







 快速排序是一种采用分治策略的排序算法,通过选择基准数将数组分为两部分,确保基准左边的元素小于右边的。在最坏情况下,时间复杂度为O(n^2),但平均时间复杂度是O(nlogn)。针对有序或重复数组的效率降低问题,可以通过随机选择基准数来优化,减少最坏情况出现的概率。
快速排序是一种采用分治策略的排序算法,通过选择基准数将数组分为两部分,确保基准左边的元素小于右边的。在最坏情况下,时间复杂度为O(n^2),但平均时间复杂度是O(nlogn)。针对有序或重复数组的效率降低问题,可以通过随机选择基准数来优化,减少最坏情况出现的概率。
快速排序
ref:
http://data.biancheng.net/view/71.html
https://www.geeksforgeeks.org/quick-sort/
面试官,不要再问我快速排序了! - LuronTalking的文章 - 知乎 https://zhuanlan.zhihu.com/p/91935950
https://blog.youkuaiyun.com/vict_wang/article/details/83118746#:~:text=%E5%BF%AB%E9%80%9F%E6%8E%92%E5%BA%8F%E7%89%B9%E7%82%B9,%E5%8F%98%E6%88%90%E6%9C%89%E5%BA%8F%E5%BA%8F%E5%88%97%E3%80%82&text=%E7%BC%BA%E7%82%B9%EF%BC%9A%E4%B8%8D%E7%A8%B3%E5%AE%9A%EF%BC%8C%E5%88%9D%E5%A7%8B%E5%BA%8F%E5%88%97,O(n%5E2)%E3%80%82
思想:
使用分治的思想,选择一个基准数,将比基准数小的放在基准数的左边,比基准大的放在基准数的右边,这样就将数组分成了两份,右边的一定比左边的大,然后再用同样的方法去递归的选择两边的子数组。
怎么实现:
- 怎么选择基准?
- 怎么选择判断排序是否成功?即结束的条件是什么?
- 怎么把数据放到基准的左边或者右边?
- 与基准相等的数据放在哪边?
带着问题,先来看图:
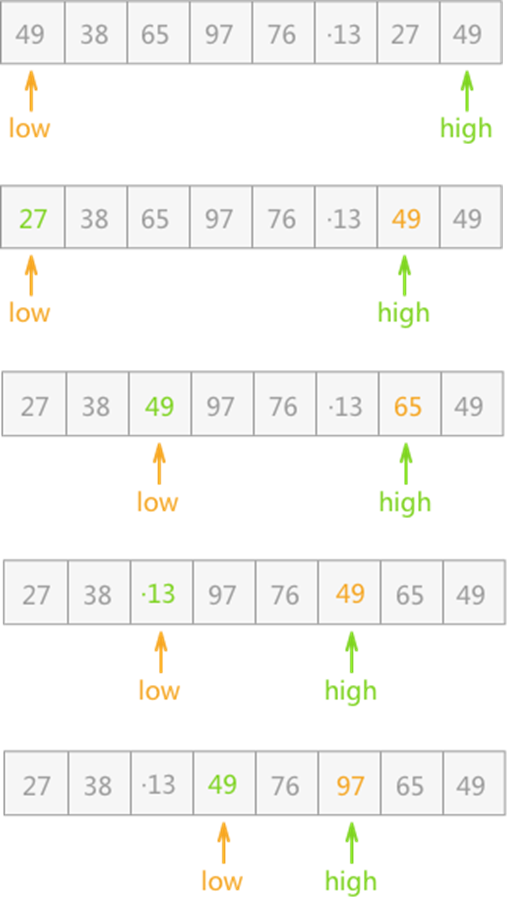
步骤:
-
设置两个指针 low 和 high,分别指向无序表的表头和表尾,如下图所示:
-
先由 high 指针从右往左依次遍历,直到找到一个比 49 小的关键字,所以 high 指针走到 27 的地方停止。找到之后将该关键字同 low 指向的关键字进行互换:
-
然后指针 low 从左往右依次遍历,直到找到一个比 49 大的关键字为止,所以 low 指针走到 65 的地方停止。同样找到后同 high 指向的关键字进行互换:
-
指针 high 继续左移,到 13 所在的位置停止(13<49),然后同 low 指向的关键字进行互换:
-
指针 low 继续右移,到 97 所在的位置停止(97>49),然后同 high 指向的关键字互换位置:
-
指针 high 继续左移,此时两指针相遇,整个过程结束;
所以算法可以总结成:
需要满足的条件:返回基准的位置,且基准左边都是比基准小的数,右边都是比基准大的数
条件是low = =high的时候返回,所以:
- 确定两个指针,初始在表头和表尾,一个low,一个high,
- low和high在移动的过程中必须有一个要指向基准;
- 设置两个指针,low指针以前的代表已经排序好的,比基准小的值,high指针以后的值同样代表排序好的,比基准大的值;
当low指向基准指针的时候,high指针从右往左移动,见到比基准小的数就将low和high两个指针指向的值进行交换(本质就是通过交换,把一个比基准小的数放到了数组的最小端)
此时基准值被放在了high指针的方向,为了不丢失基准位置,不动high指针,从low指针开始从左往右移动,进行比较和交换)
指向基准的指针不动,另一个指针去移动,比较,如果发现不符合排序规则就与基准指针交换
整个过程中最重要的是实现第 2 步的分割操作,具体实现过程为:
代码:
int paritition(vector<int>& nums, int low, int high)
{
int pivot = nums[low];
while(low < high){
// 从左往右比较
while((nums[high] >= pivot) && (low < high)) {
high--;
}
swap(nums[low], nums[high]);
while((nums[low] < pivot) && (low < high)) {
low++;
}
swap(nums[low], nums[high]);
}
return low;
}
完整代码
class Solution {
int paritition(vector<int>& nums, int low, int high)
{
int pivot = nums[low];
while(low < high){
// 从左往右比较
while((nums[high] >= pivot) && (low < high)) {
high--;
}
// 这里可以直接swap,也可以直接赋值,因为基准数已经保存下来了,增加速度
//swap(nums[low], nums[high]);
nums[low] = nums[high];
while((nums[low] < pivot) && (low < high)) {
low++;
}
//swap(nums[low], nums[high]);
nums[high] = nums[low];
}
nums[low] = pivot;
return low;
}
void quicksort(vector<int>& nums, int low, int high)
{
if (low < high) { // 传进来的Low和high相等了说明排序完成
int pivot = paritition(nums, low, high); // 排序
quicksort(nums, low, pivot - 1); // 左区间排序
quicksort(nums, pivot + 1, high); // 右区间排序
}
}
public:
vector<int> sortArray(vector<int>& nums) {
quicksort(nums, 0, nums.size() - 1);
return nums;
}
};
快排的时间复杂度
平均时间复杂度是O(nlogn) 对数的底是2
缺点
快排对于有序数组和重复数组的时间复杂度会变得很高,时间复杂度会降至最坏的情况O(N*N)
对快排来说,排序最快的情况是每次基准数都选择为数组的中间数,排列后在数组的中间,这样分成的两个子区间为原数组的一半,可以减小排序的次数
如果数列本身有序或者重复,选择第一个数为基准数,那么算法从尾部查找到头部会发现没有需要交换的数据,基准仍然在数组第一个,分出来的右区间只比原来的数组长度小1,每次查完两个数组,基准只移动一位,就需要查找N次才能退出递归。
优化方法:面对有序数组,随机选取Pivot是个有效的优化方法,每次只有1/N的概率会选择到第一个数为基准数,也就是1/N的概率为最差的情况
面对数组中的值全为一样的,不管怎么选基准数,选出来都是一样的值,都会成为最差的情况,这时得用多路快排或者堆排
随机选取pivot的实现方法
很简单,生成一个随机数,在开始分区之前将随机数所指向的数组元素与low指针指向的元素互换即可,完整代码如下:
class Solution {
int paritition(vector<int>& nums, int low, int high)
{
int pivot = nums[low];
while(low < high){
// 从左往右比较
while((nums[high] >= pivot) && (low < high)) {
high--;
}
// 这里可以直接swap,也可以直接赋值,因为基准数已经保存下来了,增加速度
//swap(nums[low], nums[high]);
nums[low] = nums[high];
while((nums[low] < pivot) && (low < high)) {
low++;
}
//swap(nums[low], nums[high]);
nums[high] = nums[low];
}
nums[low] = pivot;
return low;
}
int random_qsort(vector<int>& nums, int low, int high)
{
int i = rand() % (high - low + 1) + low;
swap(nums[i], nums[low]);
return paritition(nums, low, high);
}
void quicksort(vector<int>& nums, int low, int high)
{
if (low < high) { // 传进来的Low和high相等了说明排序完成
int pivot = random_qsort(nums, low, high); // 排序
quicksort(nums, low, pivot - 1); // 左区间排序
quicksort(nums, pivot + 1, high); // 右区间排序
}
}
public:
vector<int> sortArray(vector<int>& nums) {
quicksort(nums, 0, nums.size() - 1);
return nums;
}
};
最后再来回答下问题的答案
问题的答案:
- 随机选取基准以规避快排有序数列的局限性
- 当low和high指针相等时结束排序
- 使用与Low或者high指针交换的方法
- 随意放在左边或者右边


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









