







 本文深入解析Java集合框架,包括Iterable、Collection、List接口,以及ArrayList、LinkedList、Vector和Stack的具体实现。探讨了不同集合类的内部结构,如数组、链表和同步特性,对比了它们在添加、删除和获取元素上的性能差异。
本文深入解析Java集合框架,包括Iterable、Collection、List接口,以及ArrayList、LinkedList、Vector和Stack的具体实现。探讨了不同集合类的内部结构,如数组、链表和同步特性,对比了它们在添加、删除和获取元素上的性能差异。
先上图
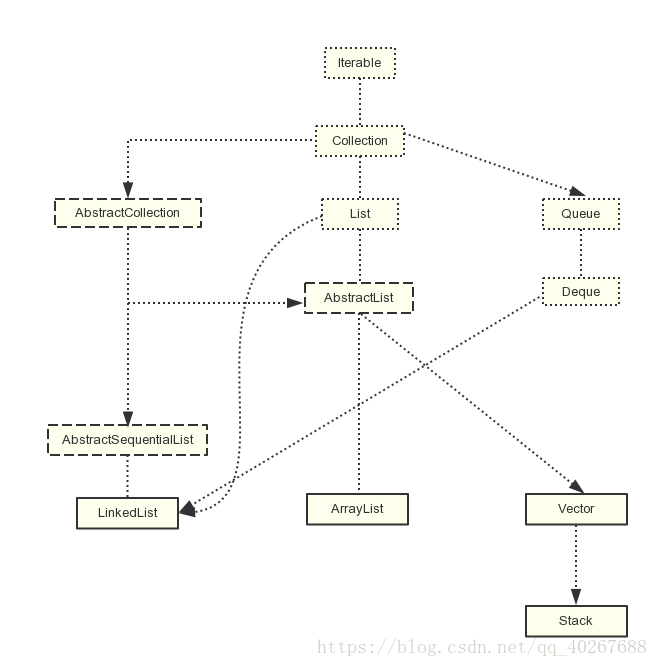
图里面的框框,实线框代表类,小点点的框代表接口,虚线框代表抽象类
先看三个接口,Iterable、Collection、List三个接口,选择先说这个,是因为图中的子类都直接或间接实现了这三个接口。在这里只说一些主要的方法,不会把全部的方法都列举出来
1.Iterable、Collection、List
Iterable接口,在刚学习Java的时候应该都接触过这个接口,迭代器,主要是遍历数据时候用的
//获取迭代器
Iterator<T> iterator();
//遍历集合元素
default void forEach(Consumer<? super T> action) {
Objects.requireNonNull(action);
for (T t : this) {
action.accept(t);
}
}第二个方法的default关键字是在,JDK8才有的,就是为了接口可以提供一个默认的实现。Consumer可以理解是一个帮助接口,给用户提供一个accept方法。如果你懒得写foreach,可以直接就这个方法,比如
List<String> list = new ArrayList<>();
list.add("sun");
list.add("xiao");
list.add("bing");
list.forEach(new Consumer<String>() {
@Override
public void accept(String s) {
System.out.println(s);
}
});这段代码将会依次打印出集合的数据
Collection接口和List接口方法都差不多
2.ArrayList
ArrayList继承于AbstractList抽象类,AbstractList又继承于AbstractCollection抽象类,好吧,那就先说AbstractCollection吧
就像AbstractCollection的名字一样,它只是简单的实现了Collection的几个方法
看一下常用的几个方法
isEmpty、contains
public boolean isEmpty() {
return size() == 0;
}很easy
public boolean contains(Object o) {
Iterator<E> it = iterator();
if (o==null) {
while (it.hasNext())
if (it.next()==null)
return true;
} else {
while (it.hasNext())
if (o.equals(it.next()))
return true;
}
return false;
}这个方法的实现我看的时候吃了一鲸,还会判断对象为null的情况,后来我试了一下,还真的返回true
AbstractList也是一样,对List接口简单的实现了几个方法,这几个方法,ArrayList基本都会重写,所以就不列出来了,这个类比较重要的就是实现了List的listIterator方法,这个方法返回一个实现了ListIterator的ListItr类,这个类下面用的的时候在说吧
ArrayList集合的实现是通过类的内部维护一个数组,初始化是数组大小是10,可以通过构造方法指定数组大小
先看一下常用的add方法
public boolean add(E e) {
ensureCapacityInternal(size + 1);
elementData[size++] = e;
return true;
}ensureCapacityInternal方法会判断如果需要会增加数组的大小,elementData就是ArrayList内部维护的数组,size就是当前数据的个数,看一下是如何增长数组大小的
private static final int DEFAULT_CAPACITY = 10;
private static final Object[] EMPTY_ELEMENTDATA = {};
private void ensureCapacityInternal(int minCapacity) {
if (elementData == EMPTY_ELEMENTDATA) {
minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);
}
ensureExplicitCapacity(minCapacity);
}继续看ensureExplicitCapacity
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}modCount后面在细说,它的作用是,如果有多个线程操作,则会抛出异常。
判断如果minCapacity大于当前内部数组的大小责调用grow方法
private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}这段代码也挺好理解的,就是每次分配当前数组大小的一半大小,这就是第一个if判断的,上面传过来的是size+1,肯定不能每添加一个数据就扩展一次数组。第二个方法判断是否还有剩余的可分配空间,然后调用hugeCapacity方法。最后通过Arrays.copyOf扩展数组。
先看一下hugeCapacity方法,然后再看Arrays.copyOf方法是如何扩展数组的
private static int hugeCapacity(int minCapacity) {
if (minCapacity < 0) // overflow
throw new OutOfMemoryError();
return (minCapacity > MAX_ARRAY_SIZE) ?
Integer.MAX_VALUE :
MAX_ARRAY_SIZE;
}没什么可说的,主要就是如果溢出了会抛一个异常
public static <T> T[] copyOf(T[] original, int newLength) {
return (T[]) copyOf(original, newLength, original.getClass());
}public static <T,U> T[] copyOf(U[] original, int newLength, Class<? extends T[]> newType) {
T[] copy = ((Object)newType == (Object)Object[].class)
? (T[]) new Object[newLength]
: (T[]) Array.newInstance(newType.getComponentType(), newLength);
System.arraycopy(original, 0, copy, 0,
Math.min(original.length, newLength));
return copy;
}这里是关键,在这里看到,调用Array.newInstance方法根据新的大小创建了一个新的数组,然后把以前的数据拷贝到新的数组里面
public static native void arraycopy(Object src, int srcPos,
Object dest, int destPos,
int length);最终调用的了System类的arraycopy方法,写成本地的方法,可想而知,如果数据越来越多的话,当然还是用指针和汇编的速度比较快。
src是源数组、是从原数组的srcPos位置开始复制
dest是目标数组、是从destPos开始赋值
length复制的个数
还有一点特别重要,arraycopy复制的是地址。假如有两个数组,把数组一复制到数组二,那么当数组一的值改变是,数组二也会跟着改变
就到这里了jvm代码就不分析了就兴趣的可以看看这个
http://www.360doc.com/content/14/0713/19/1073512_394157835.shtml
String[] strs1 = new String[]{"1", "2", "3"};
String[] strs2 = new String[]{"4", "5", "6"};
System.arraycopy(strs1, 1, strs2, 1, 2);
strs2[1] = "jianpan";
for (String s : strs2){
System.out.println(s);
}猜猜这段代码会输出什么?
ArrayList的add方法到这里就结束了,基本就是判断内部数组是否有空余,如果没有就在分配,分配的大小是当前数组的一半,分配的方式是通过创建新的数据并把以前的数据复制过来,最后把add的参数设置到数组里面
在看一下常用的remove方法
如果我们在写这个ArrayList,我们怎么才能删除这个数组任意位置的元素呢?用ArrayList的时候可能没想过,它是怎么删除的,反正我们直接掉个remove方法就把元素删除了。
remove还是通过刚才讲的System.arraycopy方法
public E remove(int index) {
if (index >= size)
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
modCount++;
E oldValue = (E) elementData[index];
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
elementData[--size] = null; // clear to let GC do its work
return oldValue;
}如果理解了System.arraycopy方法,那么看这段代码应该很easy
ArrayList的方法就说这些了,知道了add和remove方法想去看其他方法的源码应该不是很难了。ArrayList还有一个线程操作问题,如果有多个线程同时对ArrayList执行添加操作,那么就可能出现,一个线程刚好给内部数组最后一个元素赋值,而恰巧另一个线程给下一个元素赋值,结果就会抛个异常了。如果对线程有同步要求的话,可以通过这种方式
List list = Collections.synchronizedList(new ArrayList(...));还有就是上面说的modCount字段的同步问题,这个字段在ArrayList内部实现的迭代器里面的方法才会用到,如果你不用这个迭代器的话,那么不关注这个也行,看一小段代码吧
if (modCount != expectedModCount)
throw new ConcurrentModificationException();恩,在内部的迭代器就是这么用的
3.LinkedList
LinkedList的内部实现和ArrayList区别还是挺大的。LinkedList是通过在内部维护一个链表来实现列表的,以前是不是都听过LinkedList添加快,查询慢接下来就看看为什么,我们就从add、remove、get方法入手。而LinkedList还实现了Deque接口的方法,如addFirst、addLast等方法,LinkedList的这些方法的实现都是操作内部的链表,就不重复讲了,看完add、remove、get方法会发现其实都差不多
先看一个内部类
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}就是一个普通的链表,只不过我们一般写这个,不会加上泛型
还有几个关键的字段
transient int size = 0;
transient Node<E> first;
transient Node<E> last;一看名字就知道了,内部链表的大小,链表头,链表尾
现在可以看add方法了
public boolean add(E e) {
linkLast(e);
return true;
}void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}比ArrayList的add方法简单好多
没什么可说滴,知道链表,看这段代码就很easy
再看remove方法
public E removeFirst() {
final Node<E> f = first;
if (f == null)
throw new NoSuchElementException();
return unlinkFirst(f);
}public boolean remove(Object o) {
if (o == null) {
for (Node<E> x = first; x != null; x = x.next) {
if (x.item == null) {
unlink(x);
return true;
}
}
} else {
for (Node<E> x = first; x != null; x = x.next) {
if (o.equals(x.item)) {
unlink(x);
return true;
}
}
}
return false;
}通过这里就可以看出来查询慢了,当我要删除一个数据的时候,就需要遍历链表然后调用unlink方法删除。如果我们就1w条数据时,删除的恰巧是最后一个,那么就要遍历所有。
E unlink(Node<E> x) {
// assert x != null;
final E element = x.item;
final Node<E> next = x.next;
final Node<E> prev = x.prev;
if (prev == null) {
first = next;
} else {
prev.next = next;
x.prev = null;
}
if (next == null) {
last = prev;
} else {
next.prev = prev;
x.next = null;
}
x.item = null;
size--;
modCount++;
return element;
}很简单,只不过需要先知道链表,链表应该都会的吧~
这么快就最后一个方法了get
public E get(int index) {
checkElementIndex(index);
return node(index).item;
}首先检查是否越界,然后调用node方法获取Node对象,然后获取对象的item元素
先看下是怎么判断的,然后在看node方法是怎么获取Node对象的
private void checkElementIndex(int index) {
if (!isElementIndex(index))
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}private boolean isElementIndex(int index) {
return index >= 0 && index < size;
}Node<E> node(int index) {
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}这个挺好玩的哈,先判断如果index小于当前链表大小的一半,就从first开始查,如果大于一半就从last开始查。相当于ArrayList的get方法这个可是慢多了,ArrayList直接就获取了数组的元素
public E get(int index) {
if (index >= size)
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
return (E) elementData[index];
}到这里LinkedList就结束了,留个小问题,你知道LinkedList的get方法的时间复杂度是什么嘛?欢迎留言~
3.Vector
Vector的实现可以说和ArrayList一样,没太大区别,就是Vector操作元素的方法都是线程同步的,所以这个就不多说了
4.Stack
Stack继承于Vector类,所以Stack类的内部也是维护一个数组,听名字就知道是栈,所以必定会提供入栈和出栈方法。入栈方法push和出栈方法pop,都很简单,先看push方法然后再看pop方法
public E push(E item) {
addElement(item);
return item;
}push方法只是添加一个元素,所以这里就调用的父类的addElement方法了
public synchronized void addElement(E obj) {
modCount++;
ensureCapacityHelper(elementCount + 1);
elementData[elementCount++] = obj;
}跟ArrayList的add方法一样,不多说
pop方法
public synchronized E pop() {
E obj;
int len = size();
obj = peek();
removeElementAt(len - 1);
return obj;
}先通过内部的peek方法获取最后一个对象,也就是栈低的元素,然后调用removeElementAt方法删除栈低元素,先看peek方法,然后再看removeElementAt方法
public synchronized E peek() {
int len = size();
if (len == 0)
throw new EmptyStackException();
return elementAt(len - 1);
}public synchronized E firstElement() {
if (elementCount == 0) {
throw new NoSuchElementException();
}
return elementData(0);
}E elementData(int index) {
return (E) elementData[index];
}最后其实就是根据index获取内部数组的元素
removeElementAt方法
public synchronized void removeElementAt(int index) {
modCount++;
if (index >= elementCount) {
throw new ArrayIndexOutOfBoundsException(index + " >= " +
elementCount);
}
else if (index < 0) {
throw new ArrayIndexOutOfBoundsException(index);
}
int j = elementCount - index - 1;
if (j > 0) {
System.arraycopy(elementData, index + 1, elementData, index, j);
}
elementCount--;
elementData[elementCount] = null; /* to let gc do its work */
}跟ArrayList的方法差不多,也是通过System.arraycopy方法
恩到这里就结束咯

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









