






强化学习是机器学习的一个子类别,智能体学习在环境中的行为。机器学习的其他流行子类别是监督学习和无监督学习。强化学习与监督学习和无监督学习不同,因为你为实现目标而采取的行动顺序对于当前的问题很重要。
监督学习是使用基本事实来完成的。因此,监督学习的目标是学习样本数据和真实结果之间的函数或映射。监督学习的流行用途包括回归和分类。
无监督学习是没有标记的基本事实。因此,无监督学习的目标是在不使用明确提供的真实标签的情况下推断样本数据的固有结构。无监督学习的一个流行用途是聚类。
强化学习不需要预先存在的 ground truth,它通过尝试和错误来体验环境来学习行为(一组动作)。这可以是真实世界环境或模拟世界。智能体在环境中尝试不同的操作,直到他开始学习要采取的最佳操作。因此,强化学习的目标是学习实现目标的最佳行为。
强化学习的成功用例包括:机械臂操作、Google DeepMind 击败专业 Alpha Go 选手、Google DeepMind 击败多款 Atari 游戏、Google DeepMind 训练类人机器人自行行走、Unity 教小狗如何行走和玩耍fetch,OpenAI 团队击败了职业 DOTA 玩家。
智能体agent与环境
在进行强化学习时,要尝试理解的第一个概念是,其中很多内容都是作为智能体与环境之间的对话而发生的。您可以想象您是视频游戏环境中的智能体。你是智能体。电子游戏环境就是环境。对话是智能体和环境之间来回进行的内容。
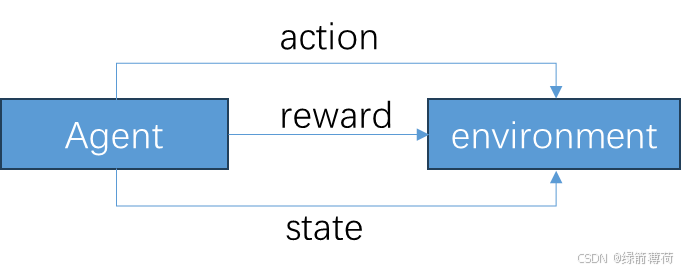
agent并不了解所有环境,您(agent)只能通过与环境的一组交互来体验环境。如果你经常与环境互动,那么你就可以在头脑中建立某种环境模型。但请注意,您构建的环境模型和实际环境不一定是同一件事。换句话说,智能体不了解环境,智能体只是通过与环境交互来体验环境。所有的计算都发生在agent的大脑中。
如果所有环境都是已知的,那么agent将不需要进行任何学习,而问题只是根据现有的已知环境来计划要做什么。这给我们带来了计划和学习之间的区别。当您不了解模型/环境时,就会发生学习。您确实了解模型/环境时,就会进行规划。规划也许可以在您自己的家里或当地的街道上进行,因为您了解它们。学习可能发生在花园迷宫或您以前从未去过的新主题公园中。只有了解环境并有模型后才能进行规划。
通过经验学习
当我们将代理放入环境中时,该环境将具有agent可以存在于其中的状态,并且环境也将具有agent可以执行的操作。
这个环境可以是游戏,也可以是现实世界。
采取行动可以将您转变到另一种状态。
采取行动也可以获得奖励。
然而,与常规游戏不同,你不知道规则。你不知道事情是如何运作的。你甚至不知道你应该做什么。但你能做的就是开始玩并利用这种经验来开始发现事情是如何运作的。
如果你选择一个行动,那么环境会告诉你是否获得奖励以及是否移动到另一个状态。有些行为可能会给你奖励,有些可能不会(取决于你的状态)。有些操作可能会改变您的状态,有些可能不会(取决于您的状态)。
例如,“前进行动”可能会推动你前进;然而,如果你站在墙前,“前进行动”可能不会让你前进。另一个例子是“拾取动作”可能拾取你下面的一个物体;但是,如果您下方没有物体,那么“拾取动作”可能不会执行任何操作。
当您开始游戏时,您不知道这些环境规则。因此,作为agent,您只需尝试不同的行动,看看会发生什么。另外,请记住,虽然“前进动作”或“拾取动作”可能对您(作为有生活经验的人)有意义,但agent不知道“前进动作”或“拾取动作”的作用,并且它可能是我们将其称为“行动 1”或“行动 2”。
您可以将智能体视为从没有生活经验的婴儿开始。
另一个例子是,智能体最初并不知道“墙”是什么,因此它必须了解当你撞到墙时会发生什么。
正如您所看到的,智能体比人类更难了解状态-动作对 可能会做什么。最终,智能体可能会了解环境是如何运作的。这种理解可能是正确的,也可能是错误的,或更可能介于两者之间。您只知道您想要最大化一路上收集的奖励。
奖励最大化Maximizing Rewards
对于在您的某个状态下采取的每项行动,您都会收到奖励。您可以将奖励视为积极奖励、消极奖励或中性奖励。奖励越高越好。如果你赢得了游戏,你可能会获得极高的正向奖励。如果你掉进坑里,你可能会输掉游戏并获得极其负面的奖励。一路走来,你可以获得较小的正向和负向奖励。
例如,如果您更接近目标,那么每次您更接近目标时,您都可能会获得一点积极的奖励。另一方面,如果您在电子游戏中失去生命值或在国际象棋比赛中失去棋子,那么您可能会收到少量的负面奖励。可能有些操作根本不会影响您的目标,因此您可能会收到零的中性奖励。
在你在环境中的体验过程中,你获得了一笔奖励,称为回报。与环境交互的目标是最大化总回报。
因此,您可能会在玩一场电子游戏时,如果走进坑,您就会输掉游戏,这可能会导致总回报较低。同一视频游戏的另一次运行可能会尝试另一个动作(例如跳跃),这可能会导致不掉入坑中并获得更高的总回报。通过反复试验,智能体可以了解在某些状态下什么是好的行为,什么是坏的行为。
随机环境 Stochastic Environment
到目前为止,我们一直在考虑一个确定性环境,其中任何状态-动作对都会发生同样的事情。但是,如果给定的状态-动作对有时会发生不同的事情怎么办?这就是我们所说的随机环境。大多数现实生活环境都是随机的。如果您穿过十字路口并且有车辆驶入,那么您将不会继续前进,相反您的汽车会与另一辆车相撞。
因此,在给定状态(例如交叉路口)下,同一操作并不总是会发生相同的情况。
为了解释这一点,我们创建了一个概率模型,该模型可能表示 20% 的时间有迎面而来的交通,80% 的时间没有迎面而来的交通。随机环境的这一部分就是所谓的概率转换函数。
对环境建模的一个好方法是通过马尔可夫决策过程 (MDP)
固定政策 Stationary Policy
通过强化学习算法,我们正在尝试学习行为。我们正在尝试学习一种与环境互动的方式,从而获得高回报。您可能用计划或条件计划表示的行为,但强化学习算法更喜欢将行为表示为通用计划(又名固定策略)。
计划是一系列固定的行动。假设没有交通并且所有的停车灯都是绿色的,那么您要做的就是按照计划从工作地点到家(例如,“向左”、“向左”、“向上”、“向左”、“左”、“下”)。
然而,这些假设在现实生活中并不总是成立。某个路口可能会堵车,所以最好有一个有条件的计划。条件计划允许您在特定状态下选择不同的操作。大多数计划是固定的,但可能有一两个条件状态根据条件提供不同的操作。
另一方面,通用计划与条件计划类似,只是它对每个状态都有一个条件。这与计划或条件计划不同,后者只需要担心从 A 点到 B 点的状态。通用计划将对环境中的每个状态都有一组条件操作。
如果您的环境是您的城市,并且您的目标是从工作地点到家,那么您将在城市的每个十字路口执行一组有条件的操作。您将知道在环境中的每个状态下要做什么,而不仅仅是实现您目标的状态列表。
强化学习专注于固定策略,因为它们使我们能够表达最佳行为。这是非常强大的,但也非常大,这使得大型状态空间变得困难。想象一个连续的状态空间,它无限大。深度强化学习是解决这个庞大问题的一种方法。
开发与探索
强化学习算法中出现的一个普遍主题是利用与探索。如果您的算法始终利用其模型知识,那么它可能只会找到局部最优值,因为它忽略了可能产生更高回报的其他最优点。这就是探索的用武之地。如果你想发现是否有其他局部最优比你已经找到的更好,那么你需要去探索。这并不意味着你应该一直探索或者一直利用,但你应该在两者之间找到平衡。
注:强化学习有一些与具身智能相同的原则,特别是与学习相关的原则,但没有头脑 (LLM 推理) 和世界 (视觉推理) 推理和处理知识的能力。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









