







 本文详细介绍了数据统计分析中的关键概念,包括均值、平均值、中位数、众数、极差、方差、标准差、协方差和四分位数等。通过实例展示了如何使用Python计算这些统计量,并探讨了同比和环比的区别。此外,还提到了卡方值在非参数检验中的应用。
本文详细介绍了数据统计分析中的关键概念,包括均值、平均值、中位数、众数、极差、方差、标准差、协方差和四分位数等。通过实例展示了如何使用Python计算这些统计量,并探讨了同比和环比的区别。此外,还提到了卡方值在非参数检验中的应用。
数据描述统计分析
无序数据
均值
均值:算数平均数,描述平均水平。
例:某次数学考试中,小组A与小组B的成员的乘机分别如下:
A:70,85,62,98,92
B:82,87,95,80,83
分别求出两组的平均分,并比较两组的成绩。
组A:
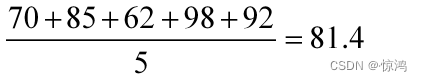
组B:
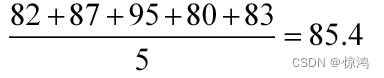
组B的平均分比组A的高,就是组B的总体成绩比组A高。
import numpy as np
a = [5, 6, 16, 9]
print(np.mean(a)) # 9.0
均值(mean)和平均值(average)的区别
- 均值(mean)是对恒定的真实值进行测量后,把测量偏离于真实值的所有值进行平均所得的结果;
- 平均值(average)是直接对一系列具有内部差异的数值进行的测量值进行的平均结果。
- 均值是“观测值的平均”
- 平均值是“统计量的平均”。
举个例子:
例如一个人的身高的真实值是180,但利用不同的仪器或者同一个仪器经过多次测量,有181,179,182,180等,把多次测量的这些所有数字进行平均,就是均值。
一个班级有30个学生,测量每个学生的身高,把这30个学生测量的30个身高数字进行平均,所得的结果就是平均值。
均值有一个真实值存在作为参考,而平均值没有一个真实值的存在,只是差异性的平均结果。
中位数(中值)
中位数:将数据按大小顺序(从大到小或是从小打大都可以)排列后位于中间位置的数。
例:58,32,46,92,73,88,,23,22
1、先排序:23,32,46,58,73,88,92
2、找出处于中间位置的数:23,32,46,58,73,88,92
- 若处于中间位置的数据有两个(也就是数据的总个数为偶数时),中位数为
中间两个数的算术平均数
假如有n个数据,
- 当n为偶数时,中位数为 第n/2位数 和 第(n+2)/2位数 的平均数
- 当n为奇数,那么中位数为 第(n+1)/2 得到的位置值,例子中为4,即58。
众数
数据中出现最多的数(所占比例最大的数)
一组数据中,可能存在多个众数,也可能不存在众数。
1 2 2 3 3 中的众数是2和3
1 2 3 4 5 中没有众数
众数不仅适用于数值型数据,对于非数值型数据也同样适用。
{苹果,苹果,香蕉,橙,橙,橙,桃},这一组数据,没有什么均值、中位数可言,但是存在着众数——橙。
极差
极差:最大值-最小值,简单地描述数据的范围大小,极差越大越分散。
方差(离均差平方)
方差=平方的均值减去均值的平方
在统计学上,更常的是使用方差
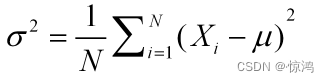
来描述数据的离散程度——数据离中心越远越离散。
方差是各个数据与平均数之差的平方的和的平均数,即
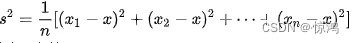
其中,x表示样本的平均数,n表示样本的数量,xi表示个体,而s2就表示方差。
例:
有 1、2、3、4、5这组样本,其平均数为(1+2+3+4+5)/5=3,而方差是各个数据分别与其和的平均数之差的平方的和的平均数,则为:
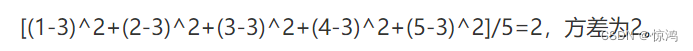
方差是和中心偏离的程度,用来衡量一批数据的波动大小(即这批数据偏离平均数的大小)并把它叫做这组数据的方差,记作S2。
import numpy as np
a = [5, 6, 16, 9]
var = np.var(a)
print(var) # 18.5
标准差(标准偏差、实验标准差、均方差)
-
标准差(Standard Deviation) ,数学术语,是离均差平方的算术平均数(即:方差)的算术平方根,用σ表示。
-
在概率统计中最常使用作为统计分布程度上的测量依据。
-
标准差是方差的算术平方根,标准差能反映一个数据集的离散程度。平均数相同的两组数据,标准差未必相同。 -
标准差可以反映平均数不能反映出的东西(比如稳定度等)。
求解方法:
所有数减去其平均值的平方和,所得结果除以该组数之个数(或个数减一,即变异数),再把所得值开根号,所得之数就是这组数据的标准差。
也就是 标准差 = 方差的算术平方根
import numpy as np
a = [5, 6, 16, 9]
std = np.std(a)
std2 = np.std(a, ddof=1)
print(std)
print(std2)
协方差
- 协方差:度量两个随机变量关系的统计量 or 在概率论和统计学中用于衡量两个变量的总体误差
- 而方差是协方差的一种特殊情况,即当两个变量是相同的情况。
- 协方差物理意义:衡量两个随机变量的相关性
求协方差
cov(x,y) = EXY - EX * EY
例子:
Xi 1.1 1.9 3
Yi 5.0 10.4 14.6
E(X) = (1.1 + 1.9 + 3)/3 = 2
E(Y) = (5.0 + 10.4 + 14.6)/3 = 10
EXY(1.1 * 5.0 + 1.9 * 10.4 + 3 * 14.6) /3 =23.02
cov(x,y) = EXY - EX*EY
= 23.02- 2 *10
=3.02
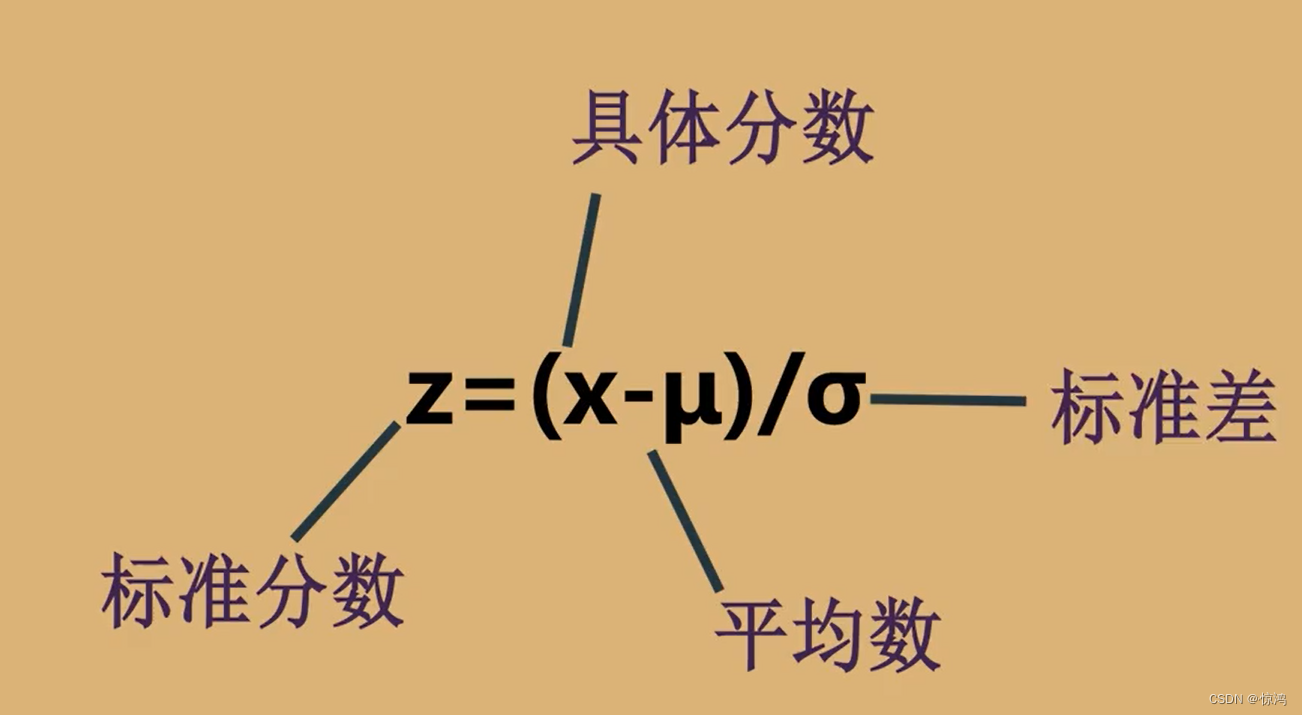
标准分
标准分,是一种由原始分推导出来的相对地位量数,它是用来说明原始分在所属的那批分数中的相对位置的。
考生在接受测验后,按照评分标准对其作答反应直接评出来的分数,叫原始分。
原始分反映了考生答对题目的个数,或作答正确的程度。但是,原始分一般不能直接反映出考生间差异状况,不能刻划出考生相互比较后所处的地位,也不能说明考生在其他等值测试上应获得什么样的分值。
公式
四分位数
四分位数(Quartile)也称四分位点,是指在统计学中把所有数值由小到大排列并分成四等份,处于三个分割点位置的数值。- 多应用于统计学中的箱线图绘制。
它是一组数据排序后处于25%和75%位置上的值。
- 四分位数是通过3个点将全部数据等分为4部分,其中每部分包含25%的数据
分位数是将总体的全部数据按大小顺序排列后,处于各等分位置的变量值。
- 如果将全部数据分成相等的两部分,它就是中位数;
- 如果分成四等分,就是四分位数;
- 八等分就是八分位数等。
四分位数也称为四分位点,它是将全部数据分成相等的四部分,其中每部分包括25%的数据,处在各分位点的数值就是四分位数。
四分位数有三个,第一个四分位数就是通常所说的四分位数,称为下四分位数,第二个四分位数就是中位数,第三个四分位数称为上四分位数,分别用Q1、Q2、Q3表示 。
- 第一四分位数 (Q1),又称“较小四分位数”,等于该样本中所有数值由小到大排列后第25%的数字。
- 第二四分位数 (Q2),又称“中位数”,等于该样本中所有数值由小到大排列后第50%的数字。
- 第三四分位数 (Q3),又称“较大四分位数”,等于该样本中所有数值由小到大排列后第75%的数字。
- 第三四分位数与第一四分位数的差距又称四分位距(InterQuartile Range,IQR)。
实例
首先确定四分位数的位置:
n表示项数
- Q1的位置= (n+1) × 0.25
- Q2的位置= (n+1) × 0.5
- Q3的位置= (n+1) × 0.75
对于四分位数的确定,有不同的方法,另外一种方法基于N-1 基础。即
- Q1的位置=1+(n-1)x 0.25
- Q2的位置=1+(n-1)x 0.5
- Q3的位置=1+(n-1)x 0.75
四分位间距
Q3 - Q1 = 上四分位数 - 下四分位数
有序数据
同比
同比一般情况下是本年第n月与过去某年的第n月比。同比发展速度主要是为了消除季节变动的影响,用以说明本期发展水平与同期发展水平对比而达到的相对发展速度。
如
- 本期2月比同期2月,本期6月比同期6月等。
同比发展速度,其计算公式为:本期发展水平/同期水平×100%同比增长,其计算公式为:(本期发展水平-同期水平)/同期发展水平×100%
在实际工作中,经常使用这个指标,如某年、某季、某月与同期对比计算的发展速度,就是同比发展速度。
环比
- 环比,统计学术语,是表示连续2个统计周期(比如连续两月)内的量的变化比。
- 环比的发展速度是
报告期水平与前一时期水平之比,表明现象逐期的发展速度。
如计算一年内各月与前一个月对比,即2月比1月,3月比2月,4月比3月……12月比11月,说明逐月的发展程度。如分析抗击“非典”期间某些经济现象的发展趋势,环比比同比更说明问题。
分类
发展速度由于采用基期的不同,可分为同比发展速度、环比发展速度和定基发展速度。均用百分数或倍数表示。环比分为日环比、周环比、月环比和年环比
定基比(定比)
环比发展速度,一般指是指报告期水平与前一时期水平之比,表明现象逐期的发展速度。
同比和环比的区别
概念
- 「同比」
与历史「同时期]比较,例如2011年3月份与2010年3月份相比,叫「同比」。
- 「环比」
与「上一个」统计周期比较,例如2011年4月份与2011年3月份相比较,称为「环比」。
- 反映的都是「变化速度」,但由于采用「基期」的不同,其反映的内涵是完全不同的;
-
一般来说,环比可以与环比相比较,而不能拿「同比」与「环比」相比较;
-
而对于同一个地方,考虑时间纵向上发展趋势的反映,则往往要把「同比」与「环比」放在一起进行对照。
计算公式
1、本期「环比」增长(下降)率计算公式
-
环比分为日环比、周环比、月环比和年环比。
-
本期环比增长(下降)率(%) = (本期价格/上期价格 — 1 )× 100%
-
(1)如果计算值为正值(+),则称增长率;如果计算值为负值(-),则称下降率。
-
(2)如果本期指本日、本周、本月和本年,则上期相应指上日、上周、上月和上年。
2、本期同比增长(下降)率计算公式
-
本期同比增长(下降)率(%) = (本期价格/上年同期价格 —1) × 100%
-
(1)如果计算值为正值(+),则称增长率;如果计算值为负值(-),则称下降率。
-
(2)如果本期指本日、本周和本月,则上年同期相应指上年同日、上年同周和上年同月。
发展数据分类
发展速度由于采用基期的不同,可分以下三类(均用百分数或倍数表示)
- 「定基比发展速度」
- 也简称总速度,一般是指报告期水平与某一固定时期水平之比,表明这种现象在较长时期内总的发展速度。
- 「同比发展速度」
- 主要是为了消除季节变动的影响,用以说明本期发展水平与去年同期发展水平对比而达到的相对发展速度。如,今年4月比去年4月。
- 「环比发展速度」
- 以报告期水平与其前一期水平对比(相邻期间的比较),所得到的动态相对数。表明现象逐期的发展变动程度。如计算一年内各月与前一个月对比,即月环比。
两个(包含)以上无序数据集
卡方值
- 卡方值是非参数检验中的一个统计量,主要用于非参数统计分析中,
- 它是卡方检验中的一个主要测试指标,卡方检验是一种用途很广的计数资料的假设检验方法,它属于非参数检验的范畴,
- 主要是比较两个及两个以上样本率( 构成比)以及两个分类变量的关联性分析,其根本思想就是在于比较理论频数和实际频数的吻合程度或拟合优度问题。
---------------------------------------------代码实例----------------------------------------------------------
Python
# -*- coding: utf-8 -*-
# @Time : 2022/8/20 18:57
# @Author : 蒋歡
# @Email : 1963855603@qq.com
import pandas as pd
import numpy as np
a = [5, 6, 16, 9]
# # 计算平均值 mean
# print(np.mean(a))
## 9.0
# # 方差 var
# print(np.var(a))
## 18.5
# # 标准差 std
# print(np.std(a))
## 4.301162633521313
#中位数 ,median
# print(np.median(a))
# 7.5
## 众数
# print(df.mode())
#---------------------------------实例-----------------------------------------------------------
df = pd.DataFrame(data = np.random.randint(0,100,size = (5,3)),
index = list('ABCDE'),
columns=['Python','Tensorflow','Keras'])
# df.describe() # 查看数值型列的汇总统计,计数、平均值、标准差、最⼩值、四分位数、最⼤值
# print(df)
# print(df.describe())
# # 2、索引位置
# # 计算最⼩值位置
# print(df['Python'].argmin() )
# print()
# # 最⼤值位置
# print(df['Keras'].argmax())
# print()
# # 最⼤值索引标签
# print(df.idxmax())
# print()
# # 最⼩值索引标签
# print(df.idxmin())
print(df)
# 3、更多统计指标
# print(df['Python'].value_counts() )# 统计元素出现次数
# 30 1
# 85 1
# 42 1
# 90 1
# 48 1
# print(df['Keras'].unique()) # 去重
# Python Tensorflow Keras
# A 32 35 25
# B 60 19 36
# C 8 34 14
# D 53 2 6
# E 77 83 78
# 去重
# [25 36 14 6 78]
# print(df.cumsum() )# 累加
# Python Tensorflow Keras
# A 68 8 67
# B 39 68 3
# C 43 83 64
# D 3 51 85
# E 80 88 5
# # 累加
# Python Tensorflow Keras
# A 68 8 67
# B 107 76 70
# C 150 159 134
# D 153 210 219
# E 233 298 224
# print(df.cumprod() )# 累乘
# Python Tensorflow Keras
# A 70 20 42
# B 4 10 1
# C 55 38 87
# D 1 96 65
# E 33 32 88
# Python Tensorflow Keras
# A 70 20 42
# B 280 200 42
# C 15400 7600 3654
# D 15400 729600 237510
# E 508200 23347200 20900880
# print(df.std())# 标准差
# Python 47.777610
# Tensorflow 23.880955
# Keras 39.389085
# dtype: float64
# print(df.var()) # ⽅差
# Python 1218.7
# Tensorflow 625.7
# Keras 1320.3
# dtype: float64
# print(df.cummin()) # 累计最⼩值
# print(df.cummax()) # 累计最⼤值
# Python Tensorflow Keras
# A 44 78 28
# B 14 17 28
# C 9 17 28
# D 9 17 26
# E 9 17 26
# Python Tensorflow Keras
# A 44 78 28
# B 44 78 44
# C 44 78 66
# D 55 82 66
# E 92 82 87
# print(df.diff()) # 计算差分 下一行减去上一行
# Python Tensorflow Keras
# A 26 41 53
# B 74 19 34
# C 5 86 11
# D 40 61 25
# E 44 79 51
# Python Tensorflow Keras
# A NaN NaN NaN
# B 48.0 -22.0 -19.0
# C -69.0 67.0 -23.0
# D 35.0 -25.0 14.0
# E 4.0 18.0 26.0
# print(df.pct_change())# 计算百分⽐变化
# Python Tensorflow Keras
# A 49 92 1
# B 49 58 51
# C 64 60 35
# D 95 77 45
# E 72 17 24
# Python Tensorflow Keras
# A NaN NaN NaN
# B 0.000000 -0.369565 50.000000
# C 0.306122 0.034483 -0.313725
# D 0.484375 0.283333 0.285714
# E -0.242105 -0.779221 -0.466667



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











