






 本文整理了前端面试中关于事件和DOM的常见问题,包括DOM的数据结构、常用API、attribute与property的区别、性能优化策略、浏览器类型识别、URL分析、事件绑定与冒泡原理等,旨在帮助面试者巩固前端基础知识。
本文整理了前端面试中关于事件和DOM的常见问题,包括DOM的数据结构、常用API、attribute与property的区别、性能优化策略、浏览器类型识别、URL分析、事件绑定与冒泡原理等,旨在帮助面试者巩固前端基础知识。
前言
根据慕课网的《快速搞定前端技术一面 匹配大厂面试要求》课程所整理的题目,陆续更新。如果你觉得本文相关知识点你已经掌握,你可以查看我之前的相关文章哦
常考面试题
1.DOM是哪种数据结构?
DOM树,树结构
- DOM本质是一棵树,是HTML解析出来的一棵树
2.DOM操作的常用API
此处只列举说明,不具体展示API用法,参考自JavaScript操作DOM常用的API,感兴趣的可以去看这篇文章学习具体用法
2.1 Node
- Element提供了对元素标签名,子节点和特性的访问,我们常用HTML元素比如div,span,a等标签就是element中的一种
- Text表示文本节点,它包含的是纯文本内容,不能包含html代码,但可以包含转义后的html代码
- Comment表示HTML文档中的注释
- Document表示文档,在浏览器中,document对象是HTMLDocument的一个实例,表示整个页面,它同时也是window对象的一个属性
- DocumentFragment是所有节点中唯一一个没有对应标记的类型,它表示一种轻量级的文档,可能当作一个临时的仓库用来保存可能会添加到文档中的节点
2.2 节点创建型API
- createElement通过传入指定的一个标签名来创建一个元素,如果传入的标签名是一个未知的,则会创建一个自定义的标签
- createTextNode用来创建一个文本节点,接收一个参数,这个参数就是文本节点中的文本
- cloneNode返回调用该方法的节点的一个副本
- DocumentFragments 是DOM节点。它们不是主DOM树的一部分。通常的用例是创建文档片段,将元素附加到文档片段,然后将文档片段附加到DOM树。在DOM树中,文档片段被其所有的子元素所代替。
因为文档片段存在于内存中,并不在DOM树中,所以将子元素插入到文档片段时不会引起页面回流(reflow)(对元素位置和几何上的计算)。因此,使用文档片段document fragments 通常会起到优化性能的作用(后文优化有提到)
2.3 页面修改型API
- appendChild我们在前面已经用到多次,就是将指定的节点添加到调用该方法的节点的子元素的末尾
- insertBefore用来添加一个节点到一个参照节点之前
- removeChild 删除指定的子节点并返回
- replaceChild用于使用一个节点替换另一个节点
2.4 节点查询型API
- document.getElementById 这个接口很简单,根据元素id返回元素,返回值是Element类型,如果不存在该元素,则返回null
- document.getElementsByTagName 返回一个包括所有给定标签名称的元素的HTML集合HTMLCollection。 整个文件结构都会被搜索,包括根节点。返回的 HTML集合是动态的, 意味着它可以自动更新自己来保持和 DOM 树的同步
- document.getElementsByName 主要是通过指定的name属性来获取元素,它返回一个即时的NodeList对象
- document.getElementsByClassName 这个API是根据元素的class返回一个即时的HTMLCollection
- document.querySelector返回第一个匹配的元素,如果没有匹配的元素,则返回null
- document.querySelectorAll 返回的是所有匹配的元素,而且可以匹配多个选择符
3.attribute和property的区别
- property:修改的为js内部变量形式,通过操作对象属性的形式来操作固有属性,不会对标签产生影响,不会提现到HTML结构上(尽量使用这个)
- attribute:修改的为HTML属性,可用来操作自定义属性,标签上会有你设置的"属性",可修改内嵌样式,会改变HTML结构
- 以上两者都可能引起DOM重新渲染,但是我们要尽量使用property,因为property可以避免一些不必要的DOM渲染,而用attribute会改变HTML结构,会引起DOM的重新渲染,耗费不必要的性能资源
- 详细可以看看这篇文章前端杂谈: Attribute VS Property
Style如下
<style>
.container {
border: 1px soild #ccc
}
.red {
color:red
}
</style>
HTML结构如下
<div id="div1" class="container">
<p>一段文字 1</p>
<p>一段文字 2</p>
<p>一段文字 3</p>
</div>
// 获取p节点
const pList = document.querySelectorAll('p')
const p1 = pList[0]
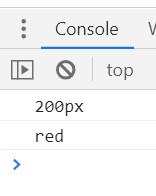
①property修改样式
p1.style.height = '200px'
console.log(p1.style.height)
p1.className = 'red'
console.log(p1.className)
观察网页的更改,以及控制台输出。可以看到,网页的样式都已经被修改了

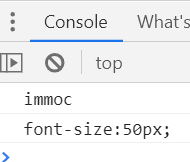
②attribute修改样式
// 自定义标签属性
p1.setAttribute('data-name:','immoc')
console.log( p1.getAttribute('data-name:') )
// set、get形式
p1.setAttribute('style','font-size:50px;')
console.log( p1.getAttribute('style') )
观察网页的更改、HTML标签以及控制台输出。可以看到字体大小改变了,且标签中多了一个自定义属性


4.一次性插入多个DOM节点,如何考虑性能
DOM性能?如何优化?
- DOM操作非常"昂贵",此处的昂贵即耗费性能,所以要避免频繁的DOM操作
- 对DOM查询做缓存
- 将频繁的DOM操作改为一次性操作
4.1 DOM查询优化
①没缓存DOM查询的结果,频繁进行DOM查询,耗费性能
for(let i = 0 ; i<document.getElementsByTagName('p').length; i++){
// 导致一个问题就是每次循环都会计算(length),频繁进行DOM查询
}
②缓存DOM查询结果,只需查询一次
const plist = document.getElementsByTagName('p')
const length = plist.length
for(let i = 0 ; i<length ; i++) {
// 缓存了length,只进行一次DOM查询,节省性能
}
4.2 DOM插入优化
①创建10个列表,每次执行完即进行DOM插入,耗费性能
const list = document.getElementById('list')
for(let i = 0 ; i<10 ; i++){
const li = document.createElement('li')
li.innerHTML = `List item ${i}`
list.appendChild(li)
}
// 每执行一次,即插入一次,总共进行了10次DOM插入操作
②将频繁操作改为一次性操作
const listName = document.getElementById('list')
// 创建一个文档片段,此时还没有插入到DOM树中
const frag = document.createDocumentFragment()
for(let j = 0 ; j<10 ; j++){
const li = document.createElement('li')
li.innerHTML = "list item" + j
frag.appendChild(li)
}
// 将添加的10个列表都创建完成后,再一起插入到DOM树中
5.如何识别浏览器的类型
navigator.userAgent 浏览器的user-agent信息,其中userAgent 属性是一个只读的字符串,声明了浏览器用于 HTTP 请求的用户代理头的值
const ua = navigator.userAgent
const isChrome = ua.indexOf('Chrome')
console.log(isChrome)
这样的判断是远远不够的,这只是一种简易判断,具体判断要根据不同浏览器做不同的识别判断
6.分析拆解url各个部分
Location 对象包含有关当前 URL 的信息
- location.hash 设置或返回从井号 (#) 开始的 URL(锚)
- location.host 设置或返回主机名和当前 URL 的端口号
- location.hostname 设置或返回当前 URL 的主机名
- location.href 设置或返回完整的 URL
- location.pathname 设置或返回当前 URL 的路径部分
- location.port 设置或返回当前 URL 的端口号
- location.protocol 设置或返回当前 URL 的协议
- location.search 设置或返回从问号 (?) 开始的 URL(查询部分)
7.编写一个通用的事件绑定(监听)函数
7.1 青春版及用法
// <div>
// <button id="btn1">一个按钮</button>
// </div>
function bindEvent( elem , type , fn ){
elem.addEventListener( type , fn )
}
const btn1 = document.getElementById('btn1')
bindEvent( btn1 , 'click' , e => {
alert('clicked')
} )
7.2 完整版通用事件绑定函数(考虑代理问题)
function bindEvent( elem , type , selector , fn ){
if( fn == null ){
fn = selector
selector = null
}
elem.addEventListenrt( type , e => {
let target = e.target
if( selector ){ // 需要代理
if( target.matches(selector) ){
fn.call( target , e )
}
} else {
fn(e) // 不需要代理
}
} )
}
8.描述事件冒泡的流程
- 微软公司的IE提出了事件冒泡的事件流。事件冒泡是什么意思呢?我们可以将其比喻为一个在水底的气泡,这个气泡在水里会不断往上升,直到浮出水面。事件冒泡就是类似这样一个从底往上的过程,事件会从最内层的元素开始发生,发生顺序一直向上,直到document
以一个例子说明,事件发生的顺序为:p -> div -> body -> html -> document
<div id="a1">
<p id="a2"></p>
</div>
事件冒泡基于DOM树形结构,事件会顺着触发元素往上冒泡,应用场景是事件代理
9.普通绑定与事件代理绑定
HTML结构
<body>
<div id="div1">
<p id="p1">激活</p>
<p id="p2">取消</p>
<p id="p3">取消</p>
<p id="p4">取消</p>
</div>
<div id="div2">
<p id="p5">取消</p>
<p id="p6">取消</p>
</div>
</body>
简单事件绑定
function bindEvent( elem , type , fn ){
elem.addEventListener( type , fn )
}
9.1 普通绑定
此时如下对p1进行绑定,点击p1即触发绑定的方法(弹出p1激活),那如果我要p2、p3、p4…都绑定该方法,那我岂不是要一个个进行绑定?此时我们就应考虑到可以利用事件冒泡进行事件代理,请往下看
const p1 = document.getElementById('p1')
bindEvent( p1 , 'click' , e => {
// e.stopPropagation()
// 注释该行,体会事件冒泡,阻止冒泡
alert('p1激活')
} )
9.2 事件代理绑定
因为你点击p1、p2、p3、p4、p5、p6,其实是都会冒泡到body,意思也就是你点击p1、p2、p3、p4、p5、p6,也就是点击了body下的元素,所以我们就可以这样进行代理,只需要将该方法绑定到body就行
const body = document.body
bindEvent( body , 'click' , e => {
alert('body激活')
} )
如果在一整个例子中,你p1也绑定了9.1该方法,body也绑定了9.2该方法,那么当你点击p1的时候,会先弹出①p1激活,再弹出②body激活,这样你就能直观得感受到事件冒泡,如果你将e.stopPropagation()取消注释,你再点击p1,你会发现此时只弹出(p1激活),不会弹出body激活,因为其会阻止冒泡
写在文末
如果你觉得我写得还不错的话,可以给我点个赞哦^^,如果哪里写错了、写得不好的地方,也请大家评论指出,以供我纠正。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









