



 本文介绍了作者初次尝试制作爬虫的过程,包括理解数据抽取、转换、存储的ETL流程,利用requests和BeautifulSoup进行网页请求和解析。通过分析网页源代码,抓取新浪新闻的标题、发布时间、内容等信息,并处理了编码问题。同时,文章提到了在Jupyter Notebook中遇到的问题及解决方案,以及一些实用的快捷键。
本文介绍了作者初次尝试制作爬虫的过程,包括理解数据抽取、转换、存储的ETL流程,利用requests和BeautifulSoup进行网页请求和解析。通过分析网页源代码,抓取新浪新闻的标题、发布时间、内容等信息,并处理了编码问题。同时,文章提到了在Jupyter Notebook中遇到的问题及解决方案,以及一些实用的快捷键。
learn from:天善智能云课堂
1.原理:
要把非结构化数据整理为结构化数据
方法:数据抽取,转换,存储(Data ETL)

ETL(Extract提取,Transformation转换,Loading装载)
架构:
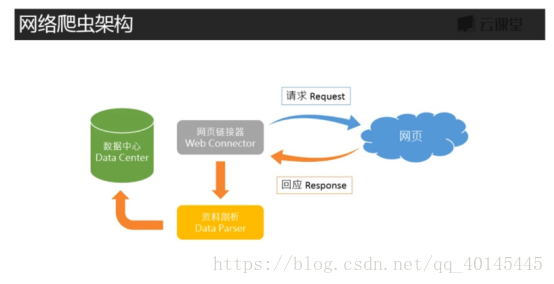
2.信息查看:
(1).网页右键,点击检查
(2).点击network
(3).所要的信息百分之90在doc
3.必备套件:
~如果安装anaconda,anaconda自带了BeautifulSoup4,Requests,jupyter notebook免安装
要爬的网址可以在Chrome浏览器进入要爬的主页,右键检查元素,点击Network,然后刷新一下网页(快捷键:F5)
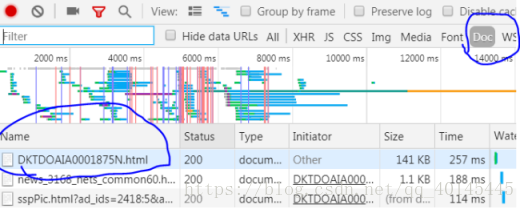
点击doc,再点击第一个网页,下图圈中的网址就包含大部分要爬的资源
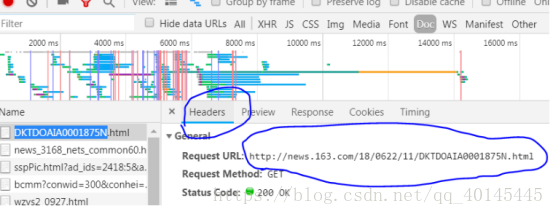
输入代码:
import requests
res = requests.get("要爬的网址")
print(res.text)
发现有乱码现象,把res.text改为res.encoding可查看预设的编码
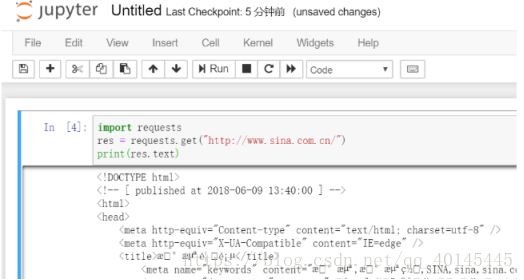
添加一行代码 res.encoding = '预设的编码',就不会乱码了
代码具体如下:
import requests
res = requests.get("要爬的网址")
res.encoding = 'utf-8'
print(res.text)
验证你所要的信息是在你截取的网址上,由于我的是chrome浏览器,直接ctrl + f 进行查找,把你想要到信息粘贴到搜索栏:
把非结构化数据转换为结构化数据:

from bs4 import BeautifulSoup
html_sample = ' \
<html> \
<body> \
<h1 id ="title"> hello world </h1> \
<a href ="#" class = "link"> This is link1</a> \
<a href ="# link2" class = "link"> This is link2</a> \
</body> \
</html> '
soup = BeautifulSoup(html_sample)
print(soup.text)
代码加入parser ,即 ‘html.parser’
是解析Html的一个工具。python自带的
from bs4 import BeautifulSoup
html_sample = ' \
<html> \
<body> \
<h1 id ="title"> hello world </h1> \
<a href ="#" class = "link"> This is link1</a> \
<a href ="# link2" class = "link"> This is link2</a> \
</body> \
</html> '
soup = BeautifulSoup(html_sample,'html.parser')
print(soup.text)


遇到的问题
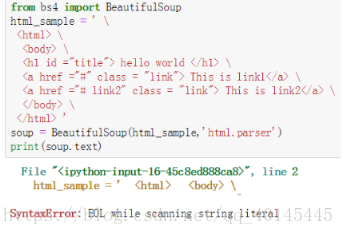
1.如果出现如下图情况,一般不是网上所说的字符串结尾不能有“ \ ”,因为该字符串结尾为" > ",一般是因为某行多了空格,找到多打的空格,将其删掉即可。
2.安装jupyter后打不开
1.可在相应的Python35\Scripts中找到jupyter-notebook.exe,点击看看是否能打开
2.万恶的防火墙(很多程序员软件明明安装好了,甚至找到并点击EXE都不能运行,很大原因是防火墙的问题)
win + r,运行control
点击系统和安全
关闭防火墙(或自己在百度上找防火墙允许程序允许的方法)
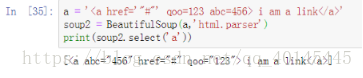
3.如图,原因是href="#"不是href='#'

正确结果:
4.如图,原因是id用#,class用.

选择标题注意是class还是id
正确:

5.
import requests
import json
res =requests.get('http://cre.mix.sina.com.cn/api/area/news?other=commentid&num=22&page=1&offset=0&callback=jsonpcallback1529853932472&_=1529853959865')
print(res.text.rstrip(');').lstrip('jsonpcallback1529853932472('))
.rstrip('')去除不了最后面的 );
网址有问题,换个网址

6.
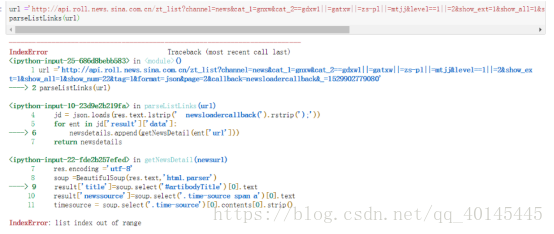
抓取新闻内文页面:
import requests
from bs4 import BeautifulSoup
res = requests.get('http://news.sina.com.cn/china/')
res.encoding = 'utf-8'
soup = BeautifulSoup(res.text,'html.parser')
抓取标题:
soup.select(".main-title")[0].text
取得新闻发布时间:
当新闻时间的class或id含有其他元素时,
timesource =soup.select(".date")[0].contents[0].strip()
此时timesource为str格式需转换为日期格式:
from datetime import datetime
dt =datetime.strptime(timesource,'%Y年%m月%d日 %H:%M')
print(dt)
.strip() 能删除开头或是结尾的字符
时间转字符串 (strftime):
dt.strftime('%Y-%m-%d %H:%M')
整理新闻内容:
article =[]
for p in soup.select('.article p')[:-1]:
article.append(p.text.strip())
print(article)
'\n'.join(article)
简短写法:'\n'.join([p.text.strip() for p in soup.select('.article p')[:-1]])
join()方法 返回通过指定字符连接序列中元素后生成的新字符串
取得新闻编辑者的名称:
editor =soup.select(".ep-editor")[0].text.strip('责任编辑:')
.strip('责任编辑:') 去除“责任编辑:”字眼
取得评论数:
soup.select('.post_cnum_tie js-tielink js-tiejoincount')
结果为空,如图:

(1)找寻评论出处
可能在js那里
import requests
comments = requests.get('找到的js网址')
import json
jd = json.loads(comment.text.strip('var data='))
取得评论数与评论内容:
jd = json.loads(comments.text.strip('var data='))
jd['result']['count']['total']
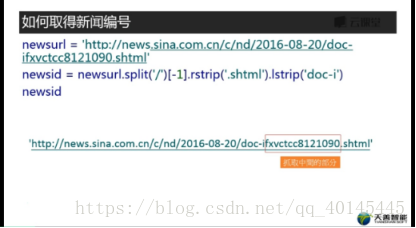
取得新闻id
方法1
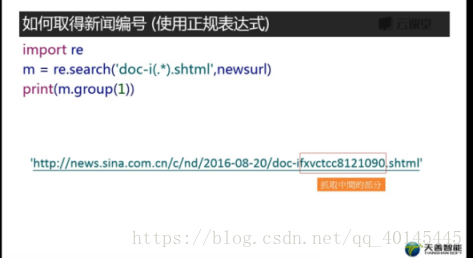
方法2
整理成统一函式

import requests
from bs4 import BeautifulSoup
def getNewsDetail(newsurl):
result={}
res = requests.get(newsurl)
res.encoding ='utf-8'
soup =BeautifulSoup(res.text,'html.parser')
result['title']=soup.select('#artibodyTitle')[0].text
result['newssource']=soup.select('.time-source span a')[0].text
timesource = soup.select('.time-source')[0].contents[0].strip()
result['dt']= datetime.strptime(timesource,'%Y年%m月%d日 %H:%M')
result['article']= '\n'.join([p.text.strip() for p in soup.select('#artbody p')[:-1]])
result['editor'] = soup.select('.article-editor')[0].text.strip('责任编辑:')
result['comments'] = getCommentCounts(newsurl)
return result
然后我们找到分页连结
方法如下:
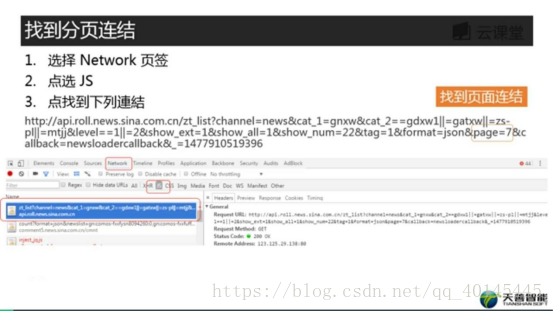
剖析分页信息
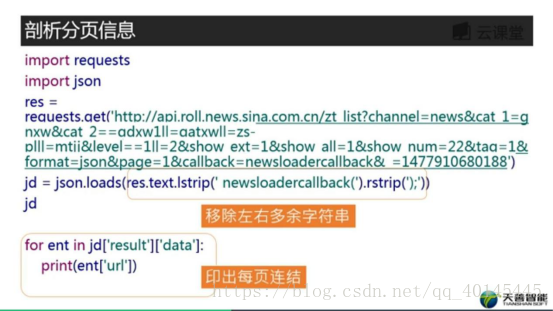
结果:
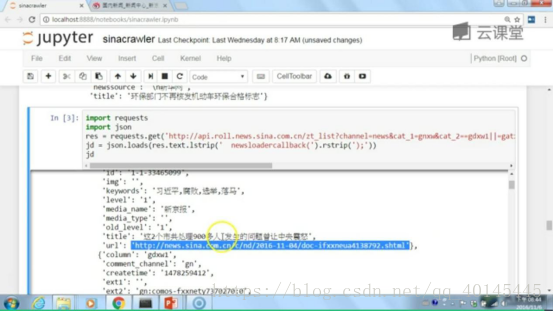
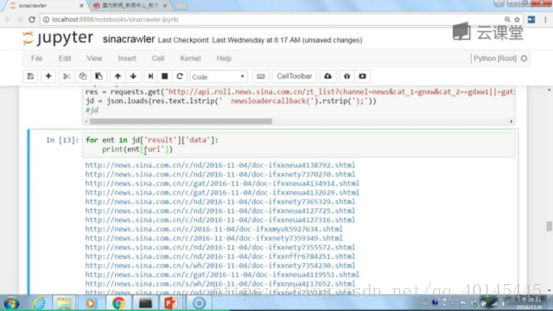
整成新闻的URL链接
建立链式剖析清单函式:

代码实现
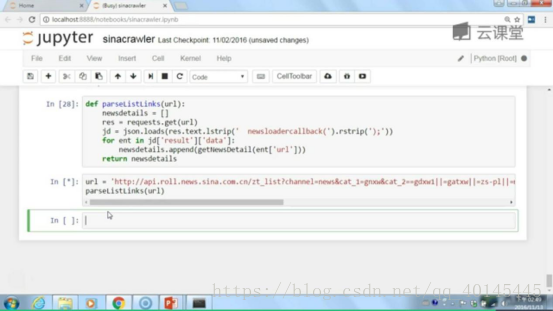
结果
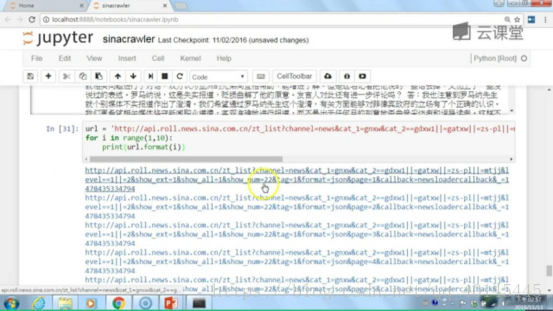
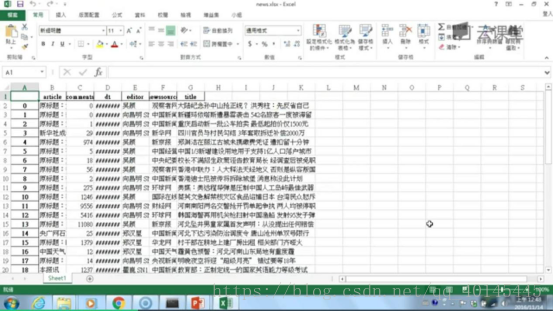
最后我们将所抓的数据保存到自己想Excel或者数据库
方法

使用Pandas整理
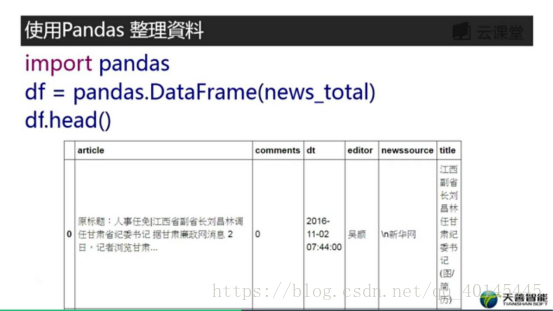
运行之后
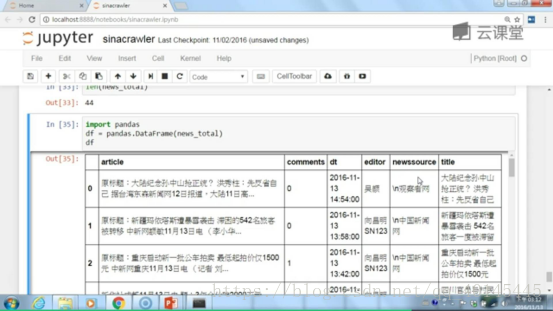
比如保存到自己的Excel
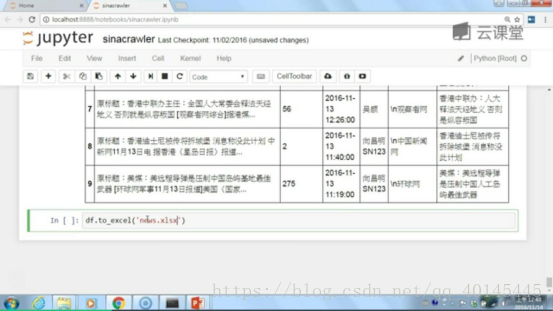
哈哈最后的结果
第一次尝试做爬虫可能还有很多地方做的不够好讲的也不好,哈哈!欢迎各位大神给予指导
另外附带一些Jupyter Notebook的快捷键
Jupyter Notebook 的快捷键的使用教程
有两种键盘输入模式。
编辑模式 (按键 Enter 开启),可以在单元中键入代码或文本;这时的单元框线是绿色的。
命令模式 (按键 Esc 开启),键盘输入运行程序命令;这时的单元框线是灰色。
忘了快捷键,直接按H(如果在单元里需要点击esc键后按H) : 显示快捷键帮助
一般写代码时流程:
1.一般是先进入是直接打代码
(1)运行本单元代码:Ctrl-Enter
(2)运行本单元代码选中下个单元:Shift-Enter
然后按enter编辑下个单元
2.在单元里写代码时好用的快捷键
· Ctrl-] : 缩进
· Ctrl-[ : 解除缩进
· Ctrl-A : 全选
· Ctrl-Z : 复原
· Tab : 代码补全或缩进
3.编辑单元时好用的快捷键
D,D : 删除选中的单元
Z : 恢复删除的最后一个单元
B : 在下方插入新单元
Space(空格键): 向下滚动
Ctrl-S : 文件保存

















 5743
5743

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









