







每日leetcode(27)
无重复字符的最长子串,题目如下:
‘’’
给定一个字符串,请你找出其中不含有重复字符的 最长子串 的长度。
示例 1:
输入: “abcabcbb”
输出: 3
解释: 因为无重复字符的最长子串是 “abc”,所以其长度为 3。
示例 2:
输入: “bbbbb”
输出: 1
解释: 因为无重复字符的最长子串是 “b”,所以其长度为 1。
示例 3:
输入: “pwwkew”
输出: 3
解释: 因为无重复字符的最长子串是 “wke”,所以其长度为 3。
请注意,你的答案必须是 子串 的长度,“pwke” 是一个子序列,不是子串。
‘’’
这道题最初的想法是遍历循环,暴力算法,无奈超时,在下面也贴上超时代码吧,大概就是判断下一个字符是否在当前字符串,不在则右移,在的话就找到该元素第一个元素,在其之后一个元素位置重新开始判断
class Solution:
def lenthOfLongestSubstring(self,s):
for i in range(len(s)-1):
if s[i+1] in s[:i+1]:
p=s.index(s[i+1])
if i+1<i+1-p+1:
return self.lenthOfLongestSubstring(s[p+1:]) if self.lenthOfLongestSubstring(s[p+1:])>i+1 else i+1
else:
return self.lenthOfLongestSubstring(s[i+1:]) if self.lenthOfLongestSubstring(s[i+1:])>i+1 else i+1
return len(s)
为了提高时间效率,根据评论使用滑窗算法,其算法介绍如下图,在题解看到的,很生动形象,搬过来
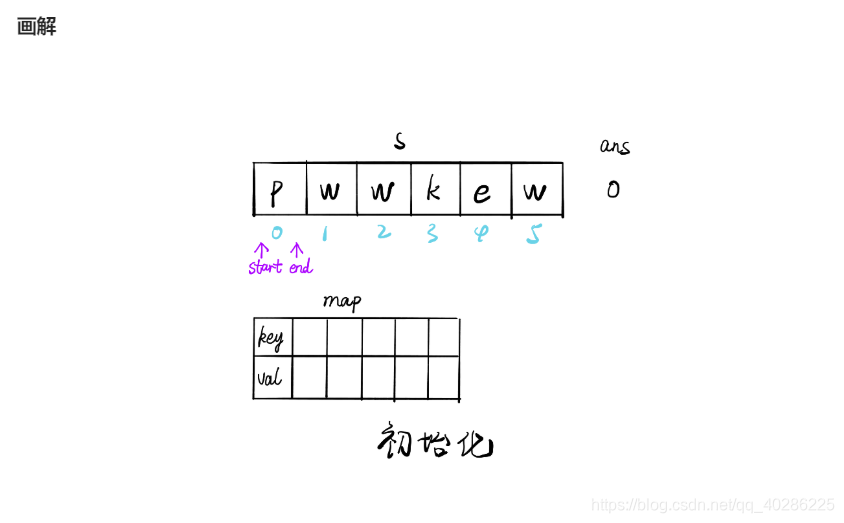
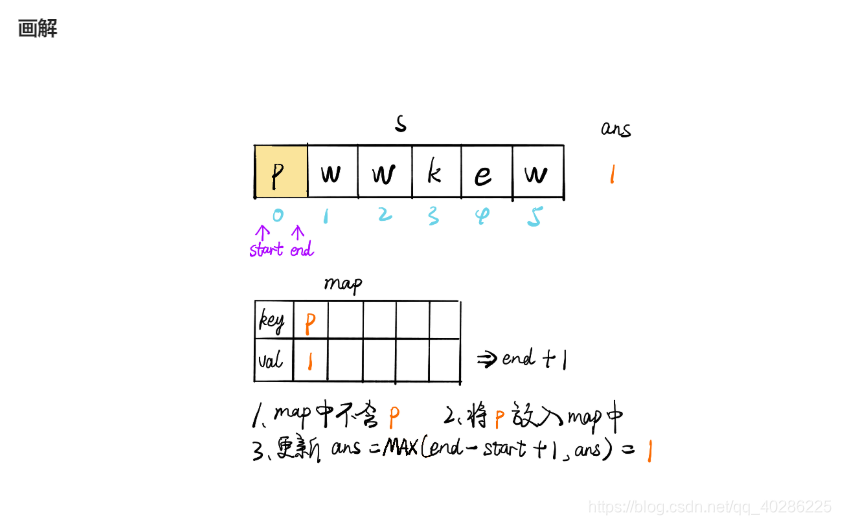
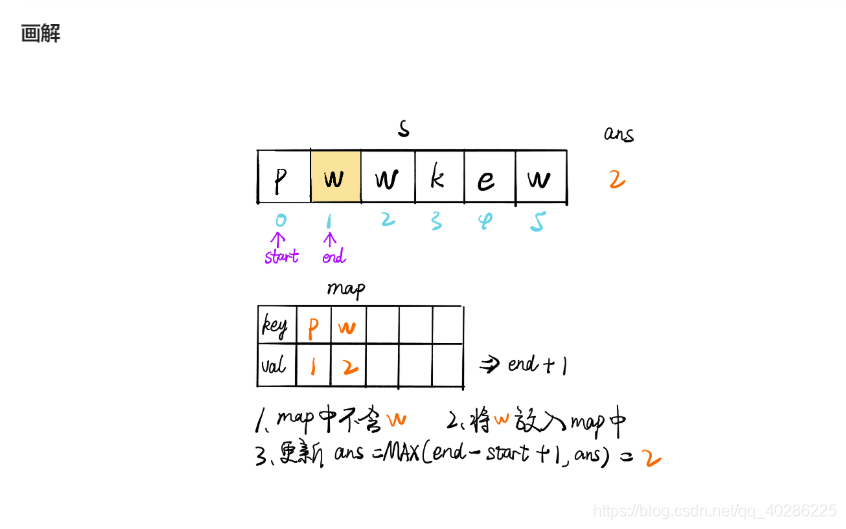
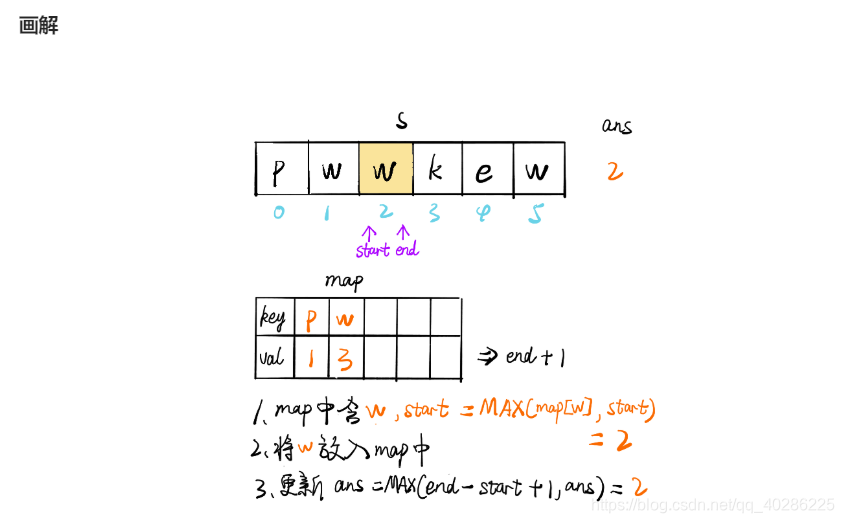
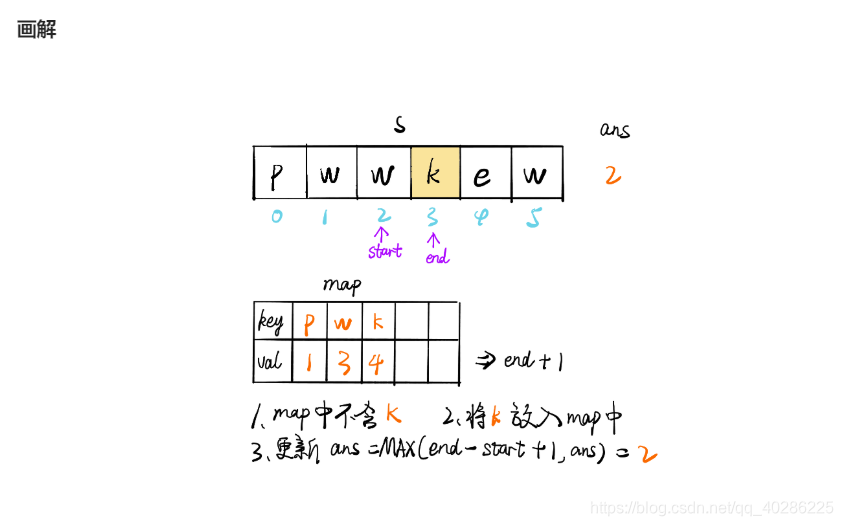
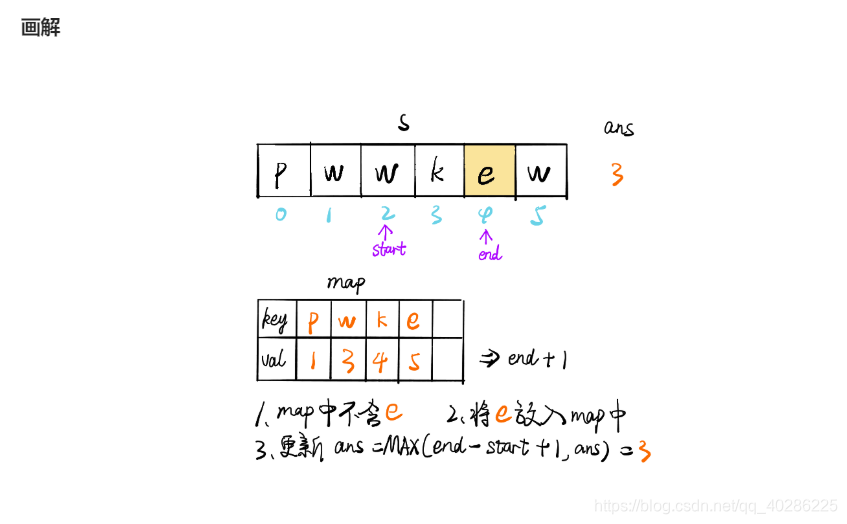
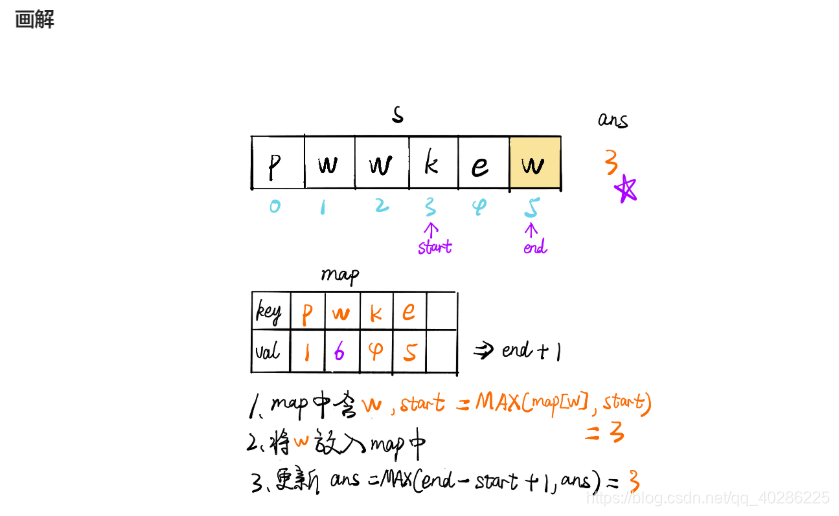
下面贴上python代码
class Solution:
def lengthOfLongestSubstring(self, s: str) -> int:
a={}
start,end=0,0
ans=0
Max=0
for i in range(len(s)):
if s[i] in a.keys():
start=max(a[s[i]],start)
a[s[i]]=i+1
ans=max(end-start+1,ans)
end+=1
return ans
但是呢,这个时间效率其实很不是很好
看到题解里有个老哥的算法效率上有了优化,提高了20ms
class Solution:
def lengthOfLongestSubstring(self, s: str) -> int:
if s == '':
return 0
window = set()
left = 0
max_len = 0
cur_len = 0
for ch in s:
cur_len += 1
while ch in window:# 从前向后删除,直到删除了ch
window.remove(s[left])
left += 1
cur_len -= 1
if cur_len > max_len:
max_len = cur_len
window.add(ch)
return max_len1
这是优化的滑窗算法,先码住

















 715
715

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









