







文章目录
堆核心特性总结
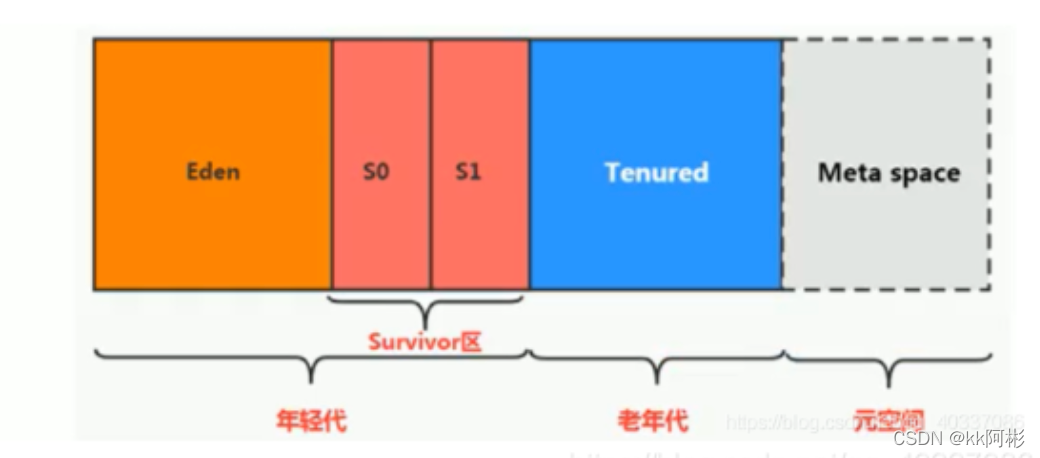
1、堆内存细分
堆空间分为:新生区+养老区+元空间
新生区又被划分为Eden区、Survivor1区和Survivor2区
默认大小占比如下:
新生代:老年代 - > 1 : 2
Eden:From:to -> 8:1:1
所有的Java对象都是在Eden区产生的
并且绝大部分的Java对象在新生代就销毁了,不会进入老年代
2 、堆是线程共享的,多个线程共享同一堆空间。
但是,堆空间也并非全部都是共享的,因为在堆中还可以划分线程私有的缓冲区(Thread Local Allocation Buffer,TLAB)
3、《Java虚拟机规范》中对Java堆的描述是:所有的对象实例以及数组都应当在运行时分配在堆上,注意这里是应当不是一定,所以实际是:大部分对象分配在堆上。一小部分没有发送栈上逃逸的会在栈上分配
这点和c++不一样,c++是用new创建的对象放堆上,不用new的放栈上
4、默认生命周期为15,超过15进入老年代
为什么是15呢?
因为标识分代年龄的空间大小是4bit,最多记录到15.
5、堆内存大小
“-Xms"用于表示堆区的起始内存
“-Xmx"则用于表示堆区的最大内存
通常会将起始内存和最大内存配置成相同的值,一开始就把最大的给你,别老是找我要了
一旦堆区中的内存大小超过“-xmx"所指定的最大内存时,将会抛出OOM异常。
6、垃圾回收的频率
频繁在新生区收集,很少在老年代收集,几乎不再永久代|元空间进行收集
为什么要把Java堆分代?
为了优化GC性能
即:使「stop the world」持续的时间尽可能短,以及提高并发式GC所能应付的内存分配速率
-
如果没有分代,那所有的对象都在一块,GC的时候就会对堆的所有区域进行扫描
-
如果分代的话,把新创建的对象统一放到
Eden区,当GC的时候先扫描Eden+from区就可以回收大部分的对象,大大节省了扫描时间,减少了STW的时间。
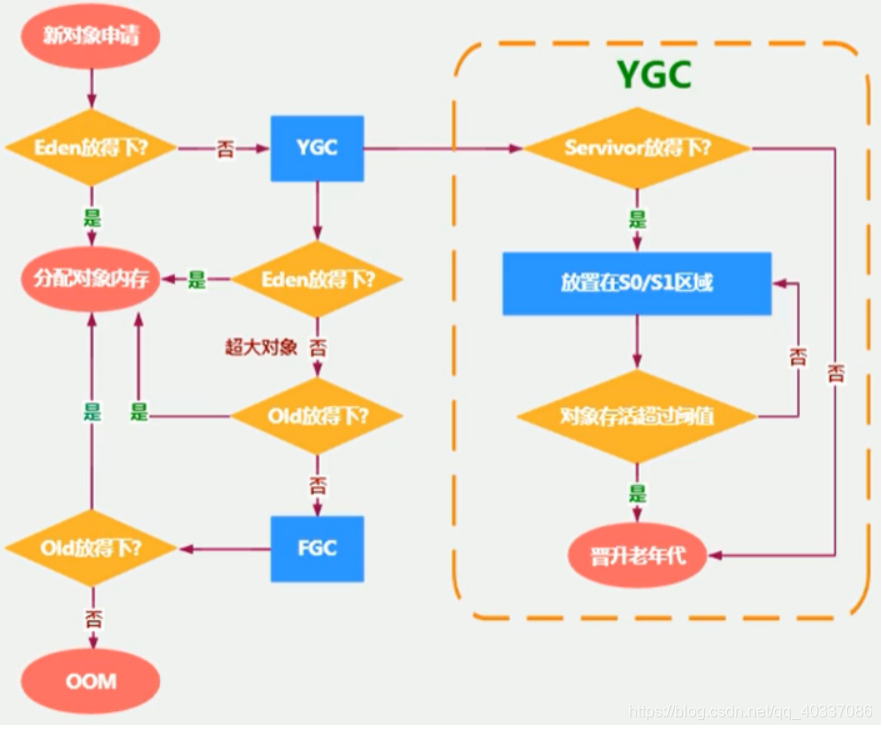
Java对象在堆内存中的分配回收
为新对象分配内存是一件非常严谨和复杂的任务,JVM的设计者们不仅需要考虑内存如何分配、在哪里分配等问题,并且由于内存分配算法与内存回收算法密切相关,所以还需要考虑GC执行完内存回收后是否会在内存空间中产生内存碎片。
内存的分配回收过程如下:
-
new的对象先放伊甸园区。此区有大小限制。
-
当Eden的空间填满时,如果程序还在继续创建对象,那么GC将对Eden进行垃圾回收
(MinorGC),将Eden中的不再被其他对象所引用的对象进行回收销毁。释放空间之后再加载新的对象放到Eden -
然后将伊甸园中的剩余对象移动到
幸存者0区。 -
如果再次触发垃圾回收,
Eden和s0幸存下来的就会转移到幸存者1区,再次GC时幸存下来的转移到幸存者0区,依次往复,每转移一次,对象的年龄+1,直到年龄到16时(次数可调整),幸存下来的对象就会转移到老年代。 -
在养老区,相对悠闲。当养老区内存不足时,再次触发GC,此时是
Major GC,进行养老区的内存清理 -
若养老区执行了Major GC之后,发现依然无法进行对象的保存,就会产生
OOM异常。
幸存区满了后怎么办?
在Eden区满了的时候,才会触发MinorGC,而幸存者区满了后,不会触发MinorGC操作。
此时对象不用等到年龄限制而是直接晋升老年代。
对象分配完整流程图
Minor GC,Major GC、Full GC
Minor GC:新生代的GC
当年轻代的Eden区满时,就会触发MinorGC,每次Minor GC会清理年轻代的内存。
Minor GC非常频繁,一般回收速度也比较快
Minor GC会引发STW,暂停其它用户的线程,等垃圾回收结束,用户线程才恢复运行
Major GC:老年代的GC
在老年代空间不足时,会先尝试触发MinorGc。如果之后空间还不足,则触发Major GC,如果内存还不足,就报OOM了
Major GC的速度一般会比Minor Gc慢10倍以上,STW的时间也更长
Full GC:收集整个Java堆和方法区
STW的时间最长,要尽量避免Full GC
内存分配原则
针对不同年龄段的对象分配原则如下所示
-
优先分配到Eden
-
大对象直接分配到老年代
-
长期存活的对象分配到老年代
-
动态对象年龄判断
如果survivor区中年龄同为x的对象大小的总和>Survivor空间的一半,那么年龄>=x的对象可以直接进入老年代,无须等到默认的16
TLAB(Thread Local Allocation Buffer)
什么是TLAB?
JVM为每个线程分配一个私有缓存区域TLAB,
因为TLAB分配给某个线程所独占,所以有了TLAB后,堆空间不再是完全共享的了。
TLAB图示:
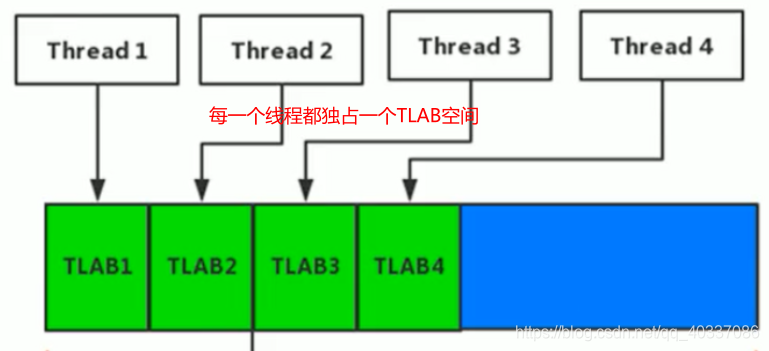
为什么要为每个线程单独分配一个TLAB缓冲区?
由于堆区是线程共享区域,任何线程都可以访问到堆区中的共享数据,为避免多个线程同时操作同一地址带来的安全问题,需要使用加锁等机制,
加锁必然影响内存分配的性能,为了提升性能,所以引入TLAB来避免一系列的非线程安全问题
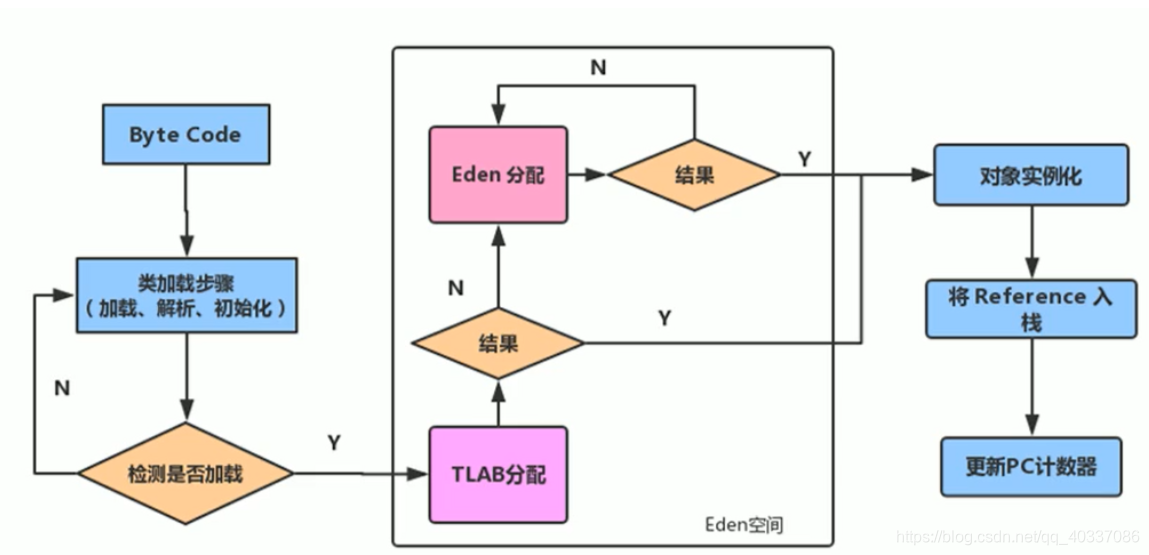
目前,JVM将TLAB作为内存分配的首选,但是TLAB空间太小了(仅占有整个Eden空间的1%),不是所有的对象实例都能够在TLAB中成功分配内存,一旦对象在TLAB空间分配内存失败时,JVM就会尝试着通过使用加锁机制确保数据操作的原子性,从而直接在Eden空间中分配内存。
TLAB分配过程:
即时编译器JIT的对象分配优化
JIT优化技术比较出名的有两种:方法内联和逃逸分析
方法内联
所谓方法内联就是把「目标方法」的代码复制到「调用的方法」中,避免发生真实的方法调用
因为每次方法调用都会生成栈帧(压栈出栈记录方法调用位置等等)会带来一定的性能损耗,所以「方法内联」的优化可以提高一定的性能
在JVM中也有相关的参数给予我们指定(-XX:MaxFreqInlineSize、-XX:MaxInlineSize)
逃逸分析
逃逸分析是指Hotspot编译器分析一个对象的引用的使用范围
如果对象没有被方法外调用,则认为没有发生逃逸
如果被外部方法所引用,则发生了逃逸
未发生逃逸时可以进行以下三个优化
- 栈上分配
- 同步省略
- 标量替换
栈上分配
如果一个对象并没有逃逸出方法的话,那么就可能被优化成在栈上分配
好处是无须进行垃圾回收了
同步省略(锁消除)
在动态编译同步块的时候,JIT编译器会判断同步块所使用的锁对象是否只能够被一个线程访问,如果是只能被一个线程访问,那么JIT编译器在编译这个同步块的时候就会取消对这部分代码的同步。这样就能大大提高并发性和性能。
这个取消同步的过程就叫同步省略,也叫锁消除。
例如下面的代码
public void f() {
Object hellis = new Object();
synchronized(hellis) {
System.out.println(hellis);
}
}
代码中对hellis这个对象加锁,但是hellis对象的生命周期只在f()方法中,并不会被其他线程所访问到,所以在JIT编译阶段就会被优化掉,优化成:
public void f() {
Object hellis = new Object();
System.out.println(hellis);
}
标量替换
先看什么是标量和聚合量?
标量是指一个无法再分解成更小的数据的数据。Java中的基本数据类型就是标量。
相对的,那些还可以分解的数据叫做聚合量,Java中的对象就是聚合量,因为他可以分解成其他聚合量和标量。
再看什么是标量替换?
如果经过逃逸分析,发现一个对象不会被外界访问的话,那么经过JIT优化,就会把这个对象拆解成其包含的成员变量来代替。这个过程就是标量替换。
举例理解
public static void main(String args[]) {
alloc();
}
class Point {
private int x;
private int y;
}
private static void alloc() {
Point point = new Point(1,2);
System.out.println("point.x" + point.x + ";point.y" + point.y);
}
以上代码,经过标量替换后,就会变成
private static void alloc() {
int x = 1;
int y = 2;
System.out.println("point.x = " + x + "; point.y=" + y);
}
可以看到,Point这个聚合量经过逃逸分析后,发现他并没有逃逸,就被替换成两个聚合量了。
那么标量替换有什么好处呢?
大大减少堆内存的占用。因为一旦不需要创建对象了,那么就不再需要分配堆内存了。
小结
堆用来存放new的对象,线程共享,不过为了优化分配性能,设计了TLAB,TLAB是线程私有的。
为了优化GC性能,将堆进行分代,在逻辑上分为年轻代,老年代,永久代|方法区|元空间。
年轻代又分为Eden、from、to三个区域
年轻代:老年代=1:2
Eden:from:to=8:1:1
对象的创建一开始都放在Eden中,Eden满了会触发Miner GC。年龄到了16还存活的对象就会放入老年代。
老年代放不下了就会触发Major GC
Full GC会进行整堆收集
发生频率:Miner GC > Major GC > Full GC
进行逃逸分析之后,如果未逃逸,则可以进行
栈上分配
同步消除
标量替换
这三种方式优化性能
自己的一点思考
Minor GC 是「年轻代」GC,从GC Roots出发,会扫描到「老年代」的对象,那就相当于全堆扫描了,为什么说Minor GC 只扫描年轻代呢?
其实是这样的:
HotSpot 虚拟机是要求整个GC堆在连续的地址空间上的
所以会有一条分界线(一侧是老年代,另一侧是年轻代),所以可以通过「地址」就可以判断对象在哪个分代上
当做Minor GC的时候,从GC Roots出发,如果发现「老年代」的对象,那就不往下走了(Minor GC对老年代的区域毫无兴趣)

















 896
896

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









