







前言:
本文为记录自己在NeRF学习道路的一些笔记,包括对论文以及其代码的思考内容。
小编目前在探索3DAIGC和3D打印交叉研究,在这方面有想法、经验的朋友都可以在b站留言交流下!欢迎!
公众号: AI知识物语 B站:出门吃三碗饭
论文地址:https://arxiv.org/abs/2404.06429
代码: https://github.com/magic-research/magic-boost?tab=readme-ov-file#code-will-be-released-here
先来看下演示效果

图1:在提供输入图像及其粗略 3D 生成后,MagicBoost 可在 15 分钟内有效地将其提升为高质量 3D 资产。 从左到右为显示输入图像、伪多视图图像和来自 Instant3D 的粗略 3D 结果,以及采用方法产生的显着改善的结果。
摘要
受益于2D扩散模型的快速发展,3D内容创作最近取得了重大进展。 一种有前景的解决方案是对预先训练的 2D 扩散模型进行微调,以利用其生成多视图图像的能力,然后通过快速 NeRF 或大型重建模型等方法将其提升为精确的 3D 模型。 然而,由于不一致仍然存在并且生成的分辨率有限,此类方法的生成结果仍然缺乏复杂的纹理和复杂的几何形状。 为了解决这个问题,我们提出了 Magic-Boost,这是一种多视图条件扩散模型,可通过短暂的 SDS 优化(约 15 分钟)显着细化粗略的生成结果。 与之前基于文本或单图像的扩散模型相比,Magic-Boost 表现出强大的能力,可以从伪合成多视图图像生成高度一致性的图像。 它提供了与输入图像的身份一致的精确 SDS 指导,从而丰富了初始生成结果的几何和纹理的局部细节。大量实验表明,Magic-Boost 极大地增强了粗略输入,并生成具有丰富几何和纹理细节的高质量 3D 资源。
1介绍
最近二维扩散模型的发展激增解锁了新的3D 内容生成的前景。一个特别可行的策略是微调预训练的二维扩散模型,以催化其生成具有多视图一致性的图像,然后将其提升为精确的 3D 模型通过快速 NeRF 或大型重建模型 。 例如,Instant3D首先微调预训练的2D扩散模型以解锁多视图图像生成的能力,然后利用稳健的重建模型导出 3D 表示; Wonder3D微调 2D 扩散具有跨域注意力层的模型,以增强生成输出的 3D 一致性。 尽管这些方法在生成 3D 资产方面非常高效从文本提示或图像来看,生成的结果仍然很粗糙,其特点是缺乏精细的纹理和复杂的几何形状。 这主要是由于由于局部不一致和生成过程的有限分辨率。一个潜在的解决方案是增强此类方法生成的结果与分数蒸馏采样 (SDS) 优化 。 开始于对于粗略的 3D 模型,人们已经努力通过小噪声水平的 SDS 优化,利用文本或单视图条件扩散融合模型来对其进行改进。 然而,我们认为文本和单视图图像条件都不足以提供明确的控制和精确的指导。 这种不足常常导致身份转变、纹理模糊和几何不准确。 具体来说,文本描述固有的歧义对文本条件扩散模型(例如StableDiffusion)提出了挑战和 DeepFoldy-IF,以在整个优化过程中保持一致的身份。 因此,优化结果可能与最初的模型,可能会超出用户的期望。 像 Zero-1-to-3 这样的单视图图像引导扩散模型赋予 2D 扩散模型视点调节的能力。 尽管如此,受限于有限的单视图输入、零一到三及后续方法提供的信息容易产生不可预测和难以置信的结果新视图预测或 SDS 优化期间的形状和纹理,领先扁平的几何形状和模糊的纹理。
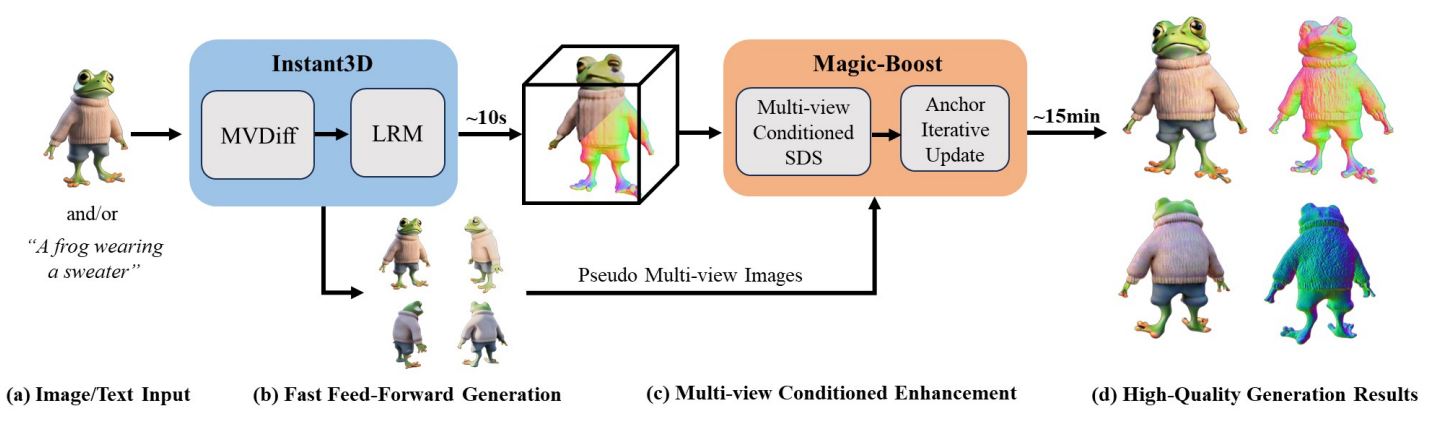
图2 The overall pipeline: 我们用Instant3D 构建 MagicBoost [13](协同作用多视图扩散(MVDiff)和大型重建模型(LRM)),其中提供伪多视图图像以及粗略的 3D 输出。 条件为生成的多视图输入,我们的模型提供精确的 SDS 指导,从而在短时间内(~ 15 分钟)显着增强粗略 3D 输出。
为了解决细化粗糙 3D 生成的挑战,我们提出了 Magic Boost,这是一种摄取(ingests)多视图图像的多视图条件扩散模型作为输入,隐式编码跨不同视图的 3D 信息。 Magic Boost还表现出生成具有高 3D 一致性的图像的强大能力提供与输入的身份完全一致的精确 SDS 指导图像,丰富了初始几何和纹理的局部细节生成的结果。 基于稳定扩散架构,我们引入了一种先进的方法,可以通过以固定时间步长运行的去噪 U-Net,从多视图中有效地提取密集的局部特征。 与之前的情况一致arts ,我们的模型采用自注意力机制来实现不同视图之间的交互和信息共享,从而隐式编码多视图相关性。 然而,完全依赖地面实况用于训练的多视图图像产生的结果并不令人满意。 我们精心开发一系列数据增强策略,包括随机下降、随机尺度和噪声干扰,以促进训练过程,从而性能更强劲。 我们还引入了一个条件标签,允许用户手动调整不同输入视图的影响,增强高保真输入视图的影响,同时减轻低质量输入视图的影响。 到进一步增强优化过程,我们提出了一种新颖的锚点迭代更新损失以解决 SDS 中的过饱和问题,最终得到生成具有逼真纹理的高质量内容。如图2所示,我们的测试框架集成了Instant3D \,这是一种两阶段前馈生成方法,它首先生成四个多视图具有微调的二维扩散模型的图像,然后利用大用于 3D 重建的重建模型。 给定来自 Instant3D 的四个合成多视图图像作为输入,我们的模型能够合成高度一致的新颖观点并提供精准的SDS指导,完善在短时间内(∼ 15 分钟)生成粗略的结果。 综合评估表明 Magic-Boost 显着提高了质量粗略输入,有效生成具有复杂几何形状和真实纹理的更高质量的 3D 资源,
Multi-view Conditioned Diffusion
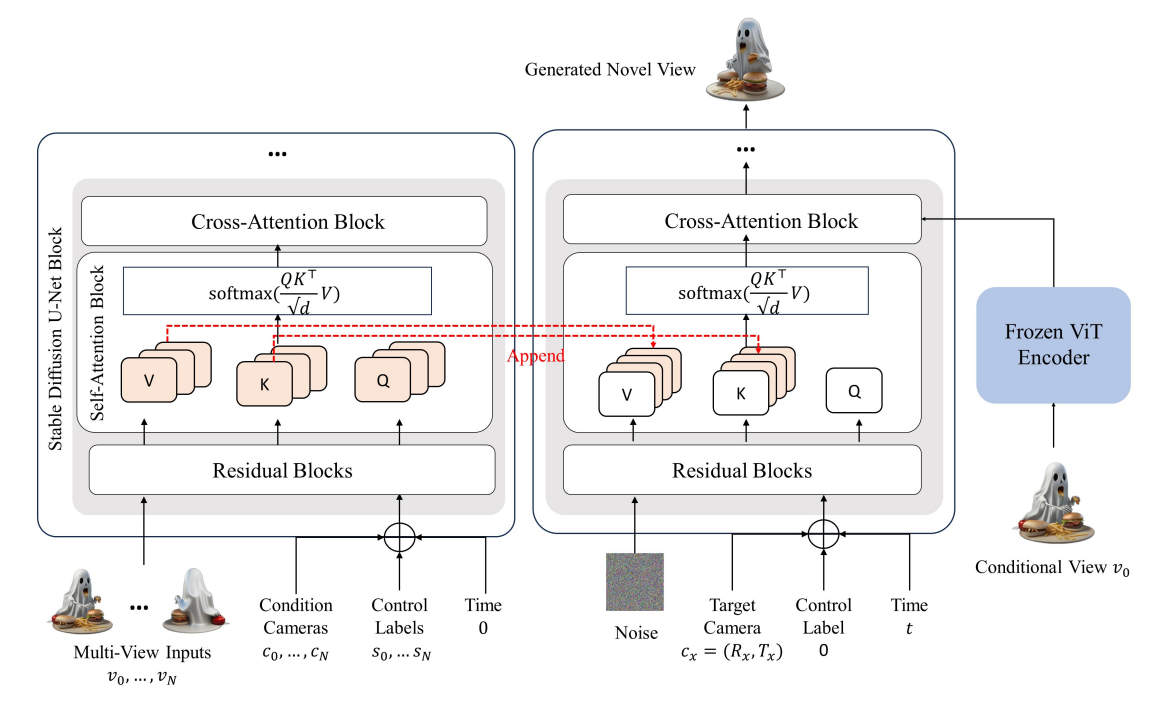
图3 多视图条件扩散模型的架构: 其核心是我们的模型通过去噪 U-Net 来提取密集的局部特征以固定的时间步长运行。 同时,我们利用冻结的 CLIP ViT 编码器提取高电平信号。 原始 2D 自注意力层通过以下方式扩展到 3D连接不同视图中的键和值。 为进一步控制病情不同视图的强度,我们涉及一个条件标签,允许用户手动独立控制不同输入视图的条件强度。
Data Augmentation
使用 Objaverse 渲染的真实多视图图像来训练多视图条件扩散模型。 然而,直接使用这些真实图像进行训练可能会导致推理过程中结果不理想,因为真实多视图图像与测试期间使用的合成图像之间的域差异会产生伪影和不一致的生成结果。 此外,当使用多视图图像进行训练时,模型可能会发展偏向最近的锚视图,忽略其他视图的信息,这可能会导致输出不准确,无法保持 3D 一致性为了解决这些问题,我们提出了几种数据增强策略加强培训过程并确保稳健的绩效:
– 噪音干扰和随机尺度Noise Disturb and Random Scale:为了模拟合成多视图图像中存在的模糊纹理和局部不一致,我们引入噪声干扰增强,它用在不同时间步长采样的高斯噪声扰乱条件多视图图像。 这是耦合的通过随机尺度增强,采用下采样和上采样生成模糊训练输入的方法,从而增强模型的处理此类缺陷的能力。
– 随机掉落Random Drop:规避模型过度依赖的倾向最接近的条件视图,我们实现随机下降增强。 这该技术在训练期间随机忽略条件视图,强制执行网络通过整合信息来合成更一致的结果从所有可用的视图。
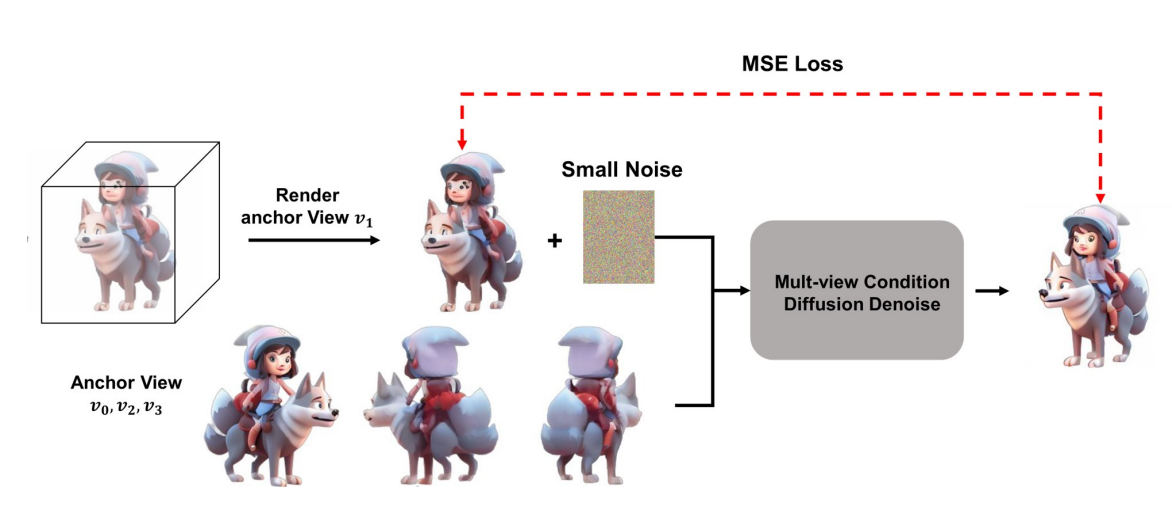
图4: 锚点迭代更新损失
结果


图6 Magic-Boost与其他细化方法之间的定性比较。
从左到右,我们显示输入,然后是 instant3D 的初始结果,并以来自 StableDiffusion Boost、Zero123-XL 的结果告终Boost,以及我们的多视图条件模型。
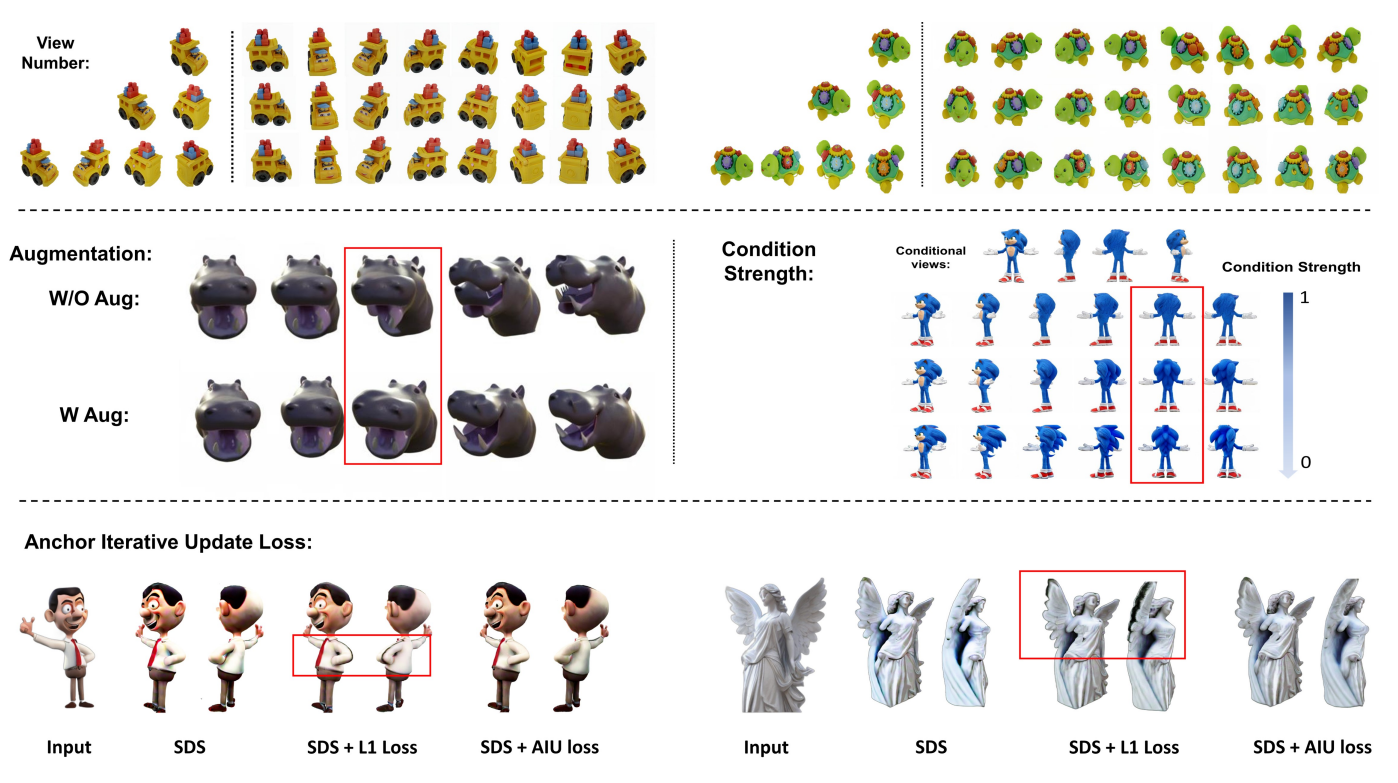
图 7 消融研究:包括条件视图数量、数据增强、Anchor 迭代更新

图 8 与从头开始生成的比较。 考虑到粗略的 3D 模型作为初始化,Magic-Boost的模型能够生成与那些模型相当的高质量结果从头开始生成,需要×5时间(∼1.2h)。
Limitation
Magic-Boost可以有效地生成高质量的输出,但其性能仍受到以下因素的限制:
1)伪3D多视角的使用由精细二维多视图扩散模型合成的图像作为输入对我们模型的性能产生了不可避免的影响。 因此,多视图扩散模型的生成质量直接影响我们模型的表现。 探索具有更好生成能力的二维多视图扩散模型质量将进一步提高我们模型的性能。
2)与文本条件二维扩散相比,我们模型的分辨率 256 × 256 仍然受到限制模型,生成包含更多细节的更高分辨率图像。将我们的模型提升到更高分辨率,例如 512 × 512,将产生卓越的生成结果,允许更复杂的几何形状和细节质地。
Conclusion
本文提出了 Magic-Boost,一种多视图条件扩散模型,该模型采用伪生成的多视图图像作为输入,隐式编码 3D 信息来自不同的视角,并能够综合高度一致的新颖观点图像并在优化过程中提供精确的 SDS 指导。大量实验证明我们的模型极大地提高了生成率粗略输入的质量,并在短时间内生成具有详细几何形状和逼真纹理的高质量 3D 资源。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









