



目录
数据结构
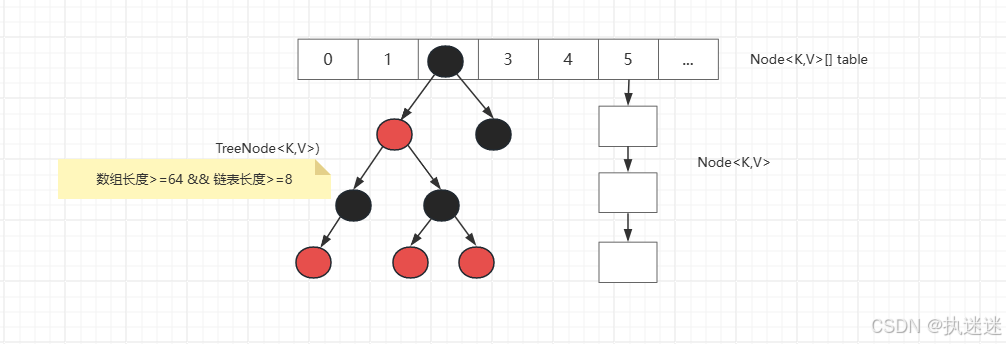
主流程
putVal
java.util.HashMap#putVal
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
// 判断table数组是否为null或者数组长度是否为0
if ((tab = table) == null || (n = tab.length) == 0)
// 调用resize进行初始化,长度默认16
n = (tab = resize()).length;
// 通过寻址找到数组的索引位里的元素是否为null(lenth -1 和hash进行位运算)
if ((p = tab[i = (n - 1) & hash]) == null)
// 创建Node放到数组对应索引位中
tab[i] = newNode(hash, key, value, null);
else { // 非null,也就是有数据(会有多种情况)
Node<K,V> e; K k;
// 当前数组索引位的元素hash或者key是否和传入的一致
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
// 将当前数组索引位里的元素p赋值给临时元素e
e = p;
else if (p instanceof TreeNode) // 如果当前数组索引位里的元素已经树化了(TreeNode),调用putTreeVal
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
// 走到这代表是链表的情况了
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
// 当前数组索引位里的元素的下一个节点为null(当前索引位已经处于尾部了),创建Node放到尾部
p.next = newNode(hash, key, value, null);
// 链表长度是否>=8,如果是则要进行树化(这里的意思也就是循环链表,如果链表的最后一个元素的下一个节点为null,那么在创建一个新Node后会去需要判断是否需要将链表转化成红黑树)
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
// 在遍历链表的过程中,判断数组索引位的元素hash或者key是否和传入的一致
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
// 将数组索引位里的元素p赋值给临时元素e
p = e;
}
}
// 临时元素e不为null,用传入的值进行覆盖
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
// 如果插入元素后map的大小超过阈值,则调用resize方法进行扩容
if (++size > threshold)
resize();
// LinkedHashMap和HashMap都不走任何逻辑
afterNodeInsertion(evict);
return null;
}remove
java.util.HashMap#removeNode
final Node<K,V> removeNode(int hash, Object key, Object value,
boolean matchValue, boolean movable) {
// tab为数组,p为通过位运算找到数组中的节点元素,n为tab的长度,index为索引位
Node<K,V>[] tab; Node<K,V> p; int n, index;
// 如果数组tab数组不为null 并且 数组的长度 > 0 并且根据key的hash和(length-1)进行位运算后在数组中的索引位有数据
if ((tab = table) != null && (n = tab.length) > 0 &&
(p = tab[index = (n - 1) & hash]) != null) {
Node<K,V> node = null, e; K k; V v;
// 如果数组索引位元素p的hash值和删除key的hash值相等并且key相等,用临时变量node保存元素p
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
node = p;
else if ((e = p.next) != null) { // 走到这说明是链表或者红黑树
// 红黑树
if (p instanceof TreeNode)
// 通过红黑树找到对应的节点
node = ((TreeNode<K,V>)p).getTreeNode(hash, key);
else { // 链表
do { // 遍历去获取和删除key的hash值相等并且key相等的节点
if (e.hash == hash &&
((k = e.key) == key ||
(key != null && key.equals(k)))) {
node = e;
break;
}
p = e;
} while ((e = e.next) != null);
}
}
// matchValue为true只比较值,这里传进来的是false,所以后面永远判断都是成立的
// 能找到对应的节点node
if (node != null && (!matchValue || (v = node.value) == value ||
(value != null && value.equals(v)))) {
if (node instanceof TreeNode)
// 红黑树调用红黑树的remove
((TreeNode<K,V>)node).removeTreeNode(this, tab, movable);
else if (node == p)
// 匹配到的节点是数组中的头结点,将头节点覆盖成下一个节点
tab[index] = node.next;
else
// 链表的移除
p.next = node.next;
++modCount;
--size;
afterNodeRemoval(node);
return node;
}
}
return null;
}resize
java.util.HashMap#resize
final Node<K,V>[] resize() {
// 原数组
Node<K,V>[] oldTab = table;
// 原数组长度
int oldCap = (oldTab == null) ? 0 : oldTab.length;
// 原数组扩容阈值(也就是此次扩容的阈值)
int oldThr = threshold;
// 新数组长度、新数组的扩容阈值
int newCap, newThr = 0;
// 原数组的长度是否大于0,大于0说明已经初始化过了
if (oldCap > 0) {
// 判断原数组长度是否大于等于数组最大值(1<<30),大于等于的话就不能扩容了
if (oldCap >= MAXIMUM_CAPACITY) {
// 把扩容阈值设置的比MAXIMUM_CAPACITY还大,说明不能扩容了
threshold = Integer.MAX_VALUE;
return oldTab;
}
// 将原数组长度x2后赋值给新数组的长度
// 如果新数组长度小于数组最大值并且原数组长度大于等于数组的初始化默认值(16)
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
// 将原数组扩容阈值x2赋值给新数组扩容阈值
newThr = oldThr << 1; // double threshold
}
// 走到这说明原数组还未初始化,但是是通过有参构造方法构造的HashMap
// public HashMap(int initialCapacity, float loadFactor) {}
// public HashMap(int initialCapacity) {}
// 从以上两个构造方法可以看出通过构造参数可以实现对扩容阈值threshold的设置
else if (oldThr > 0) // initial capacity was placed in threshold
// 将原数组扩容阈值赋值给新数组长度
// 上面两个构造方法里面会通过tableSizeFor方法去计算扩容阈值,计算出来的值一定是2的n次方(假设说构造参数传的12,那么计算出来的是16)
newCap = oldThr;
else {
// 走到这说明原数组还未初始化,但是是通过无参构造方法构造的HashMap
// public HashMap() {}
// 这里就是设置下新数组长度为默认值(16)
newCap = DEFAULT_INITIAL_CAPACITY;
// 新数组扩容阈值为默认扩容因子* 数组默认长度(0.75 * 16)
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
// 执行了else if (oldThr > 0)里面的逻辑,这里会设置新数组扩容阈值
if (newThr == 0) {
// 新数组长度 * 扩容因子
float ft = (float)newCap * loadFactor;
// 校验新数组长度和新数组扩容阈值是否超过最大值
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
// 创建新数组(这里有可能是原数组初始化过了进行扩容后的数组,也有可能是初始化的数组)
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
// 原数组非null(也就是原数组已经存在了)
if (oldTab != null) {
// 遍历数组
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
// 当前索引位只有一个元素,通过当前元素的hash和新数组长度-1进行位运算,放到新数组的相应位置中
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
// 如果该元素是红黑树节点,调用split方法
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // 走到这就说明是链表了
// loHead、loTail为低位链表的首个元素和末尾元素(索引位和原数组相同)
// hiHead、hiTail为高位链表的首个元素和末尾元素(索引位为原数组索引位+ 原数组长度)
// 这里设计巧妙的原因是设置了低位链表和高位链表,因为节点的hash和新数组长度-1进行位运算后,可能放的位置有两种情况,一种是原来的索引位,另一种是原来的索引位 + 原数组长度
// 举例:原数组长度为16,新数组长度为32,原数组15索引位的链表元素可能放在新数组的索引位为15或者31
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do { // 遍历链表
next = e.next;
// 将节点的hash和原数组长度进行位运算,等于0放到低位链表种,否则放到高位链表
if ((e.hash & oldCap) == 0) {
// 位运算后等于0,设置低位链表的头节点和末尾节点
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
// 位运算后不等于0,设置高位链表的头节点和末尾节点
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
// 说明低位链表有元素,需要将低位链表的末尾元素的next指向null
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
// 说明高位链表有元素,需要将高位链表的末尾元素的next指向null
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}Q&A
Q:为什么需要设置loHead、loTail(低位链表)/hiHead、hiTail(高位链表)?
A:假设原数组长度为16,新数组长度为32,那么在原数组的15索引位(是个链表)里的数据的hash值只会有两种情况:
1. ...11111
2. ...01111
后4位为1的原因:在通过位运算时,需要hash&length-1,此时的length-1为15,15的二进制为01111,那么如果数据是放在15的索引位,那么需要后4位为1才满足
那么如果需要计算原数组15索引位里各个元素在新数组的位置情况,就需要通过各元素的hash&length-1(31的二进制为11111),也就是说通过位运算出来的索引位会有两种:
1. ...11111(31)
2. ...01111(15)
所以需要低位链表和高位链表。
Q:resize扩容方法里if ((e.hash & oldCap) == 0)这个判断为什么就能知道该元素放在低位或者高位链中
A:假设原数组长度为16,新数组长度为32,正常我们计算元素在新数组的索引位逻辑为hash&length-1(31的二进制为11111),由第一个问题我们可以看出,这个方法其实就是在比较第5位为0还是为1,因此通过oldCap(16的二进制10000)去进行位运算就可以知道是放在低位还是高位链中。
结语
本篇文章只是介绍了HashMap的主流程,内部还有红黑树的处理较为复杂,后续会有专门一篇文章介绍

















 1126
1126

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









