pd. read_csv( filename)
pd. read_table( filename)
pd. read_excel( filename)
pd. read_sql( query, connection_object)
pd. read_json( json_string)
pd. read_html( url)
pd. read_clipboard( )
pd. DataFrame( dict )
df. to_csv( filename)
df. to_excel( filename)
df. to_sql( table_name, connection_object)
df. to_json( filename)
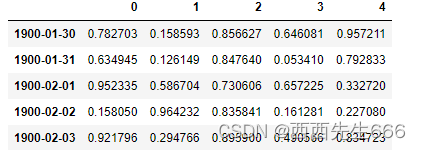
df= pd. DataFrame( np. random. rand( 5 , 5 ) )
df. index = pd. date_range( '1900/1/30' , periods= df. shape[ 0 ] )
df
n= 5
df. head( n)
df. tail( n)
df. shape
df. info( )
"""
<class 'pandas.core.frame.DataFrame'>
DatetimeIndex: 5 entries, 1900-01-30 to 1900-02-03
Freq: D
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 0 5 non-null float64
1 1 5 non-null float64
2 2 5 non-null float64
3 3 5 non-null float64
4 4 5 non-null float64
dtypes: float64(5)
memory usage: 240.0 bytes
"""
df. describe( )
"""
0 1 2 3 4
count 5.000000 5.000000 5.000000 5.000000 5.000000
mean 0.689966 0.426089 0.833323 0.401713 0.628914
std 0.322934 0.351482 0.061687 0.279294 0.326423
min 0.158050 0.126149 0.730606 0.053410 0.227080
25% 0.634945 0.158593 0.835841 0.161281 0.332720
50% 0.782703 0.294766 0.847640 0.490566 0.792833
75% 0.921796 0.586704 0.856627 0.646081 0.834723
max 0.952335 0.964232 0.895900 0.657225 0.957211
"""
df. iloc[ : , 0 ] . value_counts( dropna= False )
df. apply ( pd. Series. value_counts)
"""
0 1 2 3 4
0.053410 NaN NaN NaN 1.0 NaN
0.126149 NaN 1.0 NaN NaN NaN
0.158050 1.0 NaN NaN NaN NaN
0.158593 NaN 1.0 NaN NaN NaN
0.161281 NaN NaN NaN 1.0 NaN
0.227080 NaN NaN NaN NaN 1.0
0.294766 NaN 1.0 NaN NaN NaN
0.332720 NaN NaN NaN NaN 1.0
0.490566 NaN NaN NaN 1.0 NaN
0.586704 NaN 1.0 NaN NaN NaN
0.634945 1.0 NaN NaN NaN NaN
0.646081 NaN NaN NaN 1.0 NaN
0.657225 NaN NaN NaN 1.0 NaN
0.730606 NaN NaN 1.0 NaN NaN
0.782703 1.0 NaN NaN NaN NaN
0.792833 NaN NaN NaN NaN 1.0
0.834723 NaN NaN NaN NaN 1.0
0.835841 NaN NaN 1.0 NaN NaN
0.847640 NaN NaN 1.0 NaN NaN
0.856627 NaN NaN 1.0 NaN NaN
0.895900 NaN NaN 1.0 NaN NaN
0.921796 1.0 NaN NaN NaN NaN
0.952335 1.0 NaN NaN NaN NaN
0.957211 NaN NaN NaN NaN 1.0
0.964232 NaN 1.0 NaN NaN NaN
"""
df[ col]
df[ [ col1, col2] ]
s. iloc[ 0 ]
s. loc[ 'index_one' ]
df. iloc[ 0 , : ]
df. iloc[ 0 , 0 ]
df. columns = [ 'a' , 'b' , 'c' ]
pd. isnull( )
pd. notnull( )
df. dropna( )
df. dropna( axis= 1 )
df. dropna( axis= 1 , thresh= n)
df. fillna( x)
s. fillna( s. mean( ) )
s. astype( float )
s. replace( 1 , 'one' )
s. replace( [ 1 , 3 ] , [ 'one' , 'three' ] )
df. rename( columns= { 'old_name' : 'new_ name' } )
df. set_index( 'column_one' )
df. rename( index= lambda x: x + 1 )
df[ df[ col] & gt; 0.5 ]
df[ ( df[ col] & gt; 0.5 ) & ( df[ col] & lt; 0.7 ) ]
df. sort_values( col1)
df. sort_values( col2, ascending= False )
df. sort_values( [ col1, col2] , ascending= [ True , False ] )
df. groupby( col)
df. groupby( [ col1, col2] )
df. groupby( col1) [ col2]
df. pivot_table( index= col1, values= [ col2, col3] , aggfunc= mean)
df. groupby( col1) . agg( np. mean)
df. apply ( np. mean)
df. apply ( np. max , axis= 1 )
df1. append( df2)
pd. concat( [ df1, df2] , axis= 1 )
df1. join( df2, on= col1, how= 'inner' )
df. describe( )
df. mean( )
df. corr( )
df. count( )
df. max ( )
df. min ( )
df. median( )
df. std( )
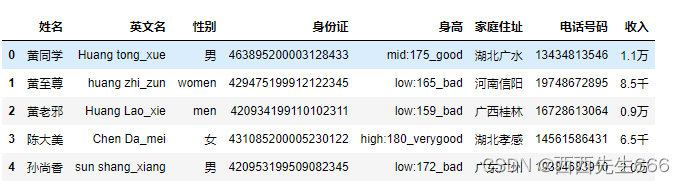
import pandas as pd
df = { '姓名' : [ ' 黄同学' , '黄至尊' , '黄老邪' , '陈大美' , '孙尚香' ] ,
'英文名' : [ 'Huang tong_xue' , 'huang zhi_zun' , 'Huang Lao_xie' , 'Chen Da_mei' , 'sun shang_xiang' ] ,
'性别' : [ '男' , 'women' , 'men' , '女' , '男' ] ,
'身份证' : [ '463895200003128433' , '429475199912122345' , '420934199110102311' , '431085200005230122' , '420953199509082345' ] ,
'身高' : [ 'mid:175_good' , 'low:165_bad' , 'low:159_bad' , 'high:180_verygood' , 'low:172_bad' ] ,
'家庭住址' : [ '湖北广水' , '河南信阳' , '广西桂林' , '湖北孝感' , '广东广州' ] ,
'电话号码' : [ '13434813546' , '19748672895' , '16728613064' , '14561586431' , '19384683910' ] ,
'收入' : [ '1.1万' , '8.5千' , '0.9万' , '6.5千' , '2.0万' ] }
df = pd. DataFrame( df)
df
df[ "姓名" ] . str . cat( df[ "家庭住址" ] , sep= '-' * 3 )
"""
0 黄同学---湖北广水
1 黄至尊---河南信阳
2 黄老邪 ---广西桂林
3 陈大美---湖北孝感
4 孙尚香---广东广州
Name: 姓名, dtype: object
"""
df[ "家庭住址" ] . str . contains( "广" )
"""
0 True
1 False
2 True
3 False
4 True
Name: 家庭住址, dtype: bool
"""
df[ "姓名" ] . str . startswith( "黄" )
"""
0 False
1 True
2 True
3 False
4 False
Name: 姓名, dtype: bool
"""
df[ "英文名" ] . str . endswith( "e" )
"""
0 True
1 False
2 True
3 False
4 False
Name: 英文名, dtype: bool
"""
df[ "电话号码" ] . str . count( "3" )
"""
0 3
1 0
2 1
3 1
4 2
Name: 电话号码, dtype: int64
"""
df[ "姓名" ] . str . get( - 1 )
"""
0 学
1 尊
2 邪
3 美
4 香
Name: 姓名, dtype: object
"""
df[ "身高" ] . str . split( ":" )
"""
0 [mid, 175_good]
1 [low, 165_bad]
2 [low, 159_bad]
3 [high, 180_verygood]
4 [low, 172_bad]
Name: 身高, dtype: object
"""
df[ "身高" ] . str . split( ":" ) . str . get( 0 )
"""
0 mid
1 low
2 low
3 high
4 low
Name: 身高, dtype: object
"""
df[ "性别" ] . str . len ( )
"""
0 1
1 5
2 3
3 1
4 1
Name: 性别, dtype: int64
"""
df[ "英文名" ] . str . upper( )
"""
0 HUANG TONG_XUE
1 HUANG ZHI_ZUN
2 HUANG LAO_XIE
3 CHEN DA_MEI
4 SUN SHANG_XIANG
Name: 英文名, dtype: object
"""
df[ "英文名" ] . str . lower( )
"""
0 huang tong_xue
1 huang zhi_zun
2 huang lao_xie
3 chen da_mei
4 sun shang_xiang
Name: 英文名, dtype: object
"""
df[ "家庭住址" ] . str . pad( 10 , fillchar= "*" )
"""
0 ******湖北广水
1 ******河南信阳
2 ******广西桂林
3 ******湖北孝感
4 ******广东广州
Name: 家庭住址, dtype: object
"""
df[ "家庭住址" ] . str . pad( 10 , side= "right" , fillchar= "*" )
"""
0 湖北广水******
1 河南信阳******
2 广西桂林******
3 湖北孝感******
4 广东广州******
Name: 家庭住址, dtype: object
"""
df[ "家庭住址" ] . str . center( 10 , fillchar= "*" )
"""
0 ***湖北广水***
1 ***河南信阳***
2 ***广西桂林***
3 ***湖北孝感***
4 ***广东广州***
Name: 家庭住址, dtype: object
"""
df[ "性别" ] . str . repeat( 3 )
"""
0 男男男
1 womenwomenwomen
2 menmenmen
3 女女女
4 男男男
Name: 性别, dtype: object
"""
df[ "电话号码" ] . str . slice_replace( 4 , 8 , "*" * 4 )
"""
0 1343****546
1 1974****895
2 1672****064
3 1456****431
4 1938****910
Name: 电话号码, dtype: object
"""
df[ "身高" ] . str . replace( ":" , "-" )
"""
0 mid-175_good
1 low-165_bad
2 low-159_bad
3 high-180_verygood
4 low-172_bad
Name: 身高, dtype: object
"""
df[ "收入" ] . str . replace( "\d+\.\d+" , "正则" )
"""
0 正则万
1 正则千
2 正则万
3 正则千
4 正则万
Name: 收入, dtype: object
"""
df[ "身高" ] . str . split( ":" )
"""
0 [mid, 175_good]
1 [low, 165_bad]
2 [low, 159_bad]
3 [high, 180_verygood]
4 [low, 172_bad]
Name: 身高, dtype: object
"""
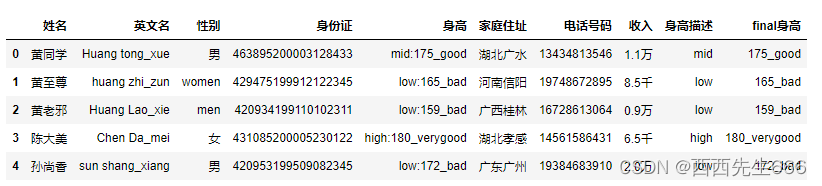
df[ [ "身高描述" , "final身高" ] ] = df[ "身高" ] . str . split( ":" , expand= True )
df
df[ "身高" ] . str . split( ":" ) . str . join( "?" * 5 )
"""
0 mid?????175_good
1 low?????165_bad
2 low?????159_bad
3 high?????180_verygood
4 low?????172_bad
Name: 身高, dtype: object
"""
df[ "姓名" ] . str . len ( )
df[ "姓名" ] = df[ "姓名" ] . str . strip( )
df[ "姓名" ] . str . len ( )
df[ "身高" ]
"""
0 mid:175_good
1 low:165_bad
2 low:159_bad
3 high:180_verygood
4 low:172_bad
Name: 身高, dtype: object
"""
df[ "身高" ] . str . findall( "[a-zA-Z]+" )
"""
0 [mid, good]
1 [low, bad]
2 [low, bad]
3 [high, verygood]
4 [low, bad]
Name: 身高, dtype: object
"""
1.10.15 接受正则表达式,抽取匹配的字符串(一定要加上括号)(extract/extractall函数)
df[ "身高" ] . str . extract( "([a-zA-Z]+)" )
"""
0
0 mid
1 low
2 low
3 high
4 low
"""
df[ "身高" ] . str . extractall( "([a-zA-Z]+)" )
"""
0
match
0 0 mid
1 good
1 0 low
1 bad
2 0 low
1 bad
3 0 high
1 verygood
4 0 low
1 bad
"""
df[ "身高" ] . str . extract( "([a-zA-Z]+).*?([a-zA-Z]+)" , expand= True )
"""
0 1
0 mid good
1 low bad
2 low bad
3 high verygood
4 low bad
"""


























 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









