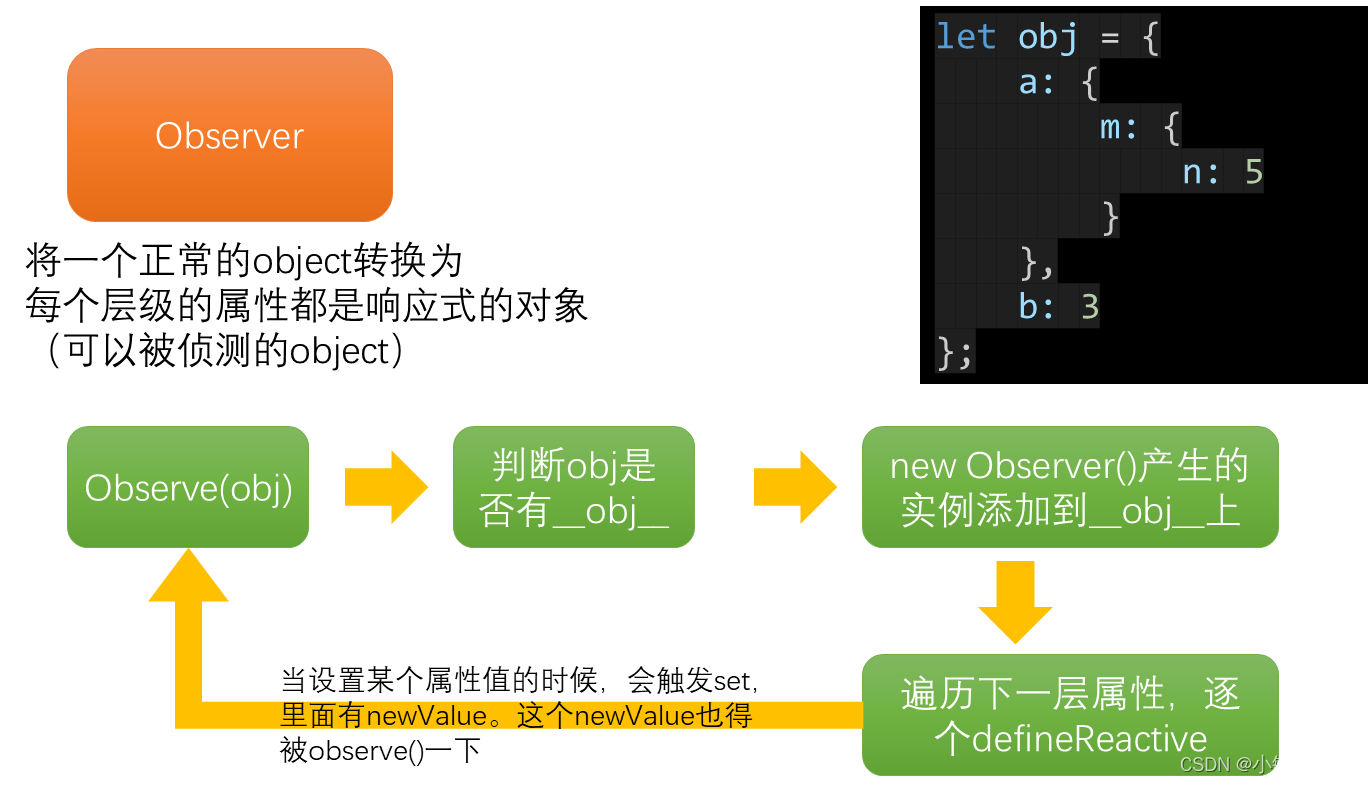
3.4 数组的响应式处理
index.js
import observe from "./observe";
let obj = {
a: {
m: {
n: 5
}
},
b: [1]
};
observe(obj);
obj.b.splice(1, 0, 2, 3, 4)
console.log(obj.b[3])
observe.js
import Observer from "./Observer";
// value是要侦测的对象
export default function observe(value) {
console.log(arguments)
// 如果value不是对象,直接返回
if (typeof value !== 'object') {
return;
}
let ob;
if (typeof value.__ob__ !== 'undefined') {
ob = value.__ob__;
} else {
ob = new Observer(value);
}
return ob;
}
Observer.js
import * as utils from "./utils";
import defineReactive from "./defineReactive";
import arrayMethods from "./array";
import observe from "./observe";
export default class Observer {
constructor(value) {
// 构造函数的this,指向实例
utils.def(value, '__ob__', this, false);
// Observer类的目的是:将一个正常的object转换为每个层级的属性都是响应式的对象(可以被侦测的object)
// 判断是数组还是对象
if (Array.isArray(value)) {
// 将数组的原型指向arrayMethods
Object.setPrototypeOf(value, arrayMethods);
this.observeArray(value);
} else {
this.walk(value)
}
}
// 遍历
walk(value) {
for (let key in value) {
defineReactive(value, key);
}
}
observeArray(arr) {
for (let i = 0; i < arr.length; i++) {
observe(arr[i]);
}
}
}
defineReactive.js
import observe from "./observe";
export default function defineReactive(data, key, val) {
if (arguments.length === 2) {
val = data[key];
}
// 子元素要进行observe,至此形成了递归。这个递归不是自己调用自己,而是多个函数嵌套调用
let childObj = observe(val);
Object.defineProperty(data, key, {
configurable: true,// 可配置
enumerable: true,// 可枚举
get() {
console.log('getter触发:'+key+'属性被访问');
return val;
},
set(newValue) {
console.log('setter触发:'+key+'属性被修改');
if (val === newValue) {
return;
}
val = newValue;
childObj = observe(newValue);
}
})
}
array.js
import { def } from './utils.js';
// 得到Array.prototype
const arrayPrototype = Array.prototype;
// 以Array.prototype为原型创建arrayMethods对象
const arrayMethods = Object.create(arrayPrototype);
// 要被改写的7个数组方法
const methodsNeedChange = [
'push',
'pop',
'shift',
'unshift',
'splice',
'sort',
'reverse'
]
methodsNeedChange.forEach(methodName => {
// 备份原来的方法
const original = arrayPrototype[methodName];
// 把这个数组身上的__ob__取出来,__ob__已经被添加了,
// 原因:因为数组不是最顶层,比如obj.b是数组,
// 第一次遍历obj这个对象的第一层的时候,已经给b属性添加了__ob__属性
// 定义新的方法
def(arrayMethods, methodName, function () {
// 调用数组方法,返回源函数的返回值
const result = original.apply(this, arguments);
const ob = this.__ob__;
// push、unshift、splice能够插入新项,将新项变为observe的
let inserted = null;// 插入的新项
switch (methodName) {
case 'push':
case 'unshift':
inserted = arguments;
break;
case 'splice':
inserted = Array.prototype.slice.call(arguments, 2);
break;
}
if (inserted) {
ob.observeArray(inserted);// 侦听新添加的项
}
console.log('methodsNeedChange');
return result;
}, false)
})
export default arrayMethods;
utils.js
// 修改obj的key属性是否可以枚举
export const def = (obj, key, value, enumerable) => {
Object.defineProperty(obj, key, {
value,
enumerable,
writable: true,
configurable: true
})
}
3.5 依赖收集
需要用到数据的地方,称为依赖。
- Vue1.x,细粒度依赖,用到数据的DOM都是依赖
- Vue2.x,中等粒度依赖,用到数据的组件都是依赖
- 在getter中收集依赖,在setter中触发依赖
Vue官方图示:
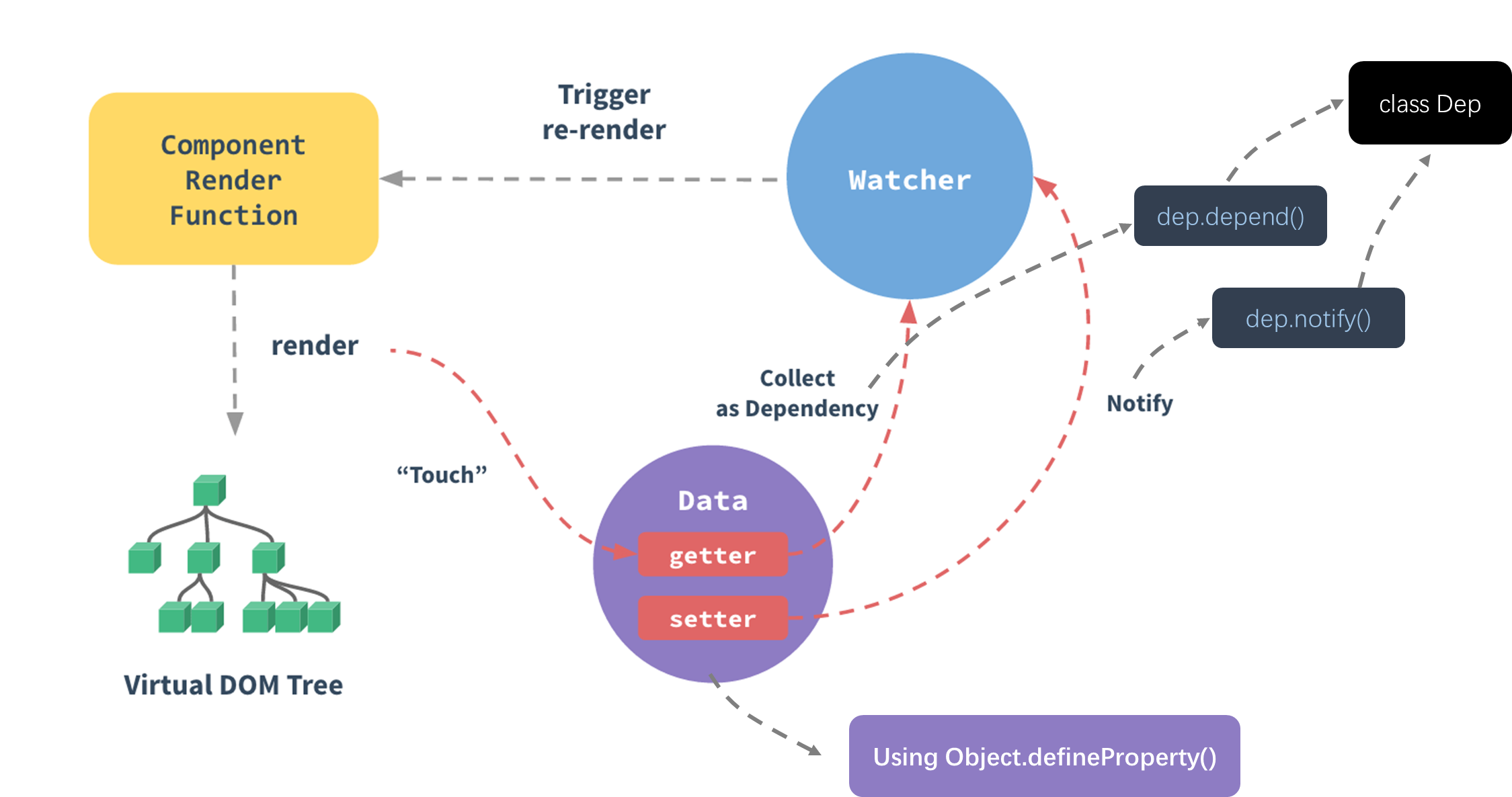
- 依赖就是watcher.只有watcher触发的getter才会收集依赖,哪个watcher触发了getter,就把哪个watcher收集到Dep中。
- Dep使用发布订阅模式,当数据发生变化时,会循环依赖列表,把所有的watcher都通知一遍。
- 代码实现的巧妙之处:watcher把自己设置到全局的一个指定位置,然后读取数据,因为读取了数据,所以会触发这个数据的getter。在getter中就能得到当前正在读取数据的watcher,并把这个watcher收集到Dep中。
理解图示:
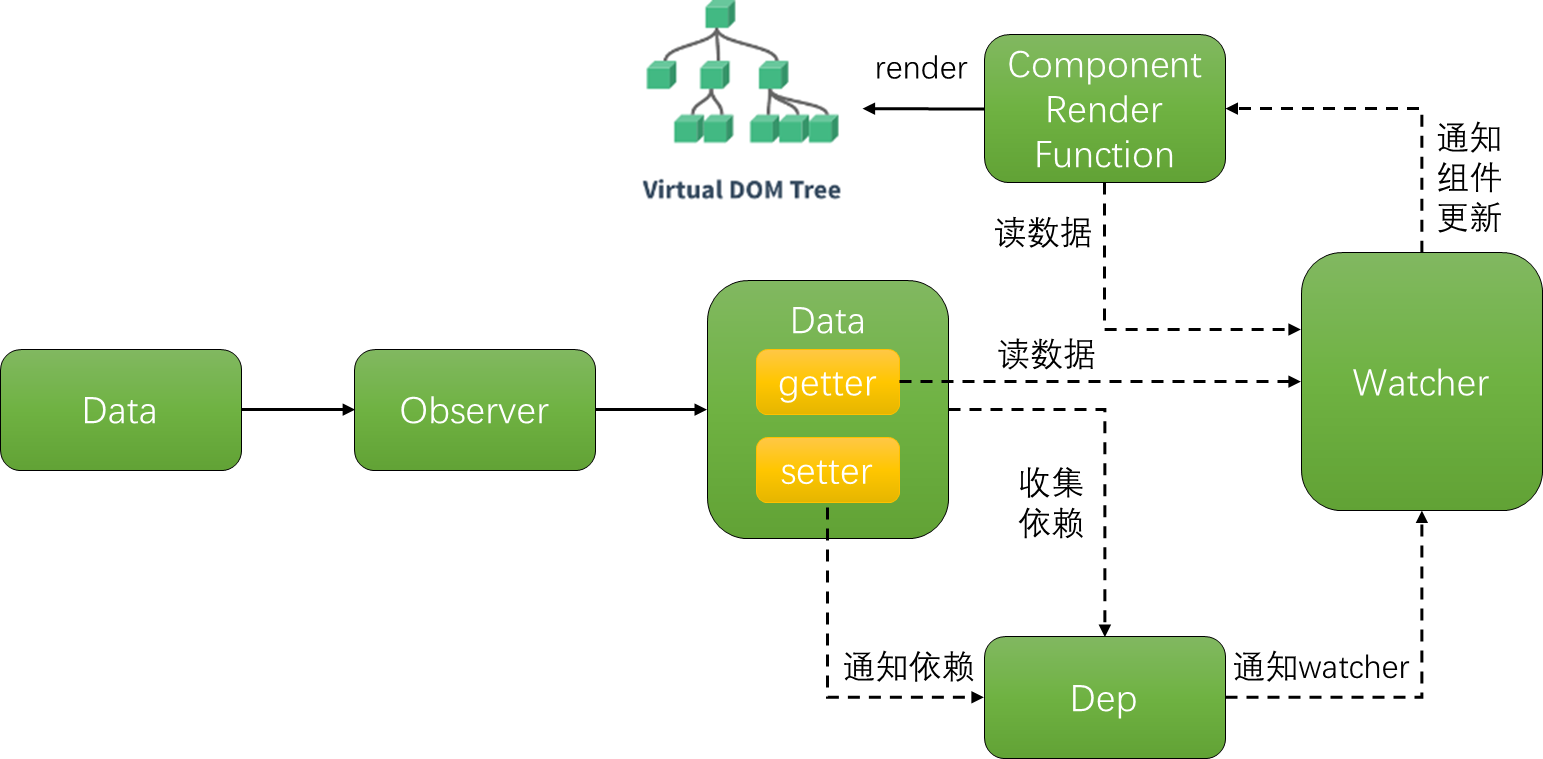
3.6 Watcher类和Dep类
- 把依赖收集的代码封装成一个Dep类,它专门用来管理依赖,每个Observer的实例成语中都有一个Dep的实例;
- Watcher是一个中介,数据发生变化时通过Watcher中转,通知组件。
四、AST抽象语法树
AST(Abstract Syntax Tree)抽象语法树本质上就是一个js对象。
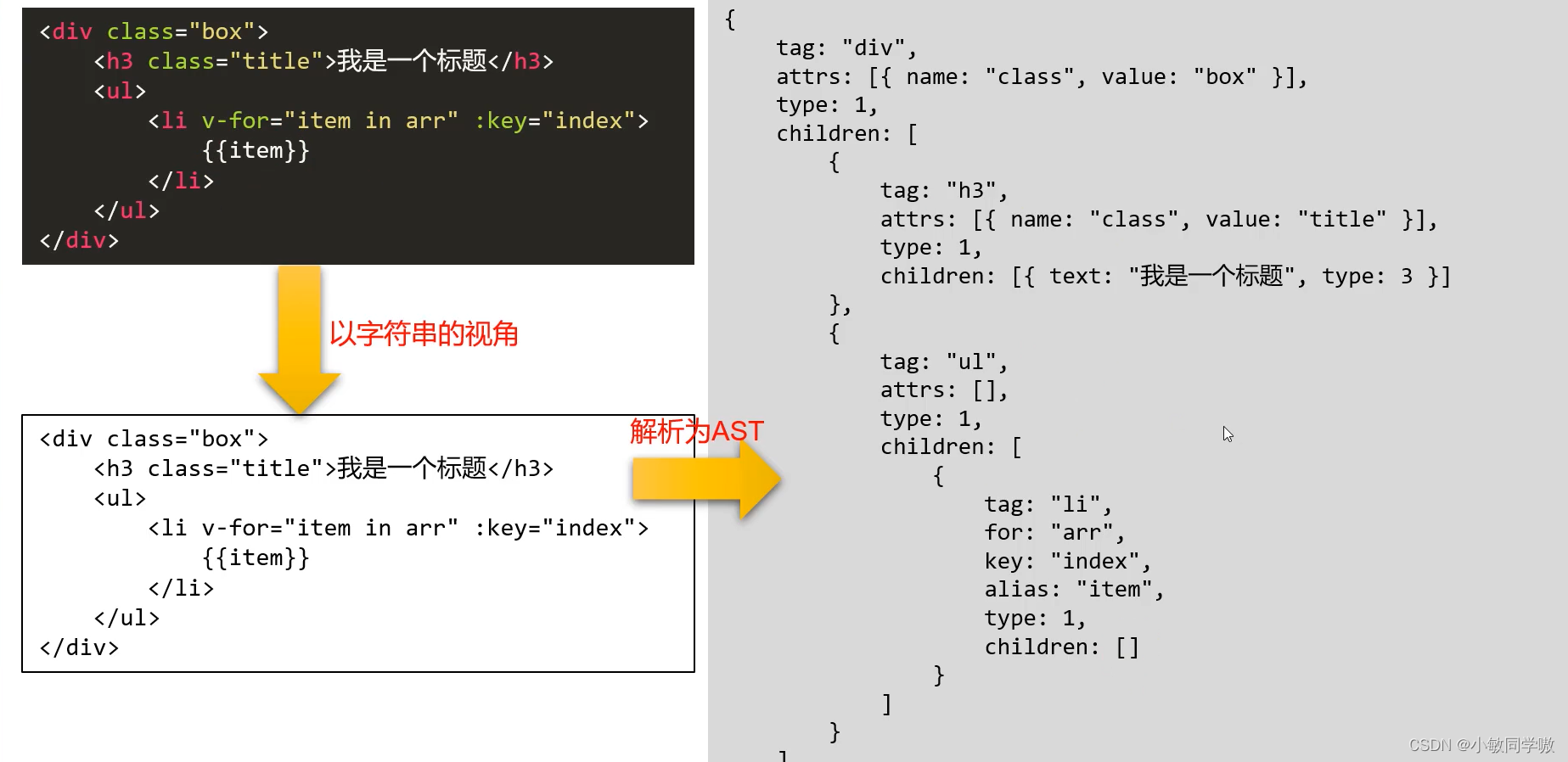
抽象语法树和虚拟节点的关系
4.1 指针思想
题目一 试图寻找字符串中,连续重复次数最多的字符。‘aaaaaabbbbbbbccccccccccccccddddd’
let str = 'aaaaaabbbbbbbccccccccccccccddddd';
console.log(findMaxRepeatChar(str));// 'c'
function findMaxRepeatChar(str) {
let i = 0;
let j = 0;
let maxRepeatCount = 0;
let maxRepeatChar = '';
while (i <= str.length - 1) {
if (str[i] !== str[j]) {
if (j - i >= maxRepeatCount) {
maxRepeatCount = j - i;
maxRepeatChar = str[i];
}
i = j;
}
j++;
}
console.log(`重复次数最多的字符是:${maxRepeatChar} 重复了${maxRepeatCount}次!`);
return maxRepeatChar;
}
4.2 递归深入例子1
输出斐波那契数列前十项
// 输出斐波那契数列前10项
function fibonacci(n) {
if (n == 0) {
return 1;
}
if (n == 1) {
return 1;
}
return fibonacci(n - 1) + fibonacci(n - 2);
}
for (let i = 0; i < 10; i++) {
let result = fibonacci(i);
console.log(`第${i}项是:${result}`);
}
上面这个方式会导致递归次数过多,例如我要计算第4项的值fibonacci(4),就会先计算fibonacci(3)和fibonacci(2),计算fibonacci(3)时又会递归计算fibonacci(2)和fibonacci(1),以此类推,会有很多不必要的递归计算,造成性能损耗。
4.3 递归深入例子2
将数组[1,2,[3,[4,5],6],7,[8],9] 变为如下对象
// 3.将数组[1,2,[3,[4,5],6],7,[8],9] 变为如下对象
/*
let obj2 = {
children: [
{ value: 1 },
{ value: 2 },
{
children: [
{ value: 3 },
{
children: [
{ value: 4 },
{ value: 5 },
]
},
{ value: 6 }
]
},
{ value: 7 },
{
children: [
{ value: 8 }
]
},
{ value: 9 }
]
}
*/
let arr = [1, 2, [3, [4, 5], 6], 7, [8], 9];
function convertArray(val) {
let result = {};
if (Array.isArray(val)) {
// 写法1
result = { children: [] }
val.forEach(item => {
result.children.push(convertArray(item));
})
// 写法2 更高级
result = {
children: val.map(item => convertArray(item))
}
} else {
result = { value: val }
}
return result;
}
console.log(convertArray(arr));
4.4 栈的简介
- 栈(stack)又名堆栈,它是一种运算受限的线性表,仅在表尾能进行插入和删除操作。这一端被称为栈顶,相对地,把另一端称为栈底。
- 向一个栈插入新元素又称作进栈、入栈或者压栈;从一个栈删除元素又称作出栈或推栈。
- 先进后出(First In Last Out)特点:栈中的元素,最先进栈的必定是最后出栈,后进栈的一定会先出栈。
- javascript中,栈可以用数组模拟。需要限制只能使用push和pop,不能使用unshift和shift。即数组尾是栈顶。
- 当然也可以用面向对象等手段,将栈封装的更好。
4.5 栈的相关算法题
题目:试编写“智能重复”smartRepeat函数,实现:
- 将3[abc]变为abcabcabc
- 将3[2[a]2[b]]变为aabbaabbaabb
- 将2[1[a]3[b]2[3[c]4[d]]]变为abbbcccddddcccddddabbbcccddddcccdddd
不用考虑输入字符串是非法的情况,比如:
- 2[a3[b]]是错误的,应该补一个1,即2[1[a]3[b]]
- [abc]是错误的,应该补一个1,即1[abc]
分析:遍历每一个字符,stack1存放数字,stack2存放字符串
- 如果这个字符是数字,那么该数字进栈stack1,把空字符进栈stack2
- 如果这个字符是字母,那么就把stack2栈顶这项改为这个字母
- 如果这个字符是],那么就将stack1栈顶数字出栈,把stack2栈顶字符重复刚刚这个数字并出栈,然后拼接到新栈顶上
let falseArray = `2[1[a]3[b]2[3[c]4[d]]]`;
function smartRepeat(templateStr) {
// 指针
let index = 0;
// 栈1 存数字
let stack1 = [];
// 栈2 存字母
let stack2 = [];
// 剩余部分
let rest = templateStr;
while (index < templateStr.length - 1) {
// 剩余部分
rest = templateStr.substring(index);
// 看当前剩余部分是不是以数字和[开头
if (/^\d+\[/.test(rest)) {
// 获取数字
let times = Number(rest.match(/^(\d+)\[/)[1]);
stack1.push(times);
stack2.push('');
index += times.toString().length + 1;
} else if (/^\w+\]/.test(rest)) {
// 如果这个字符是字母,此时把栈顶这项改为这个字母
let word = rest.match(/^(\w+)\]/)[1];
stack2[stack2.length - 1] = word;
// 指针后移
index += word.length;
} else if (rest[0] === ']') {
// 如果这个字符是],那么将stack1出栈,stack2出栈,把字符串栈的新栈顶的元素重复刚刚弹出的那个次数并拼接到新的栈顶上
let times = stack1.pop();
let word = stack2.pop();
stack2[stack2.length - 1] += word.repeat(times);
index++;
}
}
return stack2.pop().repeat(stack1.pop());
}
console.log(smartRepeat(falseArray));
4.6 AST实现原理
跟上面栈相关算法题思想一样。
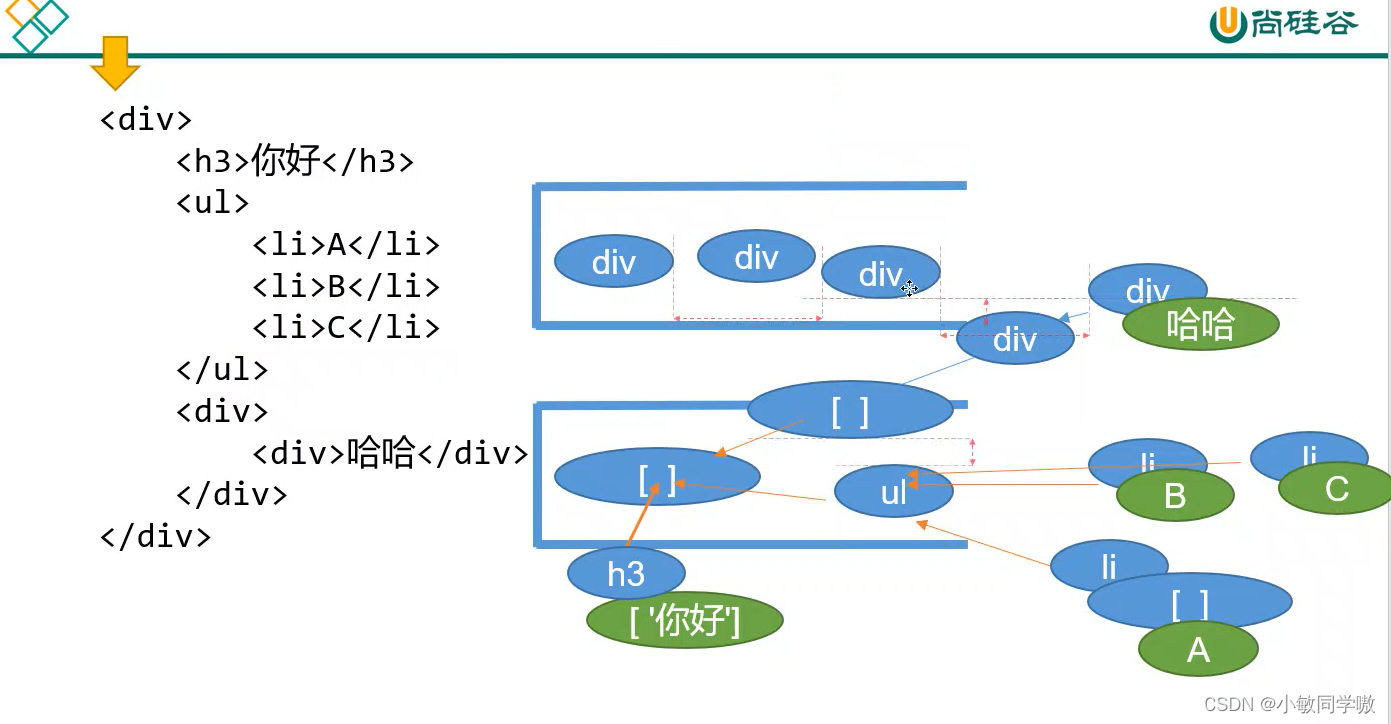
4.7 识别开始结束标记
export default function (templateStr) {
let index = 0;
let stack1 = [];// 存放标签名称
let stack2 = [];// 存放内容
let rest = templateStr;// 剩余部分
let startRegExp = /^\<([a-zA-Z]+[1-6]?)\>/;
let endRegExp = /^\<\/([a-zA-Z]+[1-6]?)\>/;
let wordRegExp = /^([^\<]+)\<\/[a-z]+[1-6]?\>/;
console.log(wordRegExp.test(rest))
while (index < templateStr.length) {
rest = templateStr.substring(index);
// 如果是 <字母> 说明是标签开始
if (startRegExp.test(rest)) {
let tag = rest.match(startRegExp)[1];
index += tag.length + 2;
} else if (endRegExp.test(rest)) {
// 如果是</字母>,说明是闭合标签
let tag = rest.match(endRegExp)[1];
index += tag.length + 3;
} else if (wordRegExp.test(rest)) {
// 文字内容
let word = rest.match(wordRegExp)[1];
if (!/^\s+$/.test(word)) {
// 不全是空格
}
index += word.length;
} else {
index++;
}
}
}
4.8 使用栈形成AST
export default function (templateStr) {
let index = 0;
let stack1 = [];// 存放标签名称
let stack2 = [];// 存放内容
let rest = templateStr;// 剩余部分
let startRegExp = /^\<([a-zA-Z]+[1-6]?)\>/;
let endRegExp = /^\<\/([a-zA-Z]+[1-6]?)\>/;
let wordRegExp = /^([^\<]+)\<\/[a-z]+[1-6]?\>/;
while (index < templateStr.length) {
rest = templateStr.substring(index);
// 如果是 <字母> 说明是标签开始
if (startRegExp.test(rest)) {
let tag = rest.match(startRegExp)[1];
stack1.push(tag);
stack2.push({ tag, type: 1, children: [] });
index += tag.length + 2;
} else if (endRegExp.test(rest)) {
// 如果是</字母>,说明是闭合标签
let tag = rest.match(endRegExp)[1];
stack1.pop();
// 如果只剩一项就不出栈了
if (stack2.length > 1) {
let pop_arr = stack2.pop();
stack2[stack2.length - 1]?.children.push(pop_arr);
}
index += tag.length + 3;
} else if (wordRegExp.test(rest)) {
// 文字内容
let word = rest.match(wordRegExp)[1];
if (!/^\s+$/.test(word)) {
// 不全是空格
stack2[stack2.length - 1].children.push({ text: word, type: 3 });
}
index += word.length;
} else {
index++;
}
}
return stack2[0];
}
4.9 识别Attrs
export default function (attrsString) {
let attrs = [];
let index = 0;
let flag = false;//是否在引号内
let words = '';
while (index < attrsString.length) {
words += attrsString[index];
if (attrsString[index] == '"' && !flag) {
// 引号开始
flag = true;
} else if (attrsString[index] == '"' && flag) {
// 引号结束
flag = false;
attrs.push(words);
words = '';
}
index++;
}
attrs = attrs.map(item => {
let name = item.split('=')[0].trim();
let value = item.split('=')[1].replace(/\"/g, '');
return {
name,
value
}
})
console.log(attrs)
return attrs;
}
五 指令和生命周期
5.1 Vue类的创建
index.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>vue-手写虚拟语法树</title>
</head>
<body>
<div id="app">
<h3 class="h3" data="3">hello</h3>
<ul>
<li>A</li>
<li>B</li>
<li>C</li>
</ul>
</div>
<script src="./js/bundle.js"></script>
<script>
new Vue({
el: '#app',
data: {
a: 10
}
});
</script>
</body>
</html>
Vue.js
import Compile from "./Compile";
export default class Vue {
constructor(options) {
// 约定成俗:_变量名是私有变量/方法 $变量名是公共API属性/方法
// 把参数options对象存为$options
this.$options = options || {};
// 数据
this._data = options.data || undefined;
// 模板编译
new Compile(options.el, this);
}
}
Compile.js
export default class Compile {
constructor(el, vue) {
// vue实例
this.$vue = vue;
// 挂载点
this.$el = document.querySelector(el);
// 如果用户传入了挂载点
if (this.$el) {
// node to fragment 就是节点变片段,片段类似与mustache里的tokens。实际上是AST抽象语法树,这里就是轻量级的,fragment
this.node2Fragment(this.$el);
}
}
node2Fragment(el) {
console.log(el)
}
}
5.2 Fragment的生成
createDocumentFragment() 方法创建了一虚拟的节点对象,节点对象包含所有属性和方法。
当你想提取文档的一部分,改变,增加,或删除某些内容及插入到文档末尾可以使用createDocumentFragment() 方法。
你也可以使用文档的文档对象来执行这些变化,但要防止文件结构被破坏,createDocumentFragment() 方法可以更安全改变文档的结构及节点。
export default class Compile {
constructor(el, vue) {
// vue实例
this.$vue = vue;
// 挂载点
this.$el = document.querySelector(el);
// 如果用户传入了挂载点
if (this.$el) {
// node to fragment 就是节点变片段,片段类似与mustache里的tokens。实际上是AST抽象语法树,这里就是轻量级的,fragment
let $fragment = this.node2Fragment(this.$el);
// 编译
this.compile($fragment);
}
}
// 节点变为fragment片段
node2Fragment(el) {
let fragment = document.createDocumentFragment();
let child;
// 让所有DOM节点进入fragment,进入fragment后页面上的DOM结构就消失了
while (child = el.firstChild) {
fragment.appendChild(child);
}
return fragment;
}
// 编译fragment片段
compile(el) {
let childNodes = el.childNodes;
let self = this;
childNodes.forEach(node => {
switch (node.nodeType) {
case 1:
self.compileElement(node);
break;
case 3:
let text = node.textContent;
self.compileText();
break;
}
})
}
compileElement(node) {
// 这里的方便之处在于不是将HTML结构看作字符串,而是真正的属性列表
let nodeAttrs = node.attributes;
Array.prototype.slice.call(nodeAttrs).forEach(attr => {
// 分析指令
let attrName = attr.name;
let attrValue = attr.value;
// 判断当前attr是否是指令
if (attrName.indexOf('v-') == 0) {
// v-开头的就是指令
let dir = attrName.substring(2);
switch (dir) {
// 判断具体是什么指令,做指令处理
case 'model':
// v-model 双向数据绑定
break;
case 'for':
// v-for
break;
}
}
})
}
compileText() {
}
}
5.3 初始数据的响应式和watch
import Compile from "./Compile";
import Watcher from "./reactive/Watcher";
import observe from "./reactive/observe";
export default class Vue {
constructor(options) {
// 约定成俗:_变量名是私有变量/方法 $变量名是公共API属性/方法
// 把参数options对象存为$options
this.$options = options || {};
// 数据
this._data = options.data || undefined;
// 侦测data的变化
observe(this._data);
// data变成响应式的,这里就是生命周期
this._initData();
this._initWatch();
// 模板编译
new Compile(options.el, this);
}
_initData() {
let self = this;
// 遍历data的所有key
Object.keys(this._data).forEach(key => {
Object.defineProperty(self, key, {
get() {
return self._data[key];
},
set(value) {
self._data[key] = value;
}
})
})
}
_initWatch() {
let self = this;
// 遍历watch所有key
Object.keys(this.$options.watch).forEach(key => {
new Watcher(self, key, self.$options.watch[key]);
})
}
}
5.4 识别双大括号并watch
通过正则表达式匹配let reg = /\{\{(.*)\}\}/
5.5 v-model的实现
import Watcher from "./reactive/Watcher";
export default class Compile {
constructor(el, vue) {
// vue实例
this.$vue = vue;
// 挂载点
this.$el = document.querySelector(el);
// 如果用户传入了挂载点
if (this.$el) {
// node to fragment 就是节点变片段,片段类似与mustache里的tokens。实际上是AST抽象语法树,这里就是轻量级的,fragment
let $fragment = this.node2Fragment(this.$el);
// 编译
this.compile($fragment);
// 替换好的内容要上树
this.$el.appendChild($fragment);
}
}
// 节点变为fragment片段
node2Fragment(el) {
let fragment = document.createDocumentFragment();
let child;
// 让所有DOM节点进入fragment,进入fragment后页面上的DOM结构就消失了
while (child = el.firstChild) {
fragment.appendChild(child);
}
return fragment;
}
// 编译fragment片段
compile(el) {
let childNodes = el.childNodes;
let self = this;
childNodes.forEach(node => {
switch (node.nodeType) {
case 1:
self.compileElement(node);
if (node.childNodes) {
self.compile(node);
}
break;
case 3:
let text = node.textContent;
let reg = /\{\{(.*)\}\}/;
if (reg.test(text)) {
self.compileText(node, text.match(reg)[1]);
}
break;
}
})
}
compileElement(node) {
// 这里的方便之处在于不是将HTML结构看作字符串,而是真正的属性列表
let nodeAttrs = node.attributes;
let self = this;
Array.prototype.slice.call(nodeAttrs).forEach(attr => {
// 分析指令
let attrName = attr.name;
let attrValue = attr.value;
// 判断当前attr是否是指令
if (attrName.indexOf('v-') == 0) {
// v-开头的就是指令
let dir = attrName.substring(2);
switch (dir) {
// 判断具体是什么指令,做指令处理
case 'model':
// v-model 双向数据绑定
let value = self.getVueVal(self.$vue, attrValue);
node.value = value;
new Watcher(self.$vue, attrValue, value => {
node.value = value;
});
node.addEventListener('input', e => {
let newVal = e.target.value;
self.setVueVal(self.$vue, attrValue, newVal);
console.log(`----------------input--------------`);
});
break;
case 'for':
// v-for
break;
}
}
})
}
// 编译文本
compileText(node, name) {
let value = this.getVueVal(this.$vue, name);
// 将节点的textContent由模板{{a}}替换为真实数据
node.textContent = value;
// 监听数据变化
new Watcher(this.$vue, name, value => {
node.textContent = value;
})
}
getVueVal(vue, exp) {
// 拿到vue实例中对应的数据
let val = vue;
return parsePath(exp)(val);
}
setVueVal(vue, exp, newValue) {
let val = vue;
// 设置vue实例对应的数据
exp = exp.split('.');
exp.forEach((key, index) => {
if (index === exp.length - 1) {
val[key] = newValue;
} else {
val = val[key];
}
})
}
}
let parsePath = (str) => {
let strArr = str.split('.');
return (obj) => {
for (let i = 0; i < strArr.length; i++) {
if (!obj) return;
obj = obj[strArr[i]]
}
return obj;
}
}



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









