



 本文介绍了图计算的重要性,特别是在大数据分析中。通过Apache Spark的GraphX库,展示了如何创建和操作图数据结构。内容包括图的基本概念,如顶点和边,以及如何加载和查询图数据。此外,还提供了两个实例,分别构建了用户合作关系和社交网络关系的图,并进行了特定条件的查询,如找出年龄大于30岁的用户和打call次数超过5次的真爱用户。
本文介绍了图计算的重要性,特别是在大数据分析中。通过Apache Spark的GraphX库,展示了如何创建和操作图数据结构。内容包括图的基本概念,如顶点和边,以及如何加载和查询图数据。此外,还提供了两个实例,分别构建了用户合作关系和社交网络关系的图,并进行了特定条件的查询,如找出年龄大于30岁的用户和打call次数超过5次的真爱用户。
为什么需要图计算
许多大数据以大规模图或网络的形式呈现
许多非图结构的大数据,常会被转换为图模型进行分析
图数据结构很好地表达了数据之间的关联性
图(Graph)的基本概念
图是由顶点集合(Vertex)及顶点间的关系集合(edge)组成地一种网状数据结构
通常表示为二元组:
//导入 spark Graph包
import org.apache.spark.graphx._
//创建 vertices 顶点rdd
val vertices = sc.makeRDD(Seq((1L,1),(2L,2),(3L,3)))
//创建 edges 边rdd
val edges = sc.makeRDD(Seq(Edge(1L,2L,1),Edge(2L,3L,2)))
//创建graph对象
val graph = Graph(vertices,edges)
//获取graph图对象的vertices信息
graph.vertices.collect
Array[(org.apache.spark.graphx.VertexId, Int)] = Array((1,1), (3,3), (2,2))
//获取graph图对象的edges信息
graph.edges.collect
Array[org.apache.spark.graphx.Edge[Int]] = Array(Edge(1,2,1), Edge(2,3,2))
//通过文件加载follower.txt
内容为:
2 3
3 4
1 4
2 4
val graphLoad = GraphLoader.edgeListFile(sc,"file:///opt/kb09file/follower.txt")
graphLoad: org.apache.spark.graphx.Graph[Int,Int] = org.apache.spark.graphx.impl.GraphImpl@728b0dc0
graphLoad.vertices.collect
res7: Array[(org.apache.spark.graphx.VertexId, Int)] = Array((4,1), (1,1), (3,1), (2,1))
graphLoad.edges.collect
res8: Array[org.apache.spark.graphx.Edge[Int]] = Array(Edge(1,4,1), Edge(2,3,1), Edge(2,4,1), Edge(3,4,1))
graphLoad.triplets.collect
res9: Array[org.apache.spark.graphx.EdgeTriplet[Int,Int]] = Array(((1,1),(4,1),1), ((2,1),(3,1),1), ((2,1),(4,1),1), ((3,1),(4,1),1))
//实例1
//构建用户合作关系属性图
顶点属性:
用户名、职业
边属性:
合作关系
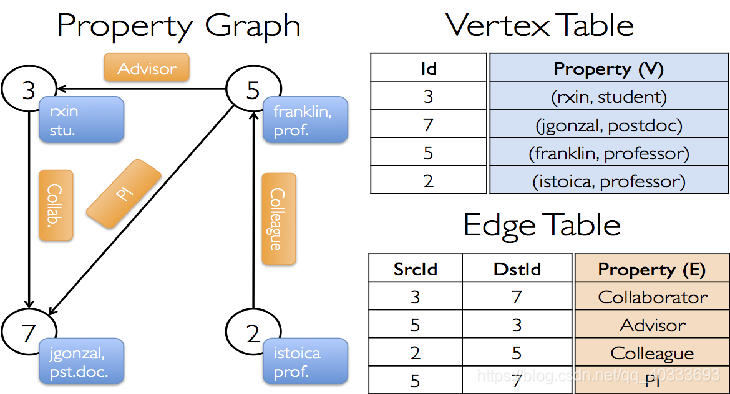
//顶点属性
val users = sc.parallelize(Array((3L,("rxin","student")),(7L,("jgnorzal","postdoc")),(5L,("franklin","professor")),(2L,("istorica","professor"))))
//边属性
val relationship = sc.parallelize(Array(Edge(3L,7L,"Collaborator"),Edge(5L,3L,"Advisor"),Edge(2L,5L,"Colleague"),Edge(5L,7L,"PI")))
//构建图
val graphUser = Graph(users,relationship)

//实例2
构建用户社交网络关系
顶点:用户名、年龄
边:打call次数
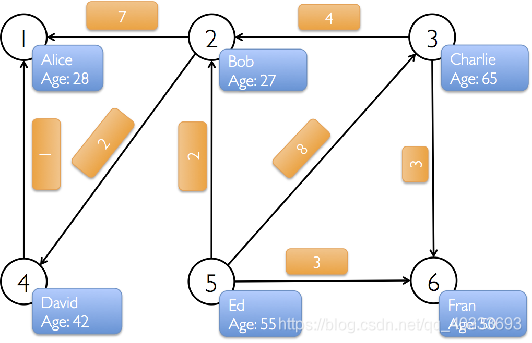

//顶点
val social = sc.parallelize(Array((1L,("Alice",28)),(2L,("Bob",27)),(3L,("Charlie",65)),(4L,("David",52)),(5L,("Ed",55)),(6L,("Fran",50))))
//边
val callRDD = sc.makeRDD(Array(Edge(2L,1L,7),Edge(3L,2L,4),Edge(3L,6L,3),Edge(2L,4L,2),Edge(4L,1L,1),Edge(5L,2L,2),Edge(5L,3L,8),Edge(5L,6L,3)))
//构建图
val userCallGraph = Graph(social,callRDD)
//找出大于30岁的用户
userCallGraph.vertices.filter{ case (id,(name,age)) => age > 30}.collect.foreach(println)
userCallGraph.vertices.filter(v => v._2._2 > 30).collect.foreach(println)
userCallGraph.vertices.filter(v => v._2._2 > 30).collect.foreach(x => println("name:" + x._2._1 + "\t" + "age:" + x._2._2))
//假设打call次数超过5次,表示真爱。请找出他们
userCallGraph.triplets.collect.foreach(x => println(x.dstAttr)) //尾节点属性
userCallGraph.triplets.collect.foreach(x => println(x.srcAttr)) //初始节点属性
userCallGraph.triplets.collect.foreach(x => println(x.attr)) //边属性
userCallGraph.triplets.filter(x => x.attr > 5).collect.foreach(x => println(x.srcAttr._1 + " like " + x.dstAttr._1 + ",stage is " x.attr)) //打call次数大于5的
userCallGraph.numEdges //边数
userCallGraph.numVertices //节点数
userCallGraph.outDegrees.collect //所有节点的出度
userCallGraph.inDegrees.collect //所有节点入度
userCallGraph.degrees.collect //所有节点的出入度
userCallGraph.mapVertices{case (verid,(name,age)) => (verid,name)}

















 2924
2924

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









