







一、RDD
RDD和IO之间的关系
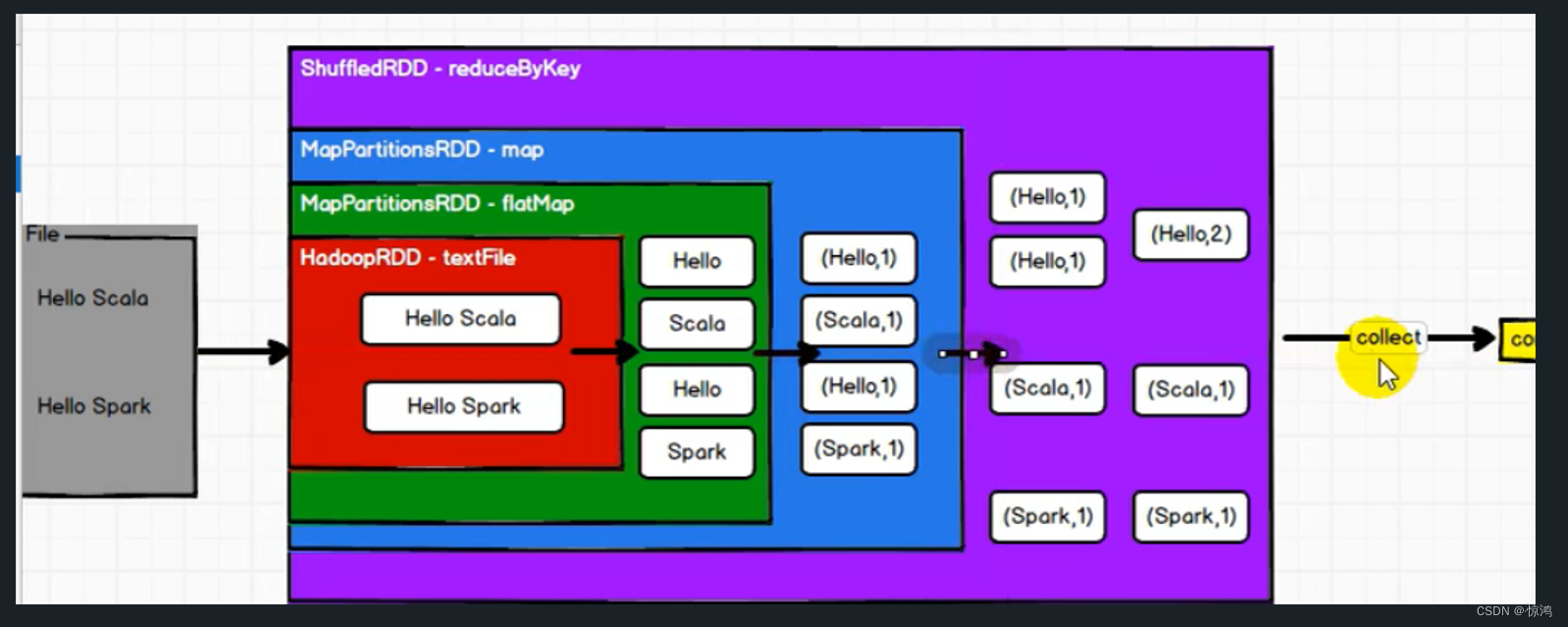
- RDD的数据处理方式类似于IO流,也有装饰着设计模式
- RDD的数据只有在执行collect方法时才会真正的执行业务逻辑操作
- RDD是不保存数据的,但是我们的IO可以临时保存一部分数据
RDD的特点
RDD叫做弹性分布式数据集,是Spark中最基本的数据处理模型。代码中是一个抽象类,他代表一个弹性的、不可变的、可分区的,里面的原元素可以并行计算的集合。


在这里插入图片描述
五大核心属性
- 分区列表
RDD数据结构中存在分区列表,用于执行任务时并行计算,是实现分布式计算的重要属性 - 分区计算函数
Spark在进行计算的时候,是使用分区函数对每一个分区进行计算 - RDD之间的依赖关系
RDD是计算模型的封装,当需求中需要把多个计算模型进行组合时,就需要将多个RDD建立依赖关系 - key- value数据类型的RDD分区器
一个Partitioner,即RDD的分区函数(可选项),Partitioner函数不但决定了RDD本身的分片数量,也决定了parent RDD Shuffle输出时的分片数量。 - 每个分区都有一个优先位置列表,即首选位置( a list of preferred locations to compute each split on)
存储每个切片优先(preferred location)位置的列表。 比如对于一个 HDFS 文件来说, 这个列表保存的就是每个 Partition 所在文件块的位置.。按照“移动数据不如移动计算”的理念, Spark 在进行任务调度的时候, 会尽可能地将计算任务分配到其所要处理数据块的存储位置。
RDD的创建
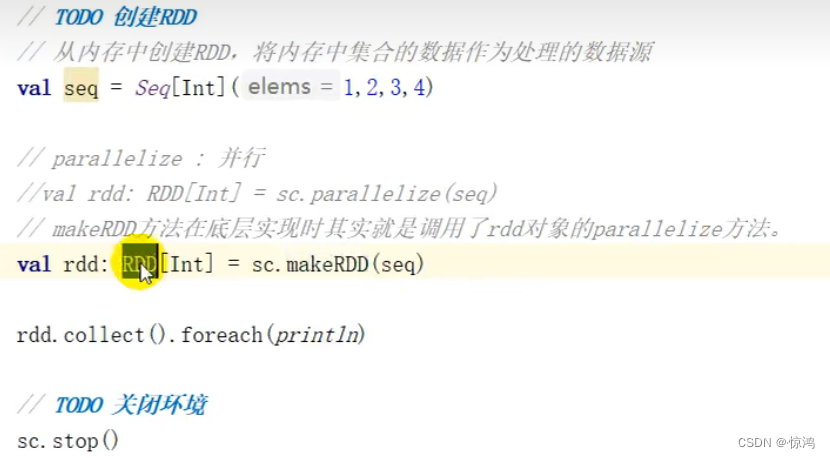
- 从集合\内存中创建RDD
parallelize 与 makeRDD
makeRDD 在底层实现时就是调用了rdd对象的parallezize方法
1
2
3
4
- 从文件中创建RDD

testfile :从文件中读取数据
wholeTextFiles:以文件为单位读取数据


-
从其他RDD创建
-
new一个RDD
RDD的并行度与分区
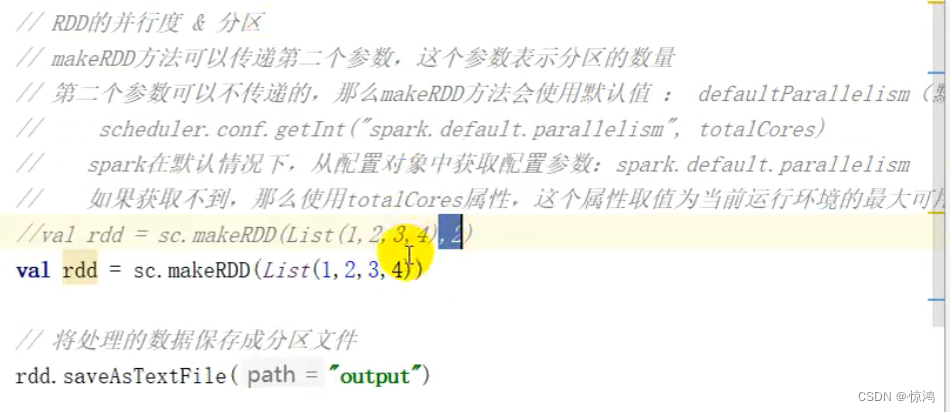
默认分区数是自己cpu的核心数
可以自定义分区数
sparkConf.set("spark.default.parallelism","分区数")

RDD分数数据的装配
范围计算公式:
(start,end)
start:当前的分区号
i是我们的数据
简单来说就是:
- 我们分区的数据范围是把我们当前的分区编号,如 0号,带入我们的计算公式





















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











