







 本文介绍如何使用Caffe实现GoogleNet模型进行图像识别。通过部署文件描述模型结构,理解Inception模块中不同大小卷积核的作用。同时提供识别图片的准备步骤,包括获取synset_words.txt标签文件,并利用Python接口调用进行识别。
本文介绍如何使用Caffe实现GoogleNet模型进行图像识别。通过部署文件描述模型结构,理解Inception模块中不同大小卷积核的作用。同时提供识别图片的准备步骤,包括获取synset_words.txt标签文件,并利用Python接口调用进行识别。
1.到caffe的github上去下载训练好的GoogleNet模型
训练好的模型意思的一些参数比如权值和观测值都已经被训练好,都存在这个模型中。
注:deploy文件是模型结构的描述文件。我们用之前第四篇博客模型可视化的方法用draw_net.py将该模型画出来:

网络比较长,层数多,宽度宽,我这里只上传一个小截图,就不把全部图片上传过来,大家有兴趣可以自己看看网络结构图。
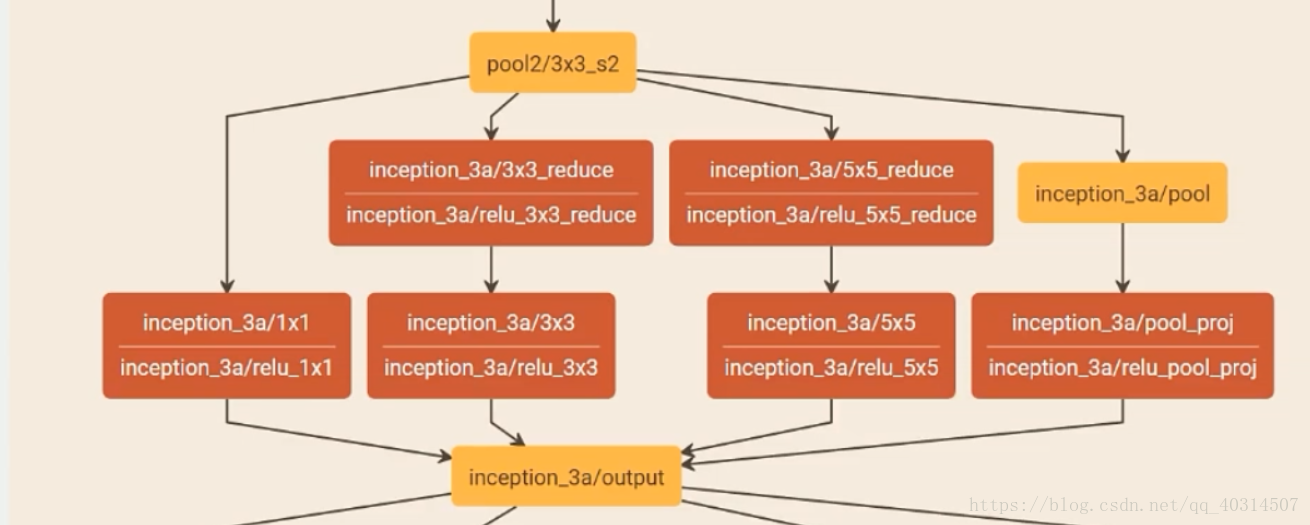
图中Inception结构中,不同大小的卷积核意味着不同大小的感受野,最后的合并意味着不同尺度特征的融合。inception是googleNet网络很有特点的结
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1870
1870

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









