







C++程序运行的环境(内存布局)
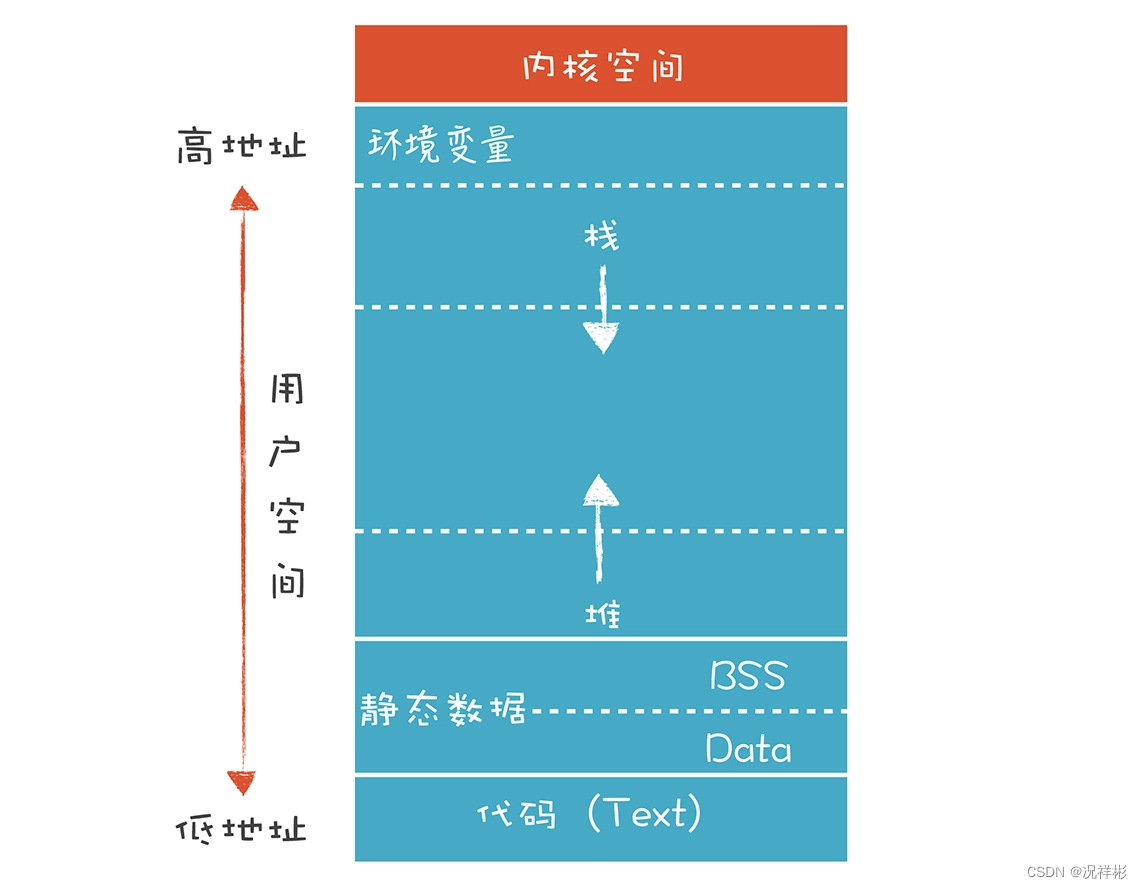
堆区(heap area)
存放new出来的对象。一般由程序员分配和释放,若程序员不释放,程序运行结束时由操作系统回收。
栈区(stack area)
利用栈实现函数的调用,每个函数对应一个栈桢,调用函数时栈桢入栈,调用结束时栈桢出栈。
栈桢包含以下内容:
-
参数和局部变量
-
函数的返回地址
也就是函数执行完成后从哪里开始继续执行后面的代码 -
一些需要保存的寄存器
例如 ebp、ebx、esi、edi 等。之所以要保存寄存器的值,是为了在函数退出时能够恢复到函数调用之前的场景,继续执行上层函数。
静态数据区:

代码区:
存放编译完成以后的机器码
这个内存区域是只读的,不会再修改,但也不绝对。现代语言的运行时已经越来越动态化,除了保存机器码,还可以存放中间代码,并且还可以在运行时把中间代码编译成机器码,写入代码区。
堆vs栈
| 堆 | 栈 | |
|---|---|---|
| 申请方式 | 手动 | 自动 |
| 碎片问题 | new/delete会造成碎片问题 | 栈是一个先进后出的队列,进出一一对应,不会产生碎片 |
| 分配方式 | 堆都是动态分配(没有静态分配的堆) | 栈有静态分配和动态分配,静态分配由编译器完成(如局部变量分配),动态分配由alloca函数分配,但栈的动态分配的资源也是由编译器进行释放,无需程序员动手实现 |
| 生长方向 | 堆向高地址方向增长。 | 栈向低地址方向增长 |
| 缓存方式 | 栈使用的是一级缓存, 它们通常都是被调用时处于存储空间中,调用完毕立即释放; | 堆则是存放在二级缓存中,速度要慢些。 |
| 内存管理机制 | 系统有一个记录空闲内存地址的链表,当系统收到程序申请时,遍历该链表,寻找第一个空间大于申请空间的堆结点,将该结点空间分配给程序 | 只要栈的剩余空间大于所申请空间,系统为程序提供内存,否则报异常提示栈溢出 |
举例说明
#include <stdio.h>
char *str1 = "c.biancheng.net"; //字符串在常量区。不会随着 func() 的运行结束而销毁,str1在全局数据区
int n; //全局数据区
char* func(){
char *str = "C语言"; //字符串在常量区,str在栈区
return str;
}
int main(){
int a; //栈区
char *str2 = "01234"; //字符串在常量区,str2在栈区
char *pstr = func(); //栈区
int b; //栈区
}
内存泄露
内存对齐
什么是内存对齐?
现代计算机中内存空间都是按照字节划分的,从理论上讲似乎对任何类型的变量的访问可以从任何地址开始,但是实际的计算机系统对基本类型数据在内存中存放的位置有限制,它们会要求这些数据的首地址的值是某个数k(通常它为4或8)的倍数,这就是所谓的内存对齐。
为什么要进行内存对齐?——提高数据读取效率
比如当我们保证所有double类型的数据的地址对齐成8的倍数时,我们就可以用一次内存操作来读写值,否则可能需要两次内存访问,因为对象可能放在两个8字节的内存块中
对齐原则:任何K字节的基本对象的地址必须是K的倍数
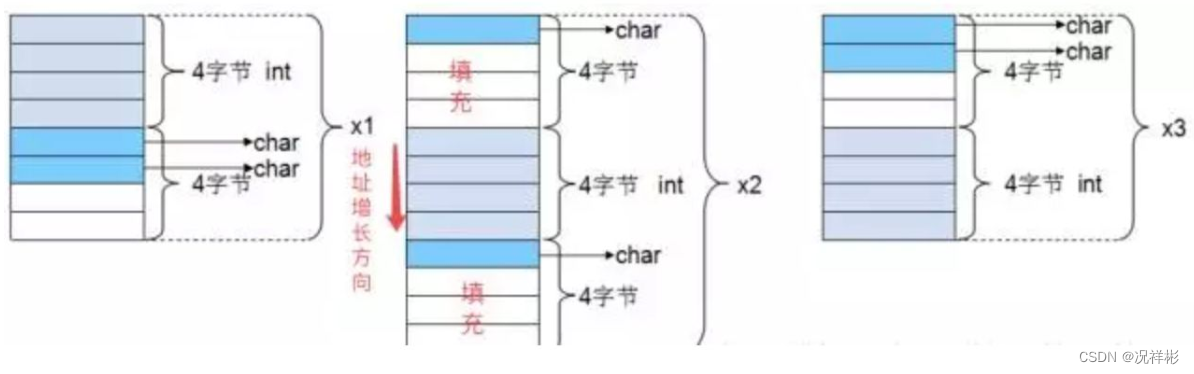
具体如何对齐举例一:
//32位系统
#include<stdio.h>
struct
{
int i;
char c1;
char c2;
}x1;
struct{
char c1;
int i;
char c2;
}x2;
struct{
char c1;
char c2;
int i;
}x3;
int main()
{
printf("%d\n",sizeof(x1)); // 输出8
printf("%d\n",sizeof(x2)); // 输出12
printf("%d\n",sizeof(x3)); // 输出8
return 0;
}
举例二:
class A{
int a //4
short b //4
int c //4
short d //4
}
A的实例占16字节
怎么优化?——调整字段的存放顺序
class A{
int a //4
int c //4
short b //2
short d //2
}
现在一共占12字节
现在B继承A
class B : A{
short e
}
B类的实例占多少字节?
——20字节
编译器为啥不把e和d挨着放呢?
因为如果放一起的话,A类对象仍然认为d独占4字节,所以会把e也取出来,造成错误。

















 6761
6761

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









