







文章中的题目来自于:https://www.iamshuaidi.com/1402.html。如下仅是作者个人的总结回答,希望能为你带来帮助和启发。
笔者不过是一个双非研究生,科研之外做点感兴趣的事情。请相信学习成长的路上并不孤单,如果有任何疑问欢迎私信~~~~
文章内容皆是个人学习过后自己的一些观点看法,希望能给你带来帮助启发,而不是单纯的去应对面试。请相信:追求卓越,机会自会向你而来。陌生人让我们彼此共勉~~~。
1.谈谈你对索引的认识
关于对索引的认识,其实这个问题就比较笼统了。由索引我们可以扩展出多个点,比如索引的作用、innodb中采用的索引模型、索引分类、各类索引特点等等。为此给出如下思维图来总结凝练回答。
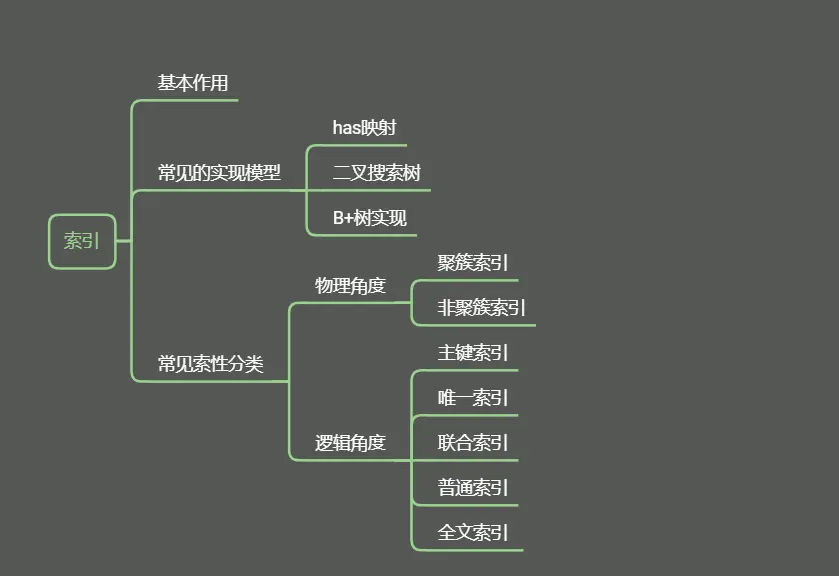
索引作用:数据库的出现皆在实现数据文件的持久化存储,面对海量的数据如何能快速找寻到数据就是一直探究的问题。索引的出现皆在为了提高数据的查询效率。
比如一本厚厚的字典,如果你想快速找到其中的某一个知识点,在不借助目录的情况下,那我估计你可得找一会儿。同样,对于数据库的表而言,索引其实就是它的“目录”。皆在帮助我们快速找到数据信息。
索引常见的实现模型
为了快速找到数据信息,常见的模型由hash映射, 二叉搜索等模型。
hash映射思路:把值放在数组里,用一个哈希函数把key 换算成一个确定的位置,然后把 value 放在数组的这个位置
但hash存储时遇到的问题就是哈希冲突,即不同的数值信息在指定的hash映射信息可能产生相同的hash值,此时常见的解决方法一般采用拉链法。
同时,其一大限制条件在于哈希表这种结构适用于只有等值查询的场景,无法用于部分查找和范围查找。
把具有相同散列地址的关键字(同义词)值放在同一个单链表中,称为同义词链表。有m个散列地址就有m个链表,同时用指针数组T[0..m-1]存放各个链表的头指针,凡是散列地址为i的记录都以结点方式插入到以T[i]为指针的单链表中。T中各分量的初值应为空指针。
平衡二叉搜索树模型
二叉搜索树主要如下特点:
左孩子值小于父节点
右孩子值大于父节点
同时树的左子树 ,右子树高度差不超1
在这种约束条件下,面对大数据量信息时,此时形成的树高可以为O(logN)的高度,此时当我们查询数据信息时,所需的时间复杂度也可以从O(N)降低至O(logN),进一步提升查询的效率。
平衡二叉树所带来的问题
平衡二叉的出现确实进一步加快了数据信息的查询,但是数据库保存索引信息不仅需要保存至内存之中,更需要保存至磁盘之上,这样才能保证信息的持久化存储。I/O操作次数成为限制该模型的主要瓶颈。
设想加入有一个100万节点的平衡二叉树,其最终树高为20。一次查询可能需要访问20个数据块。在机械硬盘时代,从磁盘随机读一个数据块需要10 ms左右的寻址时间。也就是说,对于-一个100万行的表,
如果使用二叉树来存储|单独访问-一个行可能需要20个10ms的时间。
为了进一步解决该问题,由此衍生出B树、B+树。为了让一个查询尽量少地读磁盘,就必须让查询过程访问尽量少的数据块。N叉树也即出现,而mysql中的INNODB也采用B+树作为了查询索引的模型。
2:聚簇索引or非聚簇索引
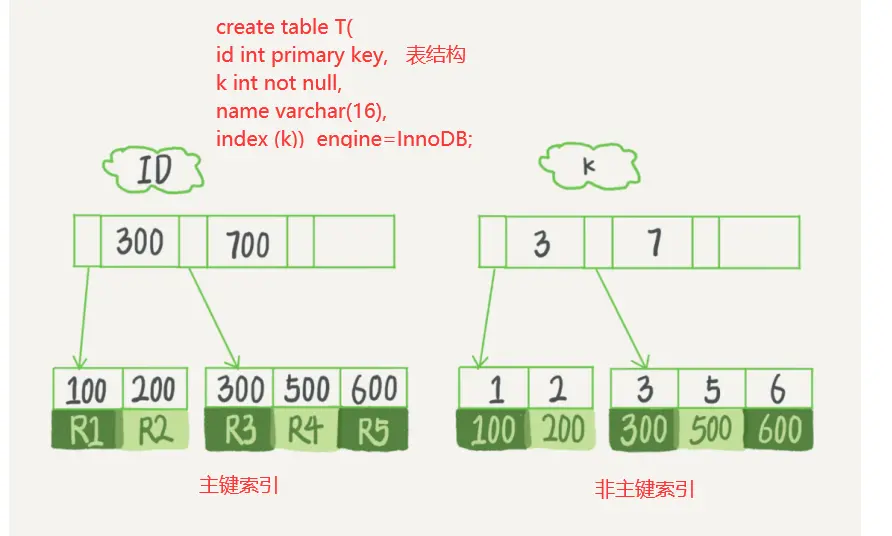
聚簇索引和非聚簇索引的区别在于B+树中叶子结点中是否保存了数据的整行信息,通俗来来看:
聚簇索引的叶子节点存的是整行数据。在 InnoDB 里,聚簇索引也被称为主键索引。
非聚簇索引的叶子节点内容是主键的值。在 InnoDB 里,非主键索引也被称为二级索引
3:逻辑分类下索引的特点
-
普通索引:最基本的索引,没有任何限制
-
唯一索引:与"普通索引"类似,不同的就是:索引列的值必须唯一,但允许有空值。
-
主键索引:它是一种特殊的唯一索引,不允许有空值。
-
全文索引:仅可用于 MyISAM 表,针对较大的数据,生成全文索引很耗时好空间。
-
联合索引:为了更多的提高mysql效率可建立组合索引,遵循”最左前缀“原则。
最左前缀这个规则主要针对并应用在联合索引之上。B+ 树的数据项是复合的数据结构,比如设定联合 索引为 (name,age,sex) 的时候,B+ 树是按照从左到右的顺序来建立搜索树。
比如当 (张三,20,F) 这样的数据来检索的时候,B+ 树会优先比较 name 来确定下一步的所搜方向,如果 name 相同再依次比较 age 和 sex,最后得到检索的数据;
但当 (20,F) 这样的没有 name 的数据来的时候,b+ 树就不知道第一步该查哪个节点,因为建立搜索树的时候 name 就是第一个比较因子,必须要先根据 name 来搜索才能知道下一步去哪里查询。
比如当 (张三, F) 这样的数据来检索时,B+ 树可以用 name 来指定搜索方向,但下一个字段 age 的缺失,所以只能把名字等于张三的数据都找到,然后再匹配性别是 F 的数据了, 这个是非常重要的性质,即索引的最左匹配特性。(这种情况无法用到联合索引)
对于主键索引 和唯一索引的区别可以这样来看:主键一定是唯一性索引,唯一性索引并不一定主键。
主键是一种约束,唯一索引是一种索引,两者在本质上是不同的。主键创建后一定包含一个唯一性索引,唯一性索引并不一定就是主键。唯一性索引列允许空值,而主键列不允许为空值。
主键列在创建时,已经默认为空值 + 唯一索引了。主键可以被其他表引用为外键,而唯一索引不能。同时一个表最多只能 创建一个主键,但可以创建多个唯一索引。主键更适合那些不容易更改的唯一标识,如自动递增列、身 份证号等。
主键的执行计划优先级要高于唯一索引。 两者可以提高查询的速度。
4:覆盖索引
如果一个索引包含了满足查询语句中字段与条件的数据就叫做覆盖索引。具有以下优点:
-
索引通常远小于数据行的大小,只读取索引能大大减少数据访问量。
-
一些存储引擎(例如:MyISAM)在内存中只缓存索引,而数据依赖于操作系统来缓存。因此,只访问索引可以不使用系统调用(通常比较费时)。
-
对于 InnoDB 引擎,若辅助索引能够覆盖查询,则无需访问主索引。
5:判断索引是否使用
此时可以使用 Explain 命令来查看语句的执行计划,MySQL 在执行某个语句之前,会将该语句过一遍查询优化器,之后会拿到对语句的分析,也就是执行计划,其中包含了许多信息。
通过其中和索引有关的信息来分析是否命中了索引,例如:possilbe_key、key、key_len 等字段,其中possible_keys:表示查询时,可能使用的索引。key表示实际使用的索引。key_len表示索引字段的长度,分别说明了此语句可能会使用的索引、实际使用的索引以及使用的索引长度。
我,毅航同学。一名山大的普通计算机研究生,业余读读书,顺带总结些技术学习上的感悟。希能帮助到你。欢迎你同我一起交流,共同进步。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









