




spark开发环境搭建
提示:spark官方系列教程
前言
本篇内容主要按照spark官方教程,搭建Java版的spark开发教程,该例子主要是为了统计含有“a”的行数,和含有“b”的行数。
提示:以下是本篇文章正文内容,下面案例可供参考
一、IDEA搭建Maven工程
IDEA搭建maven工程,在pom文件中导入依赖。
<dependencies>
<dependency> <!-- Spark dependency -->
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>3.1.1</version>
</dependency>
</dependencies>
注意:在spark官方文档中还包含provided,该字段的意思是:provided表明该包只在编译和测试的时候用
二、新建 SimpleApp类
1.复制代码
/* SimpleApp.java */
import org.apache.spark.sql.SparkSession;
import org.apache.spark.sql.Dataset;
public class SimpleApp {
public static void main(String[] args) {
String logFile = "YOUR_SPARK_HOME/README.md"; // Should be some file on your system
SparkSession spark = SparkSession.builder().appName("Simple Application").getOrCreate();
Dataset<String> logData = spark.read().textFile(logFile).cache();
long numAs = logData.filter(s -> s.contains("a")).count();
long numBs = logData.filter(s -> s.contains("b")).count();
System.out.println("Lines with a: " + numAs + ", lines with b: " + numBs);
spark.stop();
}
}
上述代码在使用Java 8 时,可能需要在Lambda表达式处进行,对参数s进行强制类型转换。同时需要修改logFile的值,该值是文件的地址。
long numAs = logData.filter((FilterFunction<String>) s -> s.contains("a")).count();
long numBs = logData.filter((FilterFunction<String>) s -> s.contains("b")).count();
2.设置JVM运行参数
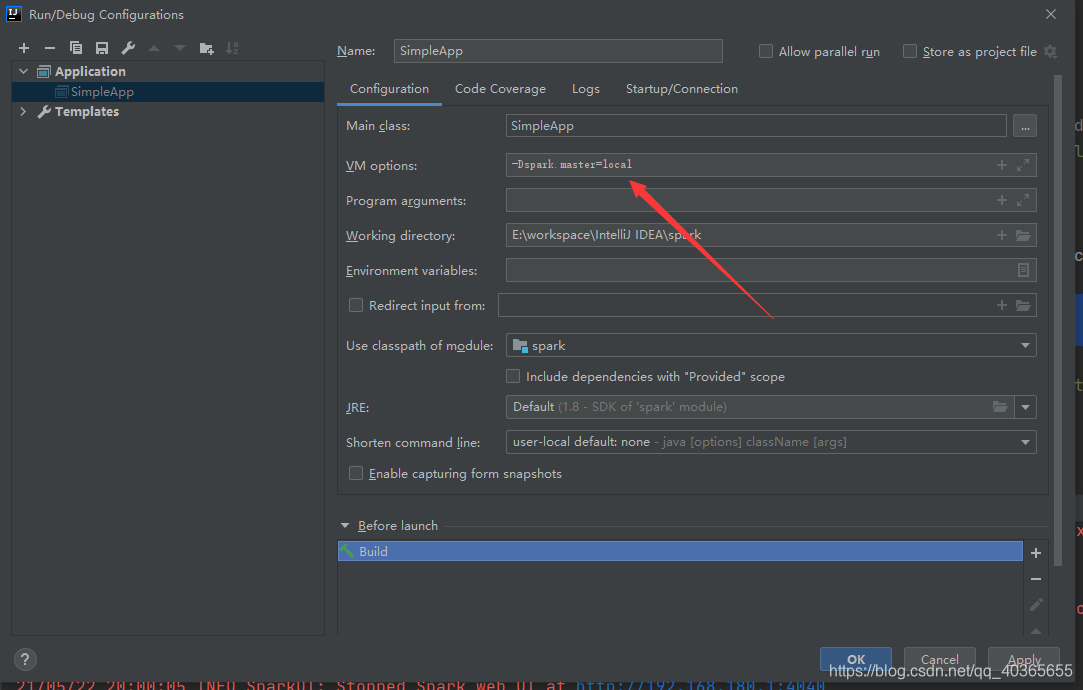
-Dspark.master=local
设置该参数的目的是为了指明该程序是本机运行。否则将会抛出如下异常
org.apache.spark.SparkException: A master URL must be set in your configuration
at org.apache.spark.SparkContext.<init>(SparkContext.scala:394)
at org.apache.spark.SparkContext$.getOrCreate(SparkContext.scala:2678)
at org.apache.spark.sql.SparkSession$Builder.$anonfun$getOrCreate$2(SparkSession.scala:942)
at scala.Option.getOrElse(Option.scala:189)
at org.apache.spark.sql.SparkSession$Builder.getOrCreate(SparkSession.scala:936)
at SimpleApp.main(SimpleApp.java:8)
21/05/22 20:51:37 INFO SparkContext: Successfully stopped SparkContext
Exception in thread "main" org.apache.spark.SparkException: A master URL must be set in your configuration
at org.apache.spark.SparkContext.<init>(SparkContext.scala:394)
at org.apache.spark.SparkContext$.getOrCreate(SparkContext.scala:2678)
at org.apache.spark.sql.SparkSession$Builder.$anonfun$getOrCreate$2(SparkSession.scala:942)
at scala.Option.getOrElse(Option.scala:189)
at org.apache.spark.sql.SparkSession$Builder.getOrCreate(SparkSession.scala:936)
at SimpleApp.main(SimpleApp.java:8)
总结
上述操作为搭建spark开发环境教程,这里之前已经安装了Hadoop开发环境,如果没有安装Hadoop开发环境的需要安装winutils.exe ,安装包在github中有,安装教程自行搜索。

















 463
463

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









