




第一步:
先找到新闻资讯存在的那个非同步存取的链接,该链接一般位在js那个分类下。
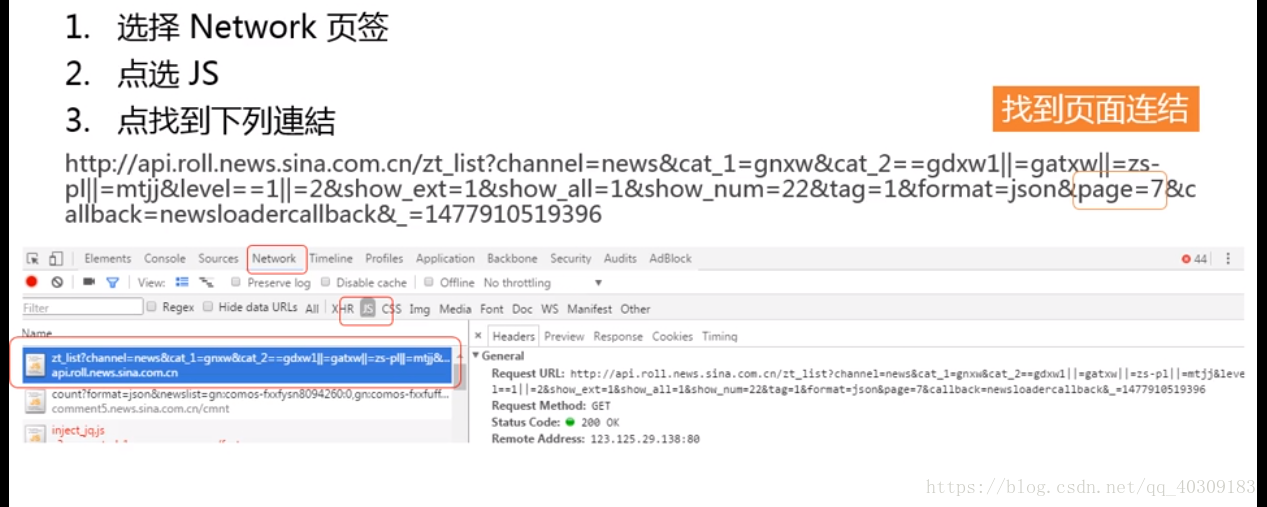
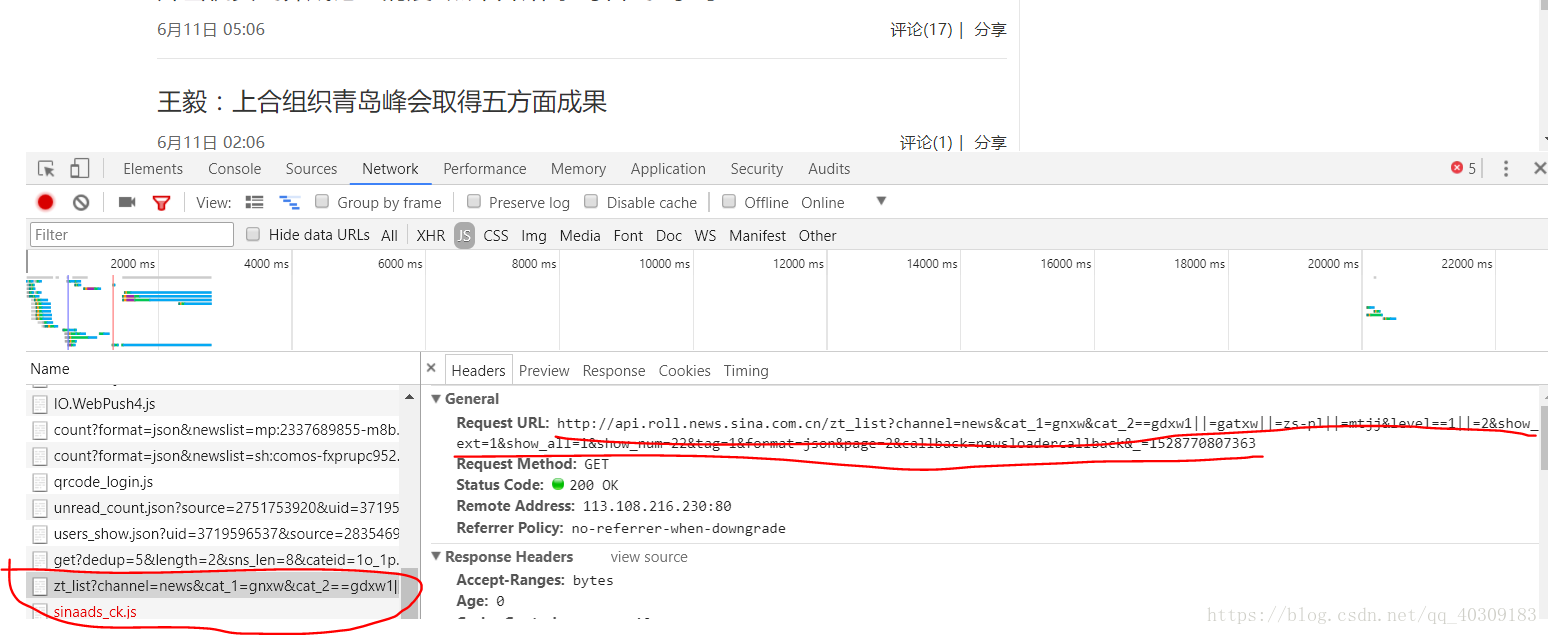
然后把这个链接给requests 让它存取内部的资料。
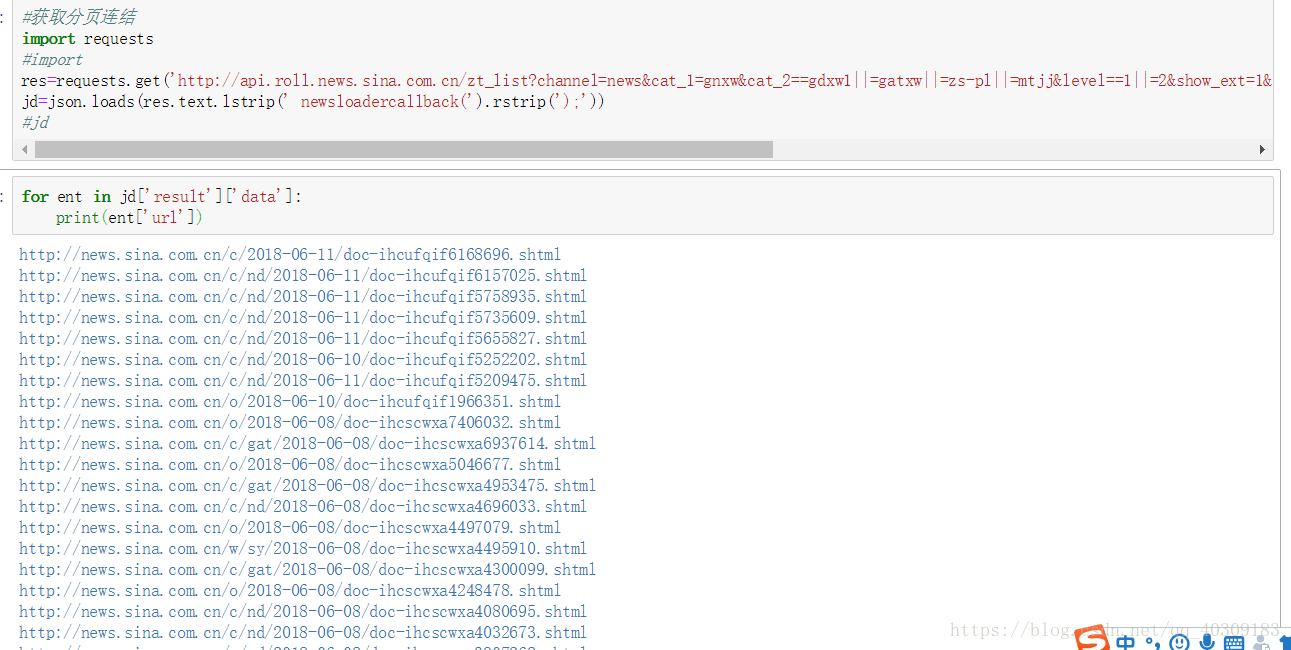
取到之后你会发现,这个内容前后两边有保护层,即一个“(”和 “);”,这个时候可以用lstrip和rstrip去截掉这些多余的字符串。
最后返回的就是一个json资料,通过json.loads将它赋给一个字典。
早在之前就已经发现,这个字典是分层次的,首先是['result'],然后才是['data'],而我们需要的链接就在data下的['url']里面
 本文介绍了一种从非同步存取链接中获取新闻资讯的方法,包括定位链接、使用requests请求数据、去除保护层字符串以及解析返回的JSON内容来提取所需资讯链接。
本文介绍了一种从非同步存取链接中获取新闻资讯的方法,包括定位链接、使用requests请求数据、去除保护层字符串以及解析返回的JSON内容来提取所需资讯链接。
第一步:
先找到新闻资讯存在的那个非同步存取的链接,该链接一般位在js那个分类下。
然后把这个链接给requests 让它存取内部的资料。
取到之后你会发现,这个内容前后两边有保护层,即一个“(”和 “);”,这个时候可以用lstrip和rstrip去截掉这些多余的字符串。
最后返回的就是一个json资料,通过json.loads将它赋给一个字典。
早在之前就已经发现,这个字典是分层次的,首先是['result'],然后才是['data'],而我们需要的链接就在data下的['url']里面

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言





















 1847
1847





