







 本文介绍了MongoDB的基本概念,包括数据库、集合和文档,并通过Navicat可视化工具展示了如何操作MongoDB。接着,详细阐述了如何使用NodeJS和Mongoose框架进行数据库的连接、增删查改操作。此外,文章还提到了MVC编程思想在项目组织中的应用,以及MongoDB的分页查询和多集合关联查询的方法。最后,讨论了数组操作,如添加、删除数组元素。
本文介绍了MongoDB的基本概念,包括数据库、集合和文档,并通过Navicat可视化工具展示了如何操作MongoDB。接着,详细阐述了如何使用NodeJS和Mongoose框架进行数据库的连接、增删查改操作。此外,文章还提到了MVC编程思想在项目组织中的应用,以及MongoDB的分页查询和多集合关联查询的方法。最后,讨论了数组操作,如添加、删除数组元素。
MongoDB开发
第一节、数据库相关概念
什么是数据库(Data Base–DB):
存储数据的仓库,并且对数据提供统一的管理
为什么需要数据库:
- 如果没有数据库,将数据存储在内存中,则会断电即消失
- 如果存储在本地存储,数据必须是字符串,而且对数据量的大小也是有规定
- 以上方式数据没有进行统一的管理,对于用户来说数据的操作很麻烦
常见的数据库分类:
关系型数据库:MySQL oracle sqlServer…
适用于:中大型的系统
非关系型数据库:mongoDB,Redis
适用于:小型系统或者作为缓存系统
第二节、MongoDB的一些概念
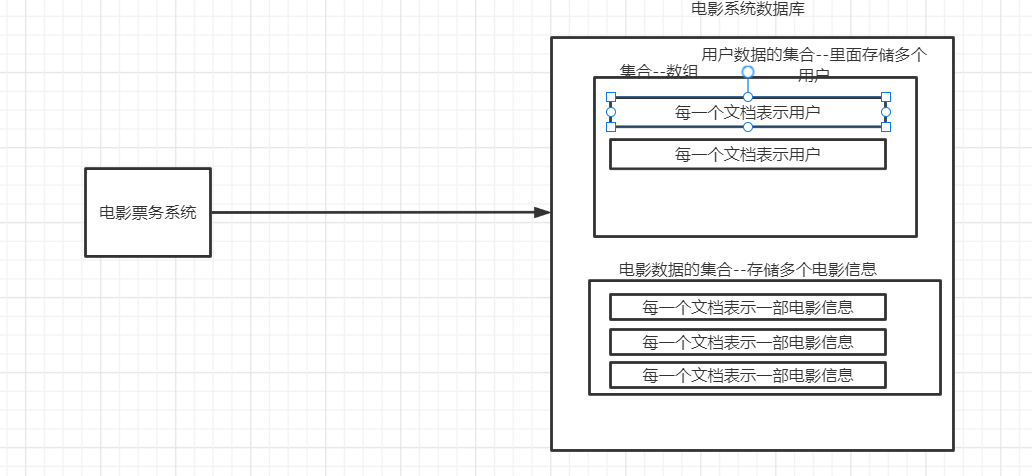
数据库:一个系统往往对应一个数据库。【安装mongo 通过mongo可以创建多个数据库】
集合:一个数据库中往往有多个集合,每一个集合类似于数组。用于保存多个数据。【一般是某一类数据对应一个集合】
文档:一个集合中可以有多个文档,每一个文档类似于数组中的一个元素。表示特定一个数据。
ObjectId:每一个文档mongoDB会自动的生成一个唯一的不重复的ID值,这个ID称为ObjectId。
Nvicate
- 是一个可视化的数据库操作工具
第三节、通过node JS操作mongDB
1、创建一个基础的项目
2、通过navicat创建一个数据库与项目对应
3、创建1个集合并存储数据
-
单击创建的数据库
-
右键集合–新建集合–ctrl+s保存–对集合起名
-
双击打开集合,在右侧空白右键选择添加文档
-
{ username:"tom", userpass:"123456" //JS对象语法 } -
选中某一个文档中某个数据 按向下键 输入新的文档内容【ID不要手动输入】
-
4、在项目中安装mongoose[在项目上打开终端]
npm i mongoose
5、编写代码将程序与mongoDB连接【app.js】
//编写数据库连接代码
//1.引入mongoose的模块
var mongoose = require("mongoose");
//2.配置连接
const DB_URL = "mongodb://127.0.0.1:27017/movsys89";//连接地址 mongodb://IP地址:27107/数据库名
//3.连接数据库
mongoose.connect(DB_URL,{useUnifiedTopology: true, useNewUrlParser: true });
//4.设置一个连接成功的回调,用于提示连接
mongoose.connection.on("connected",function(){
console.log("已经成功连接mongodb"+DB_URL);
});
6、编写代码操作mongodb【router文件夹中】
-
编写一个schema对象与mongodb中集合相对应
//1.引入mongoose var mongoose = require("mongoose"); //2.编写1个集合对应的Schema对象 var userSchema = new mongoose.Schema({ username:String, usrpass:String });将schema对象与集合绑定
//3.将schema与集合关联起来 mongoose.model("userModel",userSchema,"user"); // 在系统中存储了userModel对象 这个对象其实 user集合与userSchema绑定一个对象操作集合【操作userModel】
//4、编写代码操作userModel async function getAllUser(){ let data = await mongoose.model("userModel").find({});//model方法其实是一个promise对象 其中可以完成对象集合的操作 console.log(data); } getAllUser();在app.js中引入编写文件[引入的位置一定是在连接的后面]
var usersRouter = require('./routes/users');练习:创建一个user集合并存储数据,在代码中查询所有并打印
第四节、通过mongoose框架操作mongodb
find()
作用:数据的查询
语法 : mongoose.model(“模型名称”).方法名
//1.查询所有的电影
// let data = await mongoose.model("moviesModel").find({}); //如果是一个空对象 则表示查询所有的电影
//2.根据ID查询指定的电影(在所有的文档中去比对给定的条件 严格比对)
//let data = await mongoose.model("moviesModel").find({_id:"63805df7e15d0000fd006542"});
//查询电影名为飞驰人生的电影
//let data = await mongoose.model("moviesModel").find({title:"飞驰人生"});
//3.查询电影名称包含 飞驰的电影【模糊查询】
//let data = await mongoose.model("moviesModel").find({title:{$regex:"飞驰"},options:"$i"});
//4、查询沈腾出演的电影
// let data = await mongoose.model("moviesModel").find({actor:"刘德华"});
//5.查询定影名为飞驰人生 演员名为沈腾的电影
//let data = await mongoose.model("moviesModel").find({title:"飞驰人生",actor:"沈腾"}); //并且
//6.查询沈腾或者刘德华出演的电影
let data = await mongoose.model("moviesModel").find({$or:[{actor:"刘德华"},{actor:"沈腾"}]});//或者
console.log(data);
create()
作用:添加文档
语法:
let data = awite mongoose.model(“模型名称”).create(对象或者对象数组);
//向数据库中添加 一部电影 名字叫 战狼2 演员 吴京 描述 打打杀杀 type 动作
let data = await mongoose.model("moviesModel").create(
[
{
title:"喜羊羊与灰太狼",
actor:"喜洋洋",
desc:"非常有意思",
type:"爱情"
},
{
title:"喜羊羊与灰太狼22",
actor:"灰太狼",
desc:"有意思",
type:"动作"
}
]
);
console.log(data);
//create 返回结果为当前添加的对象
deleteMany
作用:删除文档
语法:let data = awite mongoose.model(模型名称).deleteMany({条件})
注意:往往是根据指定的条件进行删除,此处的条件写法跟查询的写法一致
//数据的删除
async function moviesDeleteFunction(){
//根据指定ID删除电影
//let data = await mongoose.model("moviesModel").deleteMany({_id:"63805df7e15d0000fd006542"});
//删除名字带有飞驰的电影
let data = await mongoose.model("moviesModel").deleteMany(
{
title:{$regex:"飞驰"},
options:"$i"
}
);
//通过data 来判断是否已经删除掉
console.log(data);
}
注意:deleteMany有1个返回对象,对象中有1个属性:deletedCount 表示删除的文档个数。【我们可以通过它来判定是否删除成功】
updateMany()
作用:用于修改文档
语法:let data = awite mongoose.model(模型名称).updateMany({条件},{新的数据})
async function moviesUpdateFunction(){
let data = await mongoose.model("moviesModel").updateMany(
{
_id:"638070668293bc8770c27a5c",
},
{
desc:"这不仅仅是打打杀"
}
);
console.log(data);
}
updateMany返回结果中有2个属性:
modifiedCount 修改的总数
matchedCount 条件匹配的条数
第五节、MVC的编程思想
简介:
在编写项目的过程中,很多的代码都是放在一起的。导致整个项目不变于维护和排错。
使用MVC实现对象项目中不同功能的代码进行归类,不同 功能的代码放在不同的文件夹中。
实现步骤:
- M(Model–数据模型):指的是数据定义相关的代码,如:express项目中指集合对应Schema模型
- 在项目中创建一个文件夹(model)其中就分放置整个项目的模型相关的代码【每一个文件就对应一个Schema模型 – 取名 XXXShecma】
- V(View-视图层):前端部分,数据的展示
- 复用以前的router文件夹(每一个文件对应一类型的操作,取名一般取为XXXRouters)
- C(Controller-控制器层):指整个项目的业务逻辑
- 在项目中新增一个文件夹controllers(针对不同类型的业务创建不同的JS文件,一般取名xxxController)
- utils:放置一些公共的代码或者与业务逻辑无关的代码。
- 在项目中新增一个文件夹utils
实现细节
编写公共代码
1、创建utils的文件夹
- 创建appConfig.js 编写整个项目配置相关的代码
//整个项目相关的一些配置
const DB_URL = "mongodb://127.0.0.1:27017/movsys89"; //数据库连接地址
const PORT = 8080; //项目端口号
//暴露配置信息
module.exports = {
DB_URL,
PORT
}
- 创建dbUtils.js 放置跟数据库操作相关的个公共代码【数据库连接】
const {DB_URL} = require("./appConfig"); //数据库连接地址
const mongoose = require("mongoose");//mongoose框架
//数据连接的获取方法
module.exports.getConnection = function(){
mongoose.connect(DB_URL,{useUnifiedTopology: true, useNewUrlParser: true });
mongoose.connection.on("connected",function(){
console.log("已经成功连接mongodb"+DB_URL);
});
}
2、创建model文件夹
每一个集合对应一个model文件。
userModel.js
----
const mongoose = require("mongoose");
var userSchema = new mongoose.Schema({
username:String,
userpass:String
},{
versionKey:false
});
let model = mongoose.model("userModel",userSchema,"user"); //向项目中注册名为userModel的对象 整个对象就是shecma模型 与数据库集合绑定的model 同时有一个返回值,返回值也是该model
module.exports = model;
3、创建controller文件夹用于放置核心业务代码
针对不同类型的业务,创建不同的文件
---userController.js
//编写方法实现业务的操作 数据库操作
const userModel = require("../model/userModel"); //直接引入userModel对象
module.exports.userReg = async function(req,resp){
console.log(req.body);
let {username,userpass} = req.body;
//数据操作的代码
//将用户名和密码添加至数据库中
//1.判断用户是否存在
//根据用户名查询 如果查询出来的数组长度不为0 则说明重复
let data = await userModel.find({username}); //通过userModel调用方法 -- 以前mongoose.model("模型名称") 去系统找名为userModel的对象
if(data.length!=0){
resp.send({code:500,msg:"注册失败,用户名被占用"})
}else{
//做注册操作【用户名和密码存储数据库】
let data = await userModel.create({username,userpass});
if(data!=null){
resp.send({code:200,msg:'注册成功',datas:data})
}else{
resp.send({code:500,msg:"注册失败"});
}
}
}
4、在routers中配置二级路径
var express = require('express');
var router = express.Router();
const userController = require("../controller/userController");
router.post("/userReg",userController.userReg);
module.exports = router;
5、在app.js中配置一级路径
第六节、分页展示数据
什么叫做分页:如果数据量很大情况下,如果采用一页显示这样用户体验和不好,所以需要对数据进行分页展示。
怎么实现分页:
1、前端知道的数据有哪些:每页的条数(pageSize) 需要查询的页数(pageNum)
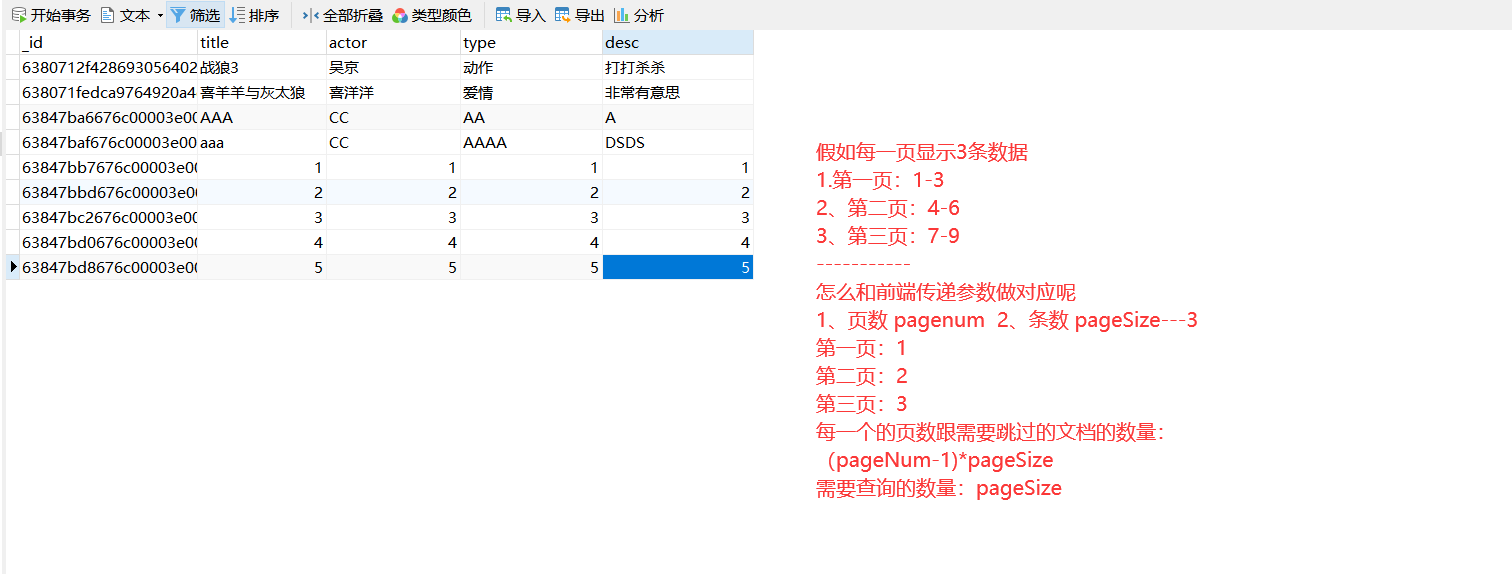
countDocuments() :获取集合中文档的总数—计算总页数的(countDocuments/pageSize)向上取整 5/3 ---- >1.1
skip() :跳过指定的条数—skip((pagenum-1)*pageSize)
limit():查询指定的条数-- limit(pageSize)
let {pageSize,pageNum} = req.query;
//查询指定页数的数
let data = await moviesModel.find({}).skip((pageNum-1)*pageSize).limit(pageSize); //每一个的数据
let count = await moviesModel.countDocuments();//总条数
let allpages = Math.ceil(data2.length/pageSize);//计算总页数
如果是带条件的查询,计算总页数的时候
let data2 = await moviesModel.find({title:"AAA"});
console.log(data2.length);
let allpages = Math.ceil(data2.length/pageSize);//计算总页数
第七节、多集合关联查询
为什么会需要多集合
往往一个A集合中记录的某一类的数据,如果有其他附属的关联的信息【属于另一类信息B】,需要对该关联信息重新建立一个集合B。在A集合中创建一列数据专门用于记录(B)关联数据的ID.
比如:每一部电影有自己的信息【名称,票价,评分,描述,地址】,然后每一部电影还有演员的信息【另一类信息】【演员名字,片酬,描述,性别…】。如果直接记录在一个集中
战狼 20 8.0 好看 吴京 100W 硬汉 男
战狼2 30 9.0 一般 吴京 100W 硬汉 男
问题:造成数据的冗余【每一部电影都会记录一个演员信息,如果演员重复了则数据冗余了】
解决:将不同类型的数据抽取到不同的集合中
电影集合:记录电影相关的数据【主体是电影本身】
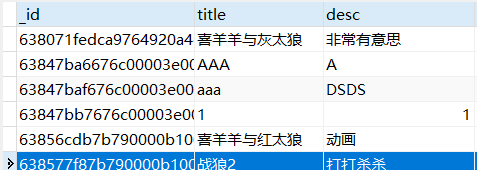
演员的集合:记录演员相关的信息【主体是演员本身】
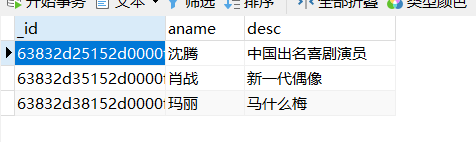
以上集合新的问题:
电影集合跟演员集合完全没有关联,根本不知道某一部电影是由谁出演的。
解决:在电影的集合中创建1列用于记录关联的演员的信息,一般记录某个演员的_id【这一列称为外键】

实现关联查询
1、分别对每一个集合创建对应Schema模型
const mongoose = require("mongoose");
const actorShcema = new mongoose.Schema({
aname:String,
agender:String,
decs:String
});
let model = mongoose.model("actorModel",actorShcema,"actor");//在内存中注册模型 名为actorModel
module.exports = model;
const mongoose = require("mongoose");
let actorModel = require("./actorModel");//引入actorModel的JS文件
const moviesSchema = new mongoose.Schema({
title:String,
actorId:{
type:mongoose.SchemaTypes.ObjectId, //actorId本质类型---objecId
ref:"actorModel" //关联的集合
},
type:String,
desc:String
},{
versionKey:false
})
//注册model
let model = mongoose.model("movieModel",moviesSchema,"movies");
module.exports = model; //暴露model对象
2、在关联的集合Shcema模型中,将关联Id属性写成
actorId:{
type:mongoose.SchemaTypes.ObjectId, //actorId本质类型---objecId
ref:"actorModel" //关联的集合---前提是关联的集合一定是先注册了 mongoose.model("actorModel",actorShcema,"actor");
},
3、查询的时候将actorId通过populate方法去将actorId最终翻译对应的关联的对象
let data = await moviesModel.find({}).populate("actorId");
注意:关联查询并不影响条件查询和分页
let data = await moviesModel.find({}).populate("actorId").skip(1).limit(2);
练习:将电影信息与演员信息拆分,做关联查询
关联查询中特殊操作
1、存在多个关联集合
场景:电影集合中既关联了演员的集合,又关联了类型的集合
处理方式:跟关联一个集合处理方式一致。
const moviesSchema = new mongoose.Schema({
title:String,
actorId:{
type:mongoose.SchemaTypes.ObjectId, //actorId本质类型---objecId
ref:"actorModel" //关联的集合
},
type:{
type:mongoose.SchemaTypes.ObjectId,
ref:"typeModel"
},
desc:String
},{
versionKey:false
})
let data = await moviesModel.find({}).populate("actorId").populate("type");
2、一对多的关联查询
场景:一部电影对应多个演员
数据库层面怎么体现一对多:
在电影集合中通过数据来记录一部电影对应多个演员
代码层面:
在关联Schema模型中通过[]表示数组
actorId:[{
type:mongoose.SchemaTypes.ObjectId, //actorId本质类型---objecId
ref:"actorModel" //关联的集合
}],
let data = await moviesModel.find({}).populate("actorId").populate("type");
3、多层嵌套查询
场景:一部电影有多个评论,但是一条评论又对应一个用户
数据库层面:


代码层面:
1、模型对应

commentsId:[{
type:mongoose.SchemaTypes.ObjectId,
ref:"commentsModel"
}],
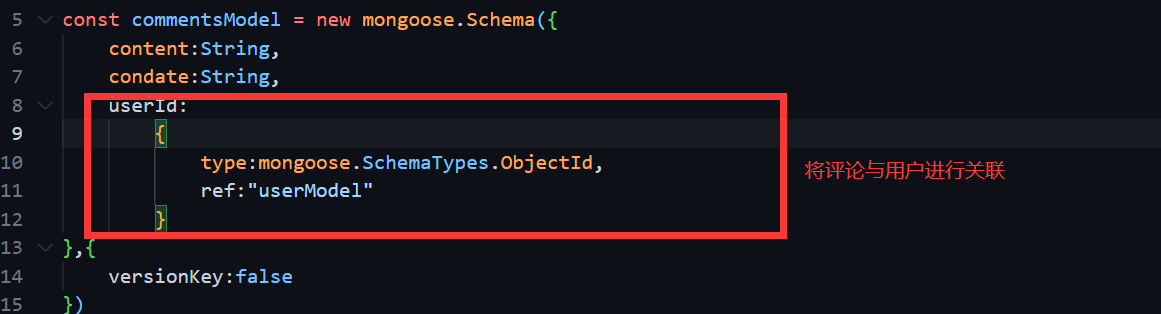
const commentsModel = new mongoose.Schema({
content:String,
condate:String,
userId:
{
type:mongoose.SchemaTypes.ObjectId,
ref:"userModel"
}
},{
versionKey:false
})
在获取数据的时候:
let data = await moviesModel.find({}).populate("actorId").populate("type").
populate("commentsId").populate({path:"commentsId",populate:{path:"userId"}});
总结:查询处理方式
- 查询所有 find({})
- 条件查询 find({条件})-- 可以多条件,但是条件的属性名与值是严格匹配
- 模糊查询 fin({字段名:{$regex:“模糊值”}})
- 关联
- 一对一
- 一对多
- 嵌套
练习:查询某部电影所有评论信息–谁评论的
第八节、数组的操作
记录普通的数据
场景:每一部电影有多个描述
在数据库层面:数组中放String
在代码层面—数据模型:
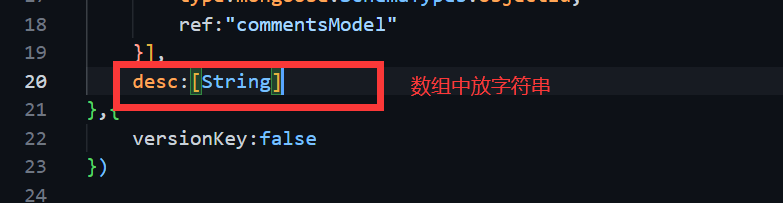
查询的时候跟之前一直。
数组的操作【不管记录是关联ID还是普通的数据】
1、创建
直接添加数据,数据类型与模型中的类型一致即可【模型中的数据类型跟集合对应】

async function testArrayCreate(){
//添加元素--其中有数组
//案例:添加一部电影---有演员列表 描述 评论[]
let data = await moviesModel.create({
title:"我是添加的电影",
actorId:["638577c37b790000b1002015","6385a94ed91b0000a4000204"],
type:"638582607b790000b1002017",
commentsId:[],
desc:["我是添加的1","我是添加B"]
});
}
2、对数组元素添加 push
//向指定ID的电影commontsID数组中添加 一个评论的ID
let data2 = await moviesModel.updateMany({
_id:"638071fedca9764920a4ce34"
},{
$push:{
commentsId:[data._id] //向commentsId数组中添加1个元素
}
});
3、删除元素 【pull】
场景:删除评论
//删除数组中的元素
//案例:删评论
//思路:页面查询电影评论的时候是可以查询到每条评论的ID
//删除:先在评论表中删除指定ID的评论信息 同时在电影commentdId数组中删除对应ID
async function testArrayPull(){
let comid = "6385cb04cf0b8fa0dfd5c45b";
let movid = "6385c6a8711042e0d271b865";
let data = await commentsModel.deleteMany({
_id:comid
});
console.log(data);
let data02 = {};
if(data.deletedCount>0){
data02 = await moviesModel.updateMany({
_id:movid
},{
$pull:{
commentsId:comid
}
});
}
if(data02.modifiedCount>0){
//删除评论成功
}else{
//删除评论失败
}
// if(data02)
console.log(data02);
}

















 253
253

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









