







12.2-1 假设一棵二叉搜索树中的结点在1到1000之间,现在想要查找值为363得到结点,下面序列那个不是查找过的序列。
a. 2,252,401,398,330,344,397,3632,252,401,398,330,344,397,3632,252,401,398,330,344,397,363。
b. 924,220,911,244,898,258,362,363924,220,911,244,898,258,362,363924,220,911,244,898,258,362,363。
c. 925,202,911,240,912,245,363925,202,911,240,912,245,363925,202,911,240,912,245,363。
d. 2,399,387,219,266,382,381,278,3632,399,387,219,266,382,381,278,3632,399,387,219,266,382,381,278,363。
e. 935,278,347,621,299,392,358,363935,278,347,621,299,392,358,363935,278,347,621,299,392,358,363。
因为这是查找BST过程中的一个序列,因此根据该序列构造BST,如果满足BST的性质,那么就是查找的序列,否则不是。其中c和e不满足。
12.2-2 写出TREE-MINIMUM和TREE-MAXIMUM的递归版本。
//根据书上的版本写的,书中没有判断x是否为空的情况
TREE-MINIMUM(x)
if x.left == NIL
return x
return TREE-MINIMUM(x.left);
TREE-MAXIMUM(x)
if x.right == NIL
return x
return TREE-MAXIMUM(x.right)
12.2-3 写出过程TREE-PREDECESSOR的伪代码
与书上的TREE-SUCCESSOR想对称
TREE-PREDECESSOR
if x.left != NIL
return TREE-MAXIMUM(x.left)
y = x.p
while y != NIL and y.left == x
x = y
y = y.p
return y
12.2-4 Bunyan教授认为他发现了一个二叉搜索树的重要性质。假设在一棵二叉搜索树中查找一个关键字kkk,查找结束于一个树叶。考虑三个集合:AAA为查找路径左边的关键字集合;BBB为u查找路径上的关键字集合;CCC为查找路径右边的关键字集合。Bunyan教授声称:∀a∈A,b∈B,c∈C\forall a \in A,b \in B, c \in C∀a∈A,b∈B,c∈C,一定满足a≤b≤ca \leq b \leq ca≤b≤c。请给出该教授这个论断的一个最小可能的反例。
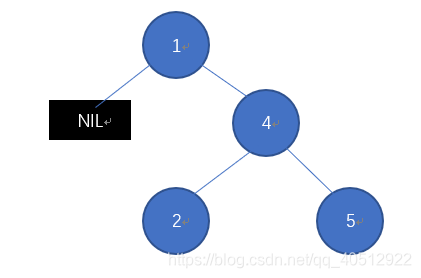
查找5,那么B={1,4,5},A={2},C={}B=\{1,4,5\},A=\{2\},C=\{\}B={1,4,5},A={2},C={}, 显然不成立。
12.2-5 证明:如果一棵二叉搜索树中一个结点有两个孩子,那么它的后继没有左孩子,它的前驱没有右孩子。
证明:反证法,设结点为xxx,它的前驱为preprepre,那么对于BST的中序遍历序列为 <…−pre−x−…><\dotsc-pre-x-\dotsc><…−pre−x−…> ,假如preprepre存在右孩子ppretppretppret,那么在中序遍历时,遍历完成preprepre后接着遍历ppreppreppre,这与之前中序遍历的序列相矛盾。即xxx的前驱preprepre不存在右孩子。同理xxx的后继结点不存在左孩子。
12.2-6 考虑一棵二叉搜索树TTT,其关键字互不相同。证明:如果TTT中一个结点xxx的右子树为空,且xxx有一个后继yyy,那么yyy一定是xxx的最底层的祖先,并且左孩子也是xxx的祖先。(注意到,每个结点都是它自己的祖先。)
证明:
首先确定yyy是xxx的祖先,如果yyy不是xxx的祖先,设x,yx,yx,y的第一个共同祖先为zzz,那么根据BST的性质有,x<z<yx < z < yx<z<y(因为x没有右子树,那么y只能存在于z的右子树,而x存在于z的左子树,否则就无法满足y为x后继即 x<y的关系),那么xxx的后继不再是yyy,因此假设不成立。yyy为xxx的祖先得证。
接下来证明y.lefty.lefty.left是xxx的祖先。假设y.lefty.lefty.left不是xxx的祖先,那么y.righty.righty.right将是xxx的祖先,意味着x>yx > yx>y,矛盾。因此y.lefty.lefty.left是xxx的祖先。
最后证明yyy是xxx的最底层祖先,同时y.lefty.lefty.left也是xxx的祖先。假设yyy不是xxx的最底层祖先但是y.lefty.lefty.left是xxx的祖先,令zzz表示最底层祖先,zzz一定是yyy的左子树,因此有z<yz < yz<y,意味着zzz是xxx的后继,矛盾,假设不成立。
12.2-7 对于一棵有nnn个结点的二叉搜索树,有另一个方法实现中序遍历,先调用TREE-MINUMUM找到这棵树中的最小元素,然后再调用n-1次的TREE-SUCCESSOR。证明:该算法的时间复杂度为Θ(n)\Theta(n)Θ(n)。
证明:我们要想证明这个边界,其实不难实现,可以通过再TREE-MINIMUM和TREE-SUCCESSOR中统计访问边的次数,对于BST是树,因此满足边的次数=顶点数-1。不难发现每条边访问次数不超过两次,同时每个顶点需要访问依次,因此时间复杂度为Θ(n)\Theta(n)Θ(n)
下面证明对于每一条边最多访问两次:一次从下降(从高到低),一次上升(从低到高)
考虑在树中的一个点uuu,还有它的孩子vvv。我们需要先访问从(u,v)(u,v)(u,v),才能访问(v,u)(v,u)(v,u)。对于下降,只有出现在TREE-MINIMUM,对于上升,只有出现在TREE-SUCCRSSOR并且该结点没有右孩子。
假设vvv是uuu的左孩子
在打印uuu之前,我们需要打印uuu的左子树,保证下降的遍历边(u,v)(u,v)(u,v)
vvv为根的左子树遍历完成后,打印uuu。从vvv为根的左子树的最大结点,调用TREE-SUCCESSOR中,上升遍历边(u,v)。当uuu的左子树遍历完成后,边(u,v)(u,v)(u,v)不再访问。
假设vvv是uuu的右孩子
当uuu打印后,TREE-SUCCESSOR(u)被调用,为了访问vvv为根的右子树的最小元素,需要下降的遍历边(u,v)(u,v)(u,v)。
当uuu的右子树遍历完成后,vvv为根的右子树的最大结点,调用的TREE-SUCCRSSOR,上升遍历边(u,v)(u,v)(u,v)。当uuu的右子树遍历完成后,边(u,v)(u,v)(u,v)不再访问。
因此,每条边访问次数不会超过2次。时间复杂度为Θ(n)\Theta(n)Θ(n)
12.2-8 证明:在一棵高度为hhh的二叉搜索树中,不论从哪个结点开始,kkk次连续的TREE-SUCCESSOR调用所需时间为Θ(k+h)\Theta(k+h)Θ(k+h)。
我们记调用TREE-SUCCESSOR的结点为xxx,令yyy为xxx的第kkk个后继结点,zzz为x,yx,yx,y的最底层公共祖先。连续调用TREE-SUCCESSOR类似树的遍历,每条边的遍历次数不超过2次,所以我们不会检查一个结点超过3次。另外,任何结点关键字不是在x,yx,yx,y之间最多检查一次,发生在一条从<x−…−…z><x-\dotsc-\dotsc z><x−…−…z>或<y−…−…−z><y-\dotsc-\dotsc -z><y−…−…−z> (路径)。这些路径的长度由yyy限制,因此最坏情况时间复杂度为3k+2h=O(k+h)3k+2h=O(k+h)3k+2h=O(k+h)。
12.2-9 设TTT是一颗二叉搜索树,其关键字互不相同;设xxx是一个叶结点,yyy为其父结点。证明:y.keyy.keyy.key或者TTT树中大于x.keyx.keyx.key的最小关键字,或者是TTT树中小于x.keyx.keyx.key的最大关键字。
证明:假设xxx是yyy的左孩子,那么xxx的后继是yyy,即y.keyy.keyy.key是TTT树种大于x.keyx.keyx.key的最小关键字,若xxx是yyy的右孩子,那么yyy的前驱是xxx,即y.keyy.keyy.key是TTT树小于x.keyx.keyx.key的最大关键字。

















 1140
1140

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









