






前言
在很多项目,特别是互联网项目,在使用MySQL时都会采用主从复制、读写分离的架构。
为什么要采用主从复制读写分离的架构?如何实现?有什么缺点?让我们带着这些问题开始这段学习之旅吧!
**
为什么使用主从复制、读写分离
**
主从复制、读写分离一般是一起使用的。目的很简单,就是为了提高数据库的并发性能。你想,假设是单机,读写都在一台MySQL上面完成,性能肯定不高。如果有三台MySQL,一台mater只负责写操作,两台salve只负责读操作,性能不就能大大提高了吗?
所以主从复制、读写分离就是为了数据库能支持更大的并发。
随着业务量的扩展、如果是单机部署的MySQL,会导致I/O频率过高。采用主从复制、读写分离可以提高数据库的可用性。
主从复制的原理
①当Master节点进行insert、update、delete操作时,会按顺序写入到binlog中。
②salve从库连接master主库,Master有多少个slave就会创建多少个binlog dump线程。
③当Master节点的binlog发生变化时,binlog dump 线程会通知所有的salve节点,并将相应的binlog内容推送给slave节点。
④I/O线程接收到 binlog 内容后,将内容写入到本地的 relay-log。
⑤SQL线程读取I/O线程写入的relay-log,并且根据 relay-log 的内容对从数据库做对应的操作。

如何实现主从复制
我这里用三台虚拟机(Linux)演示,IP分别是104(Master),106(Slave),107(Slave)。
预期的效果是一主二从,如下图所示:

mv /usr/share/mysql/my-medium.cnf /etc/my.cnf 替换默认配置文件 一般情况下 使用这个的较多
编辑 vim /etc.my.cnf
主库 master
server-id = 100 主要就是用来区分master库和slaver库的
log-bin=mysql-bin 开启master的二进制文件 名字可以自定义
log-slave-update=true 这个手写 开启从库可以读取主库的二进制log 进行update操作
从库 slave
server-id = 200 有几台slave就写几个 不要重复
relay-log=xxx-log-bin 从master同步过来 也要记一下二进制的
relay-log-index=relay-log-bin.index 可以自定义 文件量大 要做个索引
全局配置 做好以后
systemctl enable mariadb 开机自启
systemctl start mariadb 启动数据库
设置个密码 mysql -uroot password ‘xxxxx’
做好这些后 要赋予salve权限 可以从master同步的权限
查看权限的命令 show privileges;
有了这个权限了 得有相应的用户 需要建立一个用户去做这件事情 slave机器就能通过这个用户的这个权限去做这件事了
grant Replication slave on *.* to slaver@'192.168.60.60' identified by 'qweqwe';
flush privileges;刷新 刷新下权限
在salve机器上 看下
show master status;
MariaDB [(none)]> show master status;
+------------------+----------+--------------+------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB |
+------------------+----------+--------------+------------------+
| mysql-bin.000003 | 383 | | |
+------------------+----------+--------------+------------------+
file 就是这个master的二进制文件
Position 二进制文件的编号
slave 就是从 这个二进制文件的这个编号开始同步
从库
change master to master_host='192.168.60.66',master_user='slaver@192.168.60.66',master_password='qweqwe',master_log_file='mysql-bin.000003',master_log_pos=616;
start slave; 开启同步 在slave上做
show slave status\G; 查看状态
二进制文件 /var/lib/mysql/
读写分离
amoba
要有有个中介器来进行连接数据库进行分配权限 就是amoba
首先 既然amoba要链接数据库 要先有一个账号
1 在所有数据库创建账号
grant all on *.* to 'amoba'@'192.168.60.%' identified by '123123';
所有节点都做
2,编辑amebo的配置文件
vim /usr/local/amobe/conf/amoba.xml
<property name="user">root</property> 改下amebo的user 可以自定义
<property name="password">密码</property>
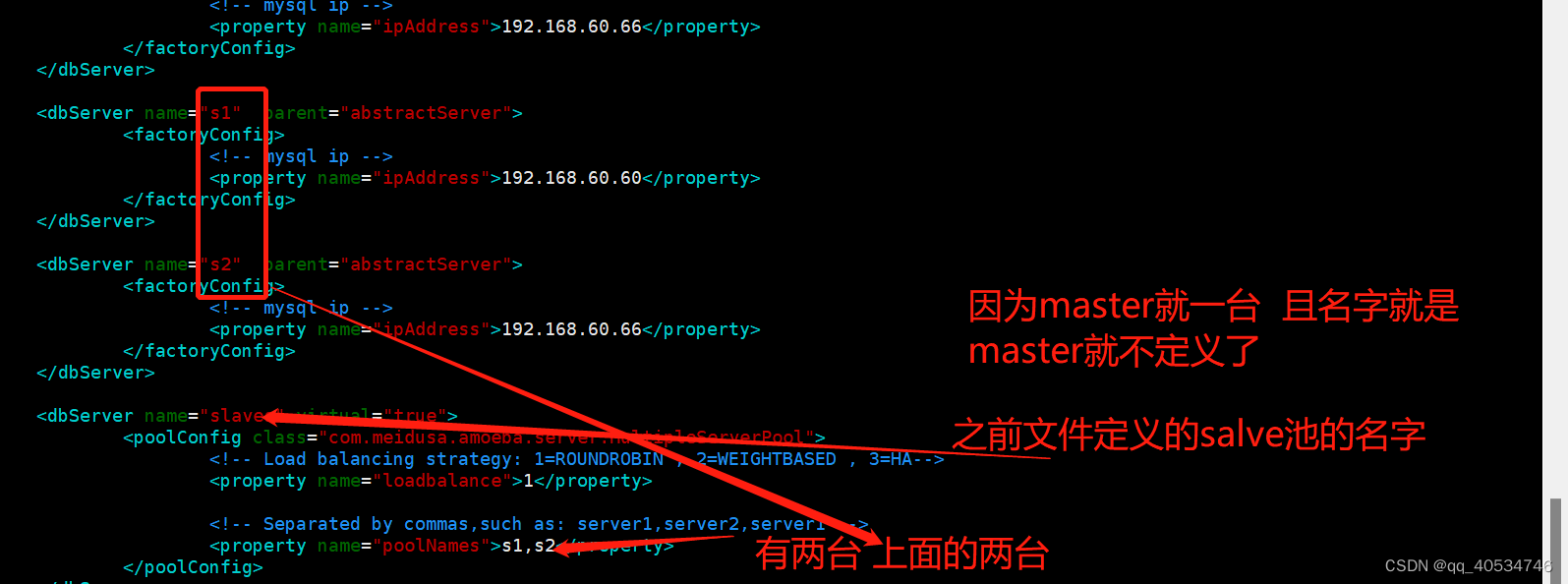
接下来要配置什么呢 既然要实现读写分离 肯定要定义数据库的读池和写池 怎么定义呢
一般client访问进来有个默认的池 可以自定义默认访问的 但要先定义读写池的名字 我这里 写池叫 master 读池叫slavs 所以我定义的默认进来访问的是写池
默认访问进来是进那个组 <property name="defaultPool">master</property>
<property name="writePool">master</property>
<property name="readPool">slaves</property>
到这里 大框架就定义完了
该定义细节了 就是到底谁是master 谁是slaves
在 /usr/local/amoba/amoeba/amoeba-mysql-3.0.5-RC/conf/dbServers.xml 注意 是dbServers.xml这个文件
进来后要定义 连接数据库使用的账号密码
<property name="user">amoba</property>
<property name="password">123123</property>

完成后启动
/usr/local/amoba/amoeba/amoeba-mysql-3.0.5-RC/bin/launcher
创建完后进行 登录 登录这里不是登录数据库 而是登录amoeba服务器登录mysql
mysql -u amoba -p -h 36.107.225.218 -P 8066
这里就是之前定义的amoba的账号密码
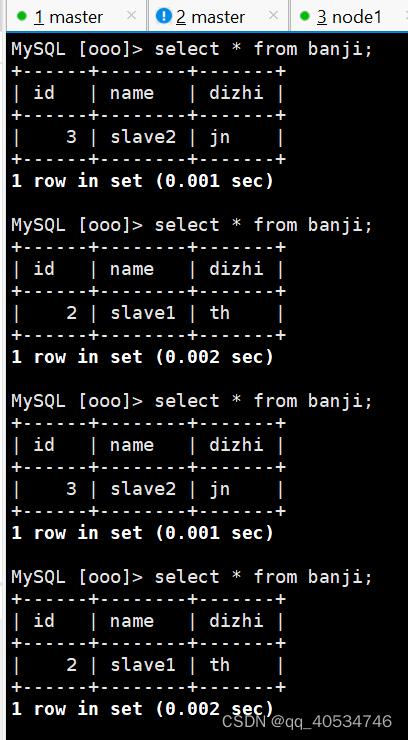
登录上测试主从
create database xxx;
use xxx;
create table tables(id int,name varchar(10),age int);
注意测试读写之前 要将主从先做好。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









