







#作者:张桐瑞
文章目录
前言
在大数据处理领域,Kafka 凭借其卓越的性能、高可靠性以及高扩展性,成为了消息队列系统的佼佼者。而在 Kafka 的核心架构中,高水位(High Watermark,简称 HW)和 Leader Epoch 机制扮演着至关重要的角色,它们对于保障数据的一致性、消息的有序处理以及集群的高可用性起到了决定性作用。接下来,我们将深入探究这两个机制的详细原理、应用场景以及它们之间的协同工作方式。
高水位:Kafka 消息处理的关键指标
高水位的定义
在 Kafka 的语境里,高水位与我们在其他流式处理框架(如 Spark Streaming、Flink)中所见到的水位概念存在显著差异。在那些框架中,水位往往与时间紧密相连,用于标记最早未完成工作的时间戳。但 Kafka 的水位与时间毫无关系,它是通过消息位移来进行精确表征的。Kafka 源码中统一使用 “高水位” 这一术语,为了保持一致性,我们在本文中也将使用这一表述,偶尔会用其缩写 HW 来指代。这里需要提及的是,Kafka 中还存在低水位(Low Watermark),不过它主要与 Kafka 删除消息的操作相关联,与我们当前讨论的重点内容关联度较低,因此暂不深入探讨。
为了更直观地理解高水位的概念,我们可以将 Kafka 的消息存储类比为一个有序的消息队列。在这个队列中,每个消息都有一个唯一的位移标识,就如同队列中的位置编号。而高水位则像是一个特殊的 “指针”,它标记了在这个分区中,哪些消息已经可以被安全地认为是 “稳定” 的,即可以被消费者消费的。
高水位的作用
1.界定消息可见性
高水位在 Kafka 中最为重要的作用之一,就是明确了分区内消息对于消费者的可见性。简单来说,在分区高水位以下的消息被认定为已提交消息,这些消息是可以被消费者正常消费的;而位移值恰好等于高水位的消息,依然属于未提交消息,消费者无法对其进行消费。需要注意的是,这里我们暂未考虑 Kafka 事务的情况。在事务机制下,消费者所能看到的消息范围判断更为复杂,它不仅仅依赖高水位,而是依靠一个名为 LSO(Log Stable Offset)的位移值来确定事务型消费者的消息可见性。这是因为事务涉及到一组消息的原子性操作,需要更精细的控制来保证数据的一致性。
2.助力副本同步
在 Kafka 的副本同步机制中,高水位发挥着不可或缺的作用。Kafka 通过多副本机制来保障数据的可靠性和高可用性,每个分区都有一个 Leader 副本和多个 Follower 副本。高水位作为一个关键的同步指标,确保了各个副本之间数据的一致性。它就像是一个同步的 “节拍器”,控制着 Leader 副本和 Follower 副本之间的数据同步节奏,使得 Follower 副本能够尽可能地与 Leader 副本保持数据一致。
高水位的更新机制
在 Kafka 的架构中,每个副本对象都维护着一组重要的属性,即高水位和日志末端位移(Log End Offset,简称 LEO)。其中,Leader 副本的高水位具有特殊地位,它直接决定了所在分区的高水位。在 Leader 副本所在的 Broker 节点上,不仅保存着自身的高水位和 LEO 信息,还记录了其他 Follower 副本的 LEO 值,这些 Follower 副本在这种情况下被称为远程副本。不过,需要注意的是,远程副本的高水位并不会在 Leader 副本所在的 Broker 0 上进行更新,而是在各自所在的 Broker 上进行更新操作。
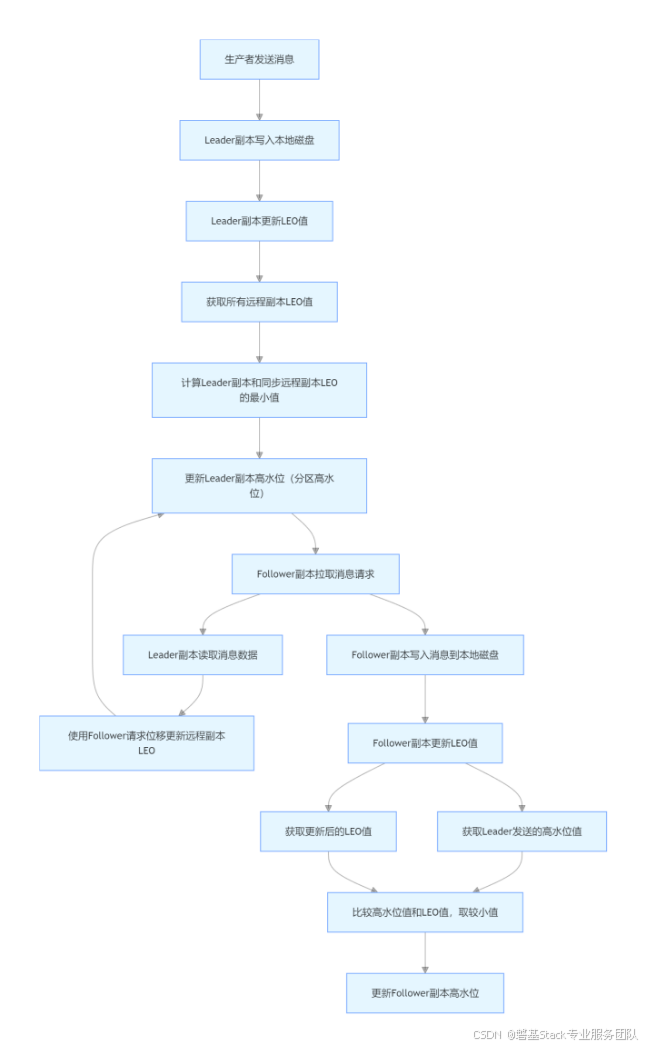
下面我们详细介绍高水位的更新时机和具体过程:
-
Follower 副本:当 Follower 副本从 Leader 副本拉取消息并成功写入本地磁盘后,会立即更新自身的 LEO 值,这表明 Follower 副本已经成功接收并存储了新的消息。之后,Follower 副本会将自身更新后的 LEO 值与 Leader 副本发送过来的高水位值进行比较,取两者中的较小值来更新自己的高水位。这种更新方式确保了 Follower 副本不会将尚未在 Leader 副本上稳定的消息标记为可消费状态,从而保证了数据的一致性。
-
Leader 副本:在处理生产者请求时,Leader 副本首先会将消息写入本地磁盘,这是确保数据持久性的关键步骤。写入成功后,Leader 副本会更新自身的 LEO 值,以反映最新的消息存储位置。接着,Leader 副本会获取所有远程副本的 LEO 值,然后计算 Leader 副本自身的 LEO 值和所有与 Leader 同步的远程副本 LEO 值中的最小值,并用这个最小值来更新分区的高水位。这里判断远程 Follower 副本是否与 Leader 同步需要同时满足两个条件:其一,该远程 Follower 副本必须在 ISR(In - Sync Replicas,同步副本集合)中;其二,该远程 Follower 副本的 LEO 值落后于 Leader 副本 LEO 值的时间不能超过 Broker 端参数replica.lag.time.max.ms所设定的时间,默认情况下这个时间为 10 秒。在处理 Follower 副本拉取消息的请求时,Leader 副本会先读取磁盘(或页缓存)中的消息数据,然后使用 Follower 副本发送请求中的位移值来更新远程副本的 LEO,最后按照上述相同的规则来更新分区的高水位。
副本同步机制
基于高水位的协同运作
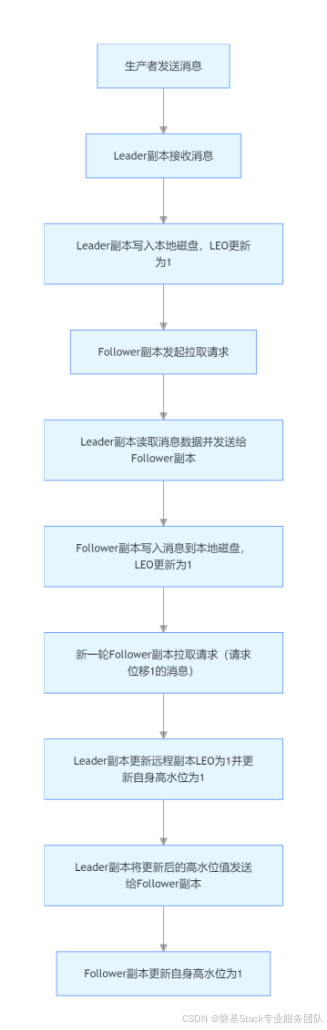
为了更深入地理解 Kafka 如何利用高水位实现副本同步,我们以一个单分区且包含两个副本(Leader 副本和 Follower 副本)的主题为例,详细阐述整个同步过程。
在初始状态下,Leader 副本、Follower 副本的高水位和 LEO 以及远程副本的 LEO 值均为 0,这表示此时该分区还没有任何消息写入。当生产者向该主题分区发送一条消息后,Leader 副本会首先接收这条消息,并成功将其写入本地磁盘。此时,Leader 副本的 LEO 值会更新为 1,这意味着 Leader 副本已经存储了一条新消息,并且准备接收下一条消息的位移为 1。
Follower 副本会定期从 Leader 副本拉取消息。在之前没有消息时,拉取操作可能不会获取到任何数据,但当生产者发送消息后,Follower 副本再次尝试拉取时,就会有消息可供拉取。Follower 副本成功将拉取到的消息写入本地磁盘后,其 LEO 值也会更新为 1。然而,此时 Leader 副本和 Follower 副本的高水位依然保持为 0,这是因为高水位的更新需要满足特定的条件。
在新一轮的拉取请求中,由于位移值为 0 的消息已经被 Follower 副本成功拉取,所以 Follower 副本这次会请求拉取位移值为 1 的消息。Leader 副本接收到这个请求后,会先更新远程副本(即 Follower 副本)的 LEO 为 1,这表示 Leader 副本已经确认 Follower 副本可以同步到这个位置的消息。然后,Leader 副本会更新自身的高水位为 1,这是因为此时 Leader 副本和 Follower 副本的 LEO 值都为 1,满足了高水位更新的条件。最后,Leader 副本会将当前已更新过的高水位值 1 发送给 Follower 副本,Follower 副本接收到这个高水位值后,也会将自己的高水位值更新成 1。至此,一次完整的消息同步周期就顺利结束了。Kafka 正是通过这样一套严谨的机制,实现了 Leader 副本和 Follower 副本之间的高效同步,确保了数据在多个副本之间的一致性。
Leader Epoch:弥补高水位缺陷的创新设计
Leader Epoch 的引入背景
尽管高水位机制在 Kafka 的日常运行中发挥了重要作用,但随着 Kafka 应用场景的不断拓展和使用规模的逐渐增大,其潜在的问题也逐渐暴露出来。其中一个较为突出的问题就是 Leader 副本高水位更新和 Follower 副本高水位更新在时间上存在错配。这种错配在一些极端情况下可能会引发严重的数据丢失或数据不一致问题。例如,在一个包含多个 Follower 副本的集群环境中,由于各个 Follower 副本的同步速度可能存在差异,Follower 副本的高水位更新可能需要多轮拉取请求才能完成。在这个过程中,如果恰好发生了 Broker 宕机等异常情况,就有可能导致部分消息在某些副本上丢失,从而破坏了数据的一致性。
为了解决这些问题,Kafka 社区在 0.11 版本中引入了 Leader Epoch 概念,旨在通过一种全新的机制来规避因高水位更新错配所导致的各种不一致问题,进一步提升 Kafka 集群的稳定性和可靠性。
Leader Epoch 的定义与原理
Leader Epoch 可以简单理解为 Leader 的版本号,它由两部分重要的数据组成:
-
Epoch:这是一个单调增加的版本号。每当 Kafka 集群中发生副本领导权的变更时,这个 Epoch 值就会增加。可以将其想象成一个 “世代” 的概念,小版本号的 Leader 就像是已经 “过时” 的领导者,在新的 Epoch 下,它们将不再具备行使 Leader 权力的资格。
-
起始位移(Start Offset):它指的是 Leader 副本在该 Epoch 值上写入的首条消息的位移。通过记录这个起始位移,Kafka 可以准确地追踪每个 Leader 副本在不同阶段所写入的消息位置,从而更好地管理数据的一致性和完整性。
例如,假设现在存在两个 Leader Epoch,分别为 <0, 0> 和 < 1, 120>。这意味着第一个 Leader Epoch 的版本号为 0,在这个版本的 Leader 统治期间,它从位移 0 开始保存消息,并且一共保存了 120 条消息。之后,集群中发生了领导权变更,新的 Leader 诞生,其 Epoch 版本号增加到 1,并且从位移 120 开始写入新的消息。
Kafka Broker 会在内存中为每个分区专门缓存 Leader Epoch 数据,这就像是一个 “记忆仓库”,记录着每个分区的 Leader 变更历史和对应的消息起始位置。同时,为了防止数据丢失,Broker 还会定期地将这些重要的信息持久化到一个 checkpoint 文件中。当 Leader 副本向磁盘写入消息时,Broker 会根据一定的规则尝试更新这部分缓存。如果该 Leader 是首次写入消息,那么 Broker 会向缓存中添加一个新的 Leader Epoch 条目;否则,一般情况下不会对缓存进行更新。这样,每当有新的 Leader 副本上任时,它就可以通过查询这部分缓存,获取到对应的 Leader Epoch 的起始位移,从而避免在领导权变更过程中出现数据丢失和不一致的情况。
Leader Epoch 防止数据丢失示例
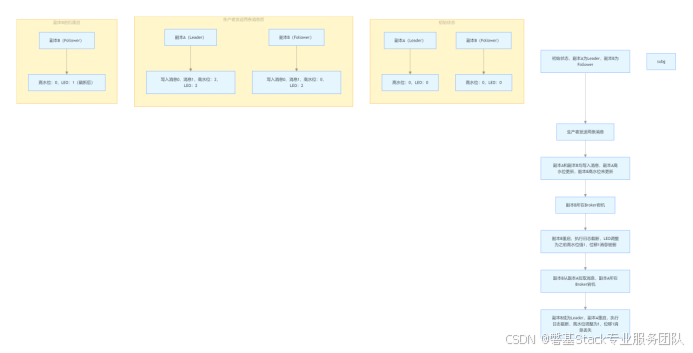
下面我们通过一个具体的示例来展示 Leader Epoch 机制是如何防止数据丢失的。假设在 Kafka 集群中有两个副本 A 和 B,其中副本 A 是当前的 Leader 副本。此时,一个使用了默认 acks 设置的生产者程序向副本 A 发送了两条消息,副本 A 成功地将这两条消息全部写入磁盘,并且 Kafka 会通知生产者这两条消息已经全部发送成功。
在理想情况下,Leader 副本和 Follower 副本都会及时写入这两条消息,并且 Leader 副本的高水位也会相应地进行更新。然而,由于高水位更新存在时间错配的问题,Follower 副本的高水位可能不会立即更新。此时,如果副本 B 所在的 Broker 突然宕机,当它重启回来后,副本 B 会执行日志截断操作,这是为了确保与当前集群状态保持一致。在这种情况下,副本 B 会将 LEO 值调整为之前的高水位值,假设这个值为 1。这就意味着,位移值为 1 的那条消息会被副本 B 从磁盘中删除,此时副本 B 的底层磁盘文件中就只保存了位移值为 0 的那条消息。
当副本 B 完成截断操作后,它会开始从副本 A 拉取消息,执行正常的消息同步操作。但如果就在这个关键时刻,副本 A 所在的 Broker 也宕机了,那么 Kafka 集群就会进行 Leader 选举,在这种情况下,副本 B 会成为新的 Leader。当副本 A 重启回来后,为了保持数据一致性,它也需要执行相同的日志截断操作,即将高水位调整为与副本 B 相同的值,也就是 1。经过这样的操作之后,位移值为 1 的那条消息就会从这两个副本中被永远地删除,从而导致了数据丢失。
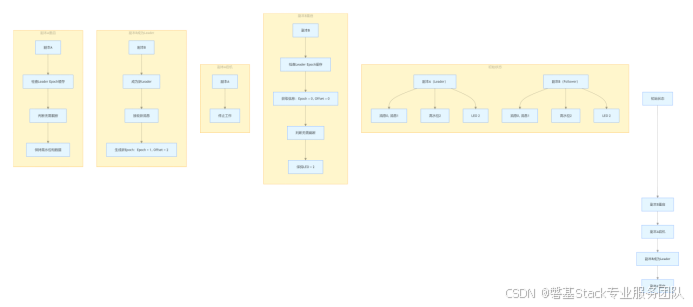
现在,我们来看一下引入 Leader Epoch 机制后,情况会发生怎样的变化。同样是上述的场景,当副本 B 重启回来后,它会向副本 A 发送一个特殊的请求,用于获取副本 A 的 LEO 值。在这个例子中,假设副本 A 的 LEO 值为 2。副本 B 在获知到这个 LEO 值后,会进行一系列的判断。它发现该 LEO 值并不比自己当前的 LEO 值小,并且在缓存中也没有保存任何起始位移值大于 2 的 Epoch 条目。基于这些判断,副本 B 无需执行任何日志截断操作。这是 Leader Epoch 机制相对于高水位机制的一个显著改进,它使得副本是否执行日志截断操作不再仅仅依赖于高水位进行判断,而是结合了更多的信息,从而更加准确地保障了数据的完整性。
接下来,当副本 A 宕机后,副本 B 成为了新的 Leader。当副本 A 重启回来后,它会执行与副本 B 相同的逻辑判断,同样发现不需要执行日志截断操作。这样一来,位移值为 1 的那条消息在两个副本中都得到了保留。之后,当生产者程序向副本 B 写入新消息时,副本 B 所在的 Broker 缓存中会生成新的 Leader Epoch 条目:[Epoch = 1, Offset = 2]。这个新的条目将用于帮助副本 B 在后续的操作中判断是否需要执行日志截断操作,从而进一步保障了数据的一致性和可靠性。
高水位和 Leader Epoch 机制共同构成了 Kafka 数据管理和同步体系的核心支柱。高水位作为基础机制,为消息的可见性和副本同步提供了基本的保障;而 Leader Epoch 则像是一个 “补丁”,有效地修复了高水位机制存在的缺陷,进一步提升了 Kafka 在复杂环境下的数据一致性和可靠性。这两个机制相互配合,使得 Kafka 能够在大规模数据处理和高并发消息传递的场景中稳定、高效地运行,成为了众多企业和开发者的首选消息队列解决方案。



















 510
510

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









