







 本文详细介绍了如何配置大数据环境,包括Hadoop、HDFS和YARN。首先,文章讲述了环境准备,如安装Java,创建目录,并调整权限。接着,文章深入到Hadoop的系统配置,涉及配置文件的修改,如hadoop-env.sh、yarn-env.sh、core-site.xml、hdfs-site.xml、mapred-site.xml和yarn-site.xml,以及数据存储路径的设定。此外,还提到了集群的克隆、主机名与IP的修改,以及设置SSH免密登录。
本文详细介绍了如何配置大数据环境,包括Hadoop、HDFS和YARN。首先,文章讲述了环境准备,如安装Java,创建目录,并调整权限。接着,文章深入到Hadoop的系统配置,涉及配置文件的修改,如hadoop-env.sh、yarn-env.sh、core-site.xml、hdfs-site.xml、mapred-site.xml和yarn-site.xml,以及数据存储路径的设定。此外,还提到了集群的克隆、主机名与IP的修改,以及设置SSH免密登录。
一、环境准备
接博客的另外两篇文章,虚拟机和mobaxterm已经安装好了。接下来就是配其他的环境了。
(1)打开mobaxterm并连接上虚拟机。
(2)先在根目录下安装一个软件。

(3)根据官方文档来说,先要安装的是java环境。
(4)所以我先创建了一个文件夹(mkdir soft)用来放两个需要的软件。

(5)选择rpm包是因为基本现在已经规范化了,rpm包安装后是直接可以查到官方文档中它建议的这个路径的,tar包比较麻烦。
官方文档:官方文档链接

(6)直接在soft文件夹安装rpm,安装完我们看一下默认的路径。
(7)安装后查看路径正好是官方推荐的路径。这个路径要记好,后面配java解释器要在这里面找。
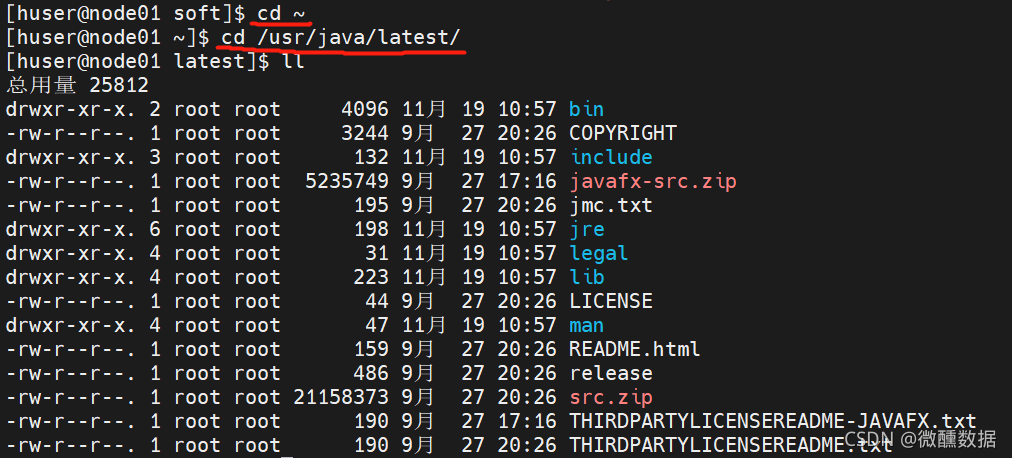
(8)然后我们回到soft文件夹,开始做hadoop的东西,一般都是解压到opt目录下。

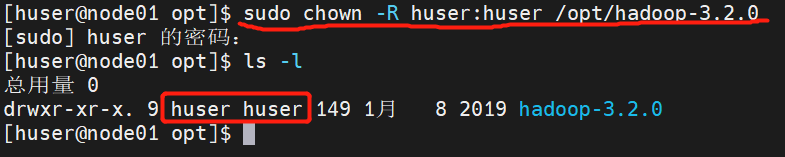
(9)因为刚开始我们创建虚拟机的时候是给自己用户的权限,所以我们查看一下权限发现不是root权限。所以我们现在要做的事情就是把hadoop这个文件夹下的所有目录归到我们的huser用户下。

(10)通过下面的命令查看权限已经修改完毕。
(11)关闭防火墙

(12)关闭selinux,防止以后传输有问题,修改文件通过下面的命令打开,然后把enf
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









