







 本文探讨了如何通过GBK编码规则理解'196227186195'字节序列转化为汉字'你好'的过程,涉及字节提取、编码规则和编译器处理。
本文探讨了如何通过GBK编码规则理解'196227186195'字节序列转化为汉字'你好'的过程,涉及字节提取、编码规则和编译器处理。
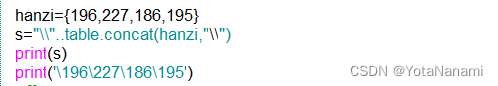
如图所示,我将hanzi这个表进行处理以后得到一个字符串s
运行结果其值为'\196\227\186\195" 然后我想用print将其输出
然而print(s)和print('\196\227\186\195')所得到的结果并不一样,请问是什么原因导致的? 有没有什么办法使得print(s)直接就可以输出汉字'你好'?
-------------------------------------------------------------上面的是原本的问题------------------------------------
当时想的是拼接字符串 拼接出\196\227\186\195 然后print出来就行了
后来发现根本不对
concat是把这个table作为字符提取出来再拼接的,而我们需要把元素提取按字节出来
以196为例 如果按字符提取 是3字符‘1’ '9' '6'
而通过string.char(table.unpack(hanzi))来进行处理 则是把196作为一个字节 也就是‘11000100'
提取出来的
然后再通过sting.char 按位来拼接成字符串 hanzi={196,227,186,195}拼接成字符串后也就是
11000100 11100011 10111010 11000011
而为什么在编译器编译的时候 会把相邻两个字节编译为汉字 而不是单独编译一个字节呢?这就设计到GBK的编码规则了
GBK的编码规则,有前导字符,如果看到第一个字符大于127,就知道这是一个汉字的第一个字节,然后就接着看下一个,并结合起来,日语的shift-js也是这样编码的
所以说 编译器会把11000100 11100011 (也就是0xC0 0XE3)结合起来 编译成汉字'你'进行输出
(当然只当做字节来看的话数据其实是没有区分的,看编译器本身)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









