







#作者:猎人
背景:
K8s :v1.19.12
部署企业套件es 版本: 7.8.1
问题:
- es节点异常报警,集群状态为red
- es节点不断重启
- 数据损坏
原因:
- es属主属组不对,导致es没有权限从而无限重启
- 由于重启导致的数据损坏,而且副本集都为零,导致无法恢复数据
解决简介:
- 调整属主属组,重启问题解决
- 通过命令行修改对应的索引副本数解决.
- 尝试备份并重新分片
一、发现故障
在日常巡检中发现某核心项目中的企业套件es无限的重启问题,
二、日志分析
再将相关pod删除之后再次重启之后故障依旧,遂查看日志
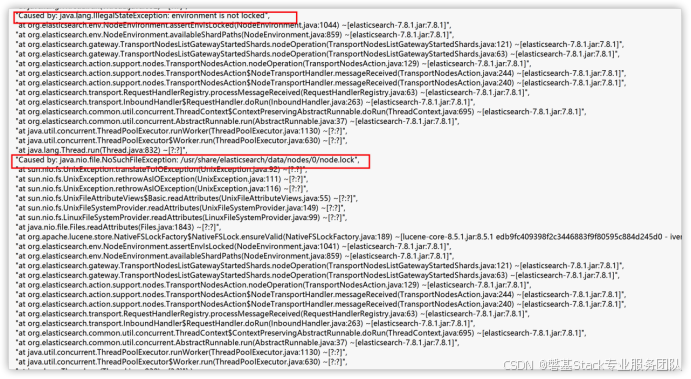
发现日志里提示找不到node.lock文件,在查阅了相关资料后怀疑是目前权限导致的,因为该项目企业套件用的是hostpath方式挂载到宿主机上/data/目录下由于之前宿主机要扩容将此4个文件 拷贝走,但在拷贝回来的时候用的是root用户忘记将属主属组改回,导致目录都是属主属组都是root。造成es访问目录时权限不足,而导致pod无限重启。
三、重启问题解决
将属主属组改回dcdsd.axxxd,重启故障解决了

四、尝试数据恢复
重启问题解决之后,查看ES集群的状态
[min@xxxxxxxxx ~]$ curl -XGET -u cu:123456_ 'http://x.x.x.x:9200/_cluster/health?pretty'
{
"cluster_name" : "cxx-ek",
"status" : "red",
"timed_out" : false,
"number_of_nodes" : 8,
"number_of_data_nodes" : 3,
"active_primary_shards" : 43,
"active_shards" : 53,
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 15,
"delayed_unassigned_shards" : 0,
"number_of_pending_tasks" : 2,
"number_of_in_flight_fetch" : 11,
"task_max_waiting_in_queue_millis" : 1,
"active_shards_percent_as_number" : 77.94117647058823
}
现在集群的状态已经是red不可用的状态
curl -u cu:123456_ ‘http://x.x.x.x:9200/_cat/indices?v’ 查看索引信息
由于master01和master03这两个节点频繁的重启,所以导致整个集群在数据分片过程中,有一个数据的主分片出问题了,所以导致整个集群变成了红色,变成了不可用的状态。
尝试先将red数据拷贝出来,进行修复
Multielasticdump --direction=dump --match='eos-v1-0' --input=http://cu:123456_@x.x.x.x:9200 --ignoreType='settings,template' --output=/home/es_back
只有很少的数据备份了,主要数据备份失败,由于现在集群副本集是零,现在将集群副本集调整为1。
curl -XPUT -u cu:123456_ "x.x.x.x:9200/xxx-v1-1/_settings" -H "Content-Type:application/json" -d '{"number_of_replicas": 1}'

尝试进行重新分片
curl -XPOST -u cu:123456_ 'x.x.x.x:9200/_cluster/reroute' -H 'content-Type:application/json' -d '{
"commands": [
{
"allocate": {
"index": "xxx-v1-1",
"shard": 2,
"node": "xxxx_A"
}
}
]
}'
在进行重新分片后提示失败,
{"error":{"root_cause":[{"type":"named_object_not_found_exception","reason":"[4:21] unknown field [allocate]"}],"type":"x_content_parse_exception","reason":"[4:21] [cluster_reroute] failed to parse field [commands]","caused_by":{"type":"named_object_not_found_exception","reason":"[4:21] unknown field [allocate]"}},"status":400}
经过和二线人员分析得知 这个索引的生成是代码创建的当时创建的时候没有副本集,导致无法进行数据的恢复。
五 、总结
这次问题的根因主要是目录权限的问题导致了 es的pod无限的重启导致分片数据损坏。尽管尝试做了数据恢复 但是由于缺少副本集导致数据无法恢复已经超过50%数据损坏。
事后我们对es进行了重建 并使用脚本进行本地的备份。



















 510
510

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









