







一.Hystrix介绍
Hystrix是Netlifx开源的一款容错框架,防雪崩利器,具备服务降级,服务熔断,依赖隔离,监控(Hystrix Dashboard)等功能。
【Hystrix:】
Hystrix 是一个用于处理分布式系统 延迟 和 容错的 开源库,
目的是 隔离远程系统、服务和第三方库的访问点,停止级联故障,并在不可避免发生故障的复杂分布式系统中实现恢复能力。
注:
分布式系统难免出现 阻塞、超时、异常 等问题,Hystrix 可以保证在一个服务出问题时,不影响整个系统使用(避免服务雪崩),提高系统的可用性。
【常用特性:】
服务降级
服务熔断
服务监控
【相关地址:】
https://github.com/Netflix/Hystrix
【问题:】
对于一个复杂的分布式系统来说,可能存在数十个模块,且模块之间可能会相互调用(嵌套),
这就带来了一个问题:
如果某个核心模块突然宕机(或者不能提供服务了),那么所有调用该 核心模块服务 的模块 将会出现问题,
类似于 病毒感染,一个模块出现问题,将逐步感染其他模块出现问题,最终导致系统崩溃(也即服务雪崩)。
【服务雪崩:】
服务雪崩 指的是 服务提供者 不可用(不能提供服务) 而导致 服务消费者不可用,并逐级放大的过程。
比如:
多个微服务之间形成链式调用,A、B 调用 C,C 调用 D,D 调用其他服务等。。。
如果 D 因某种原因(宕机、网络延迟等) 不能对外提供服务了,将导致 C 访问出现问题,而 C 出现问题,将可能导致 A、B 出现问题,也即 问题逐级放大(最终可能引起系统崩溃)。
【解决:】
服务降级、服务熔断 是解决 服务雪崩的 常用手段。
相关技术:
Hystrix(维护状态,不推荐使用)
Sentienl(推荐使用)
尽管说Hystrix官方已不再维护,且有Alibaba Sentinel等新框架选择,但从组件成熟度和应用案例等方面看,其实还是有很多项目在继续使用Hystrix中,本人所参与的项目就是其一。故结合个人的Hystrix实战经验与大家分享交流。
二.Hystrix 实现服务降级
1.降级定义
【服务降级:】
服务降级 指的是 当服务器压力 剧增 时,根据当前 业务、流量 情况 对一些服务(一般为非核心业务)进行有策略的降级,确保核心业务正常执行。
即 释放非核心服务 占用的服务器资源 确保 核心任务正常执行。
注:
可以理解为 损失一部分业务能力,保证系统整体正常运行,从而防止 服务雪崩。
资源是有限的,请求并发高时,若不对服务进行降级处理,系统可能花费大量资源进行非核心业务处理,导致 核心业务 效率降低,进而影响整体服务性能。
此处的降级可以理解为 不提供服务 或者 延时提供服务(服务执行暂时不正常,给一个默认的返回结果,等一段时间后,正常提供服务)。
【服务降级分类:】
手动降级:
可以通过修改配置中心配置,并根据事先定义好的逻辑,执行降级逻辑。
自动降级:
超时降级:设置超时时间、超时重试次数,请求超时则服务降级,并使用异步机制检测 进行 服务恢复。
失败次数降级:当请求失败达到一定次数则服务降级,同样使用异步机制检测 进行服务恢复。
故障降级:服务宕机了则服务降级。
限流降级:请求访问量过大则服务降级。
2.服务降级使用场景
服务器资源耗尽,请求响应慢,导致请求超时。
服务器宕机 或者 程序执行出错,导致请求出错。
即:
服务提供者 响应请求超时了,服务消费者 不能一直等待,需要 服务提供者进行 服务降级,保证 请求在一定的时间内被处理。
服务提供者 宕机了,服务消费者 不能一直等待,需要 服务消费者进行 服务降级,保证 请求在一定的时间内被处理。
服务提供者正常,但 服务消费者 出现问题了,需要服务消费者 自行 服务降级。
注:
服务降级一般在 服务消费者 中处理,服务提供者 也可以 进行处理。
3.代码实现
Step1:
引入 hystrix 依赖。
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-hystrix</artifactId>
</dependency>Step2:
通过 @HystrixCommand 注解 编写 服务降级策略。
【简单说明:】
@HystrixCommand 表示指定 服务降级 或者 服务熔断的策略。
fallbackMethod 表示服务调用失败(请求超时 或者 程序执行异常)后执行的方法(方法参数要与 原方法一致)。
commandProperties 表示配置参数。
@HystrixProperty 设置具体参数。
注:
详细参数情况可以参考 HystrixCommandProperties 类。
com.netflix.hystrix.HystrixCommandProperties
【定义服务降级策略:】
public Result testTimeoutReserveCase() {
return Result.ok().message("当前服务器繁忙,请稍后再试!!!");
}// 定义服务降级策略
@HystrixCommand(
// 当请求超时 或者 接口异常时,会调用 fallbackMethod 声明的方法(方法参数要一致)
fallbackMethod = "testTimeoutReserveCase",
commandProperties = {
@HystrixProperty(name="execution.isolation.thread.timeoutInMilliseconds", value="1500")//超时时间为1.5秒
}
)
@GetMapping("/testTimeout")
public Result testTimeout() {
try {//暂停0.5秒
Thread.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
return Result.ok();
}
Step3:
在启动类上添加 @EnableCircuitBreaker 注解,开启服务降级、熔断。
4.配置默认服务降级方法
通过上面简单演示可以完成 服务降级,但是存在一个问题,如果为每一个接口都绑定一个 fallbackMethod,那么代码将非常冗余。
通过 @DefaultProperties 注解 定义一个默认的 defaultFallback 方法,接口异常时调用默认的方法,并仅对特殊的接口进行单独处理,从而减少代码冗余。
如下,新增一个 运行时异常,访问接口时,将会调用 globalFallBackMethod() 方法。
而前面特殊定义的 testTimeout 超时后,仍调用 testTimeoutReserveCase方法。
@DefaultProperties(defaultFallback = "globalFallBackMethod")
public class UserController {
public Result globalFallBackMethod() {
return Result.ok().message("系统异常,请稍后再试!!!");
}
@GetMapping("/testRuntimeError")
@HystrixCommand
public Result testRuntimeError() {
int temp = 10 / 0;
return Result.ok();
}
}三.Hystrix 实现服务熔断
1.服务熔断定义
服务熔断 指的是 目标服务不可用 或者 请求响应超时时,为了保证整体服务可用,
不再调用目标服务,而是直接返回默认处理(释放系统资源),通过某种算法检测到目标服务可用后,则恢复其调用。
注:
在一定时间内,服务调用失败次数达到一定比例,则认为 当前服务不可用。
服务熔断 可以理解为 特殊的 服务降级(即 服务不可用 --> 服务降级 --> 服务调用恢复)。
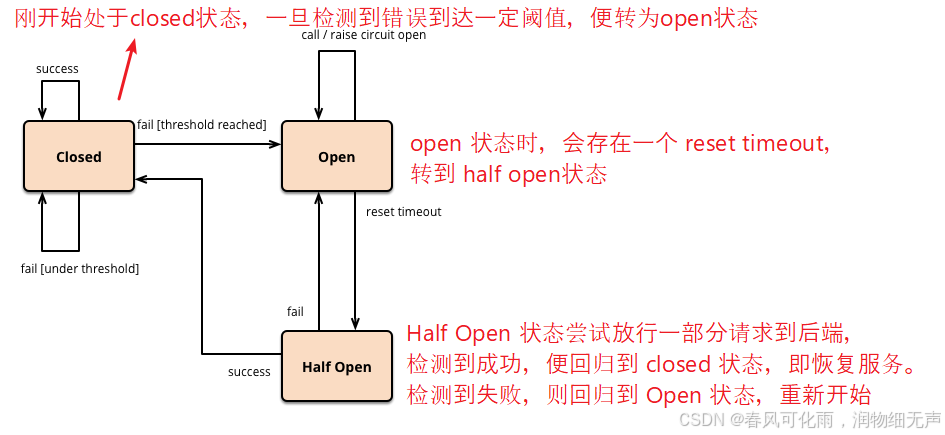
2.代码实现
【服务熔断:】
public Result testCircuitBreakerFallBack(@PathVariable Integer id) {
return Result.ok().message("调用失败, ID 不能为负数");
}@GetMapping("/testCircuitBreaker/{id}")
//配置服务熔断逻辑。 10 秒内请求数达到 10,且 60% 请求调用失败时启断路器,5 秒后重新尝试服务调用;若调用成功,则关闭断路器。若调用失败,则继续开启断路器。
@HystrixCommand(fallbackMethod = "testCircuitBreakerFallBack", commandProperties = {
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3684
3684

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









