









 本文详细解析了ConcurrentHashMap的内部结构与并发写操作机制,包括HashEntry与Segment的作用,以及1.7与1.8版本的区别。ConcurrentHashMap通过锁分段技术实现了高效的并发性能,允许多个线程同时进行读写操作。
本文详细解析了ConcurrentHashMap的内部结构与并发写操作机制,包括HashEntry与Segment的作用,以及1.7与1.8版本的区别。ConcurrentHashMap通过锁分段技术实现了高效的并发性能,允许多个线程同时进行读写操作。
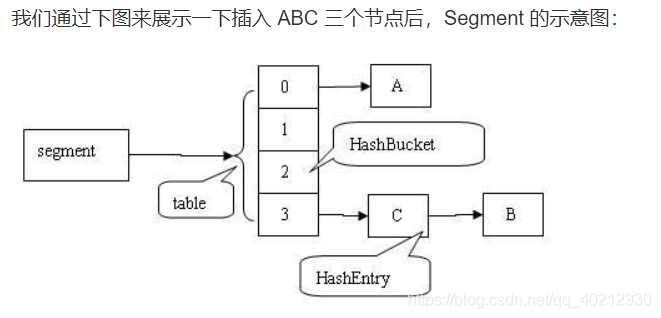
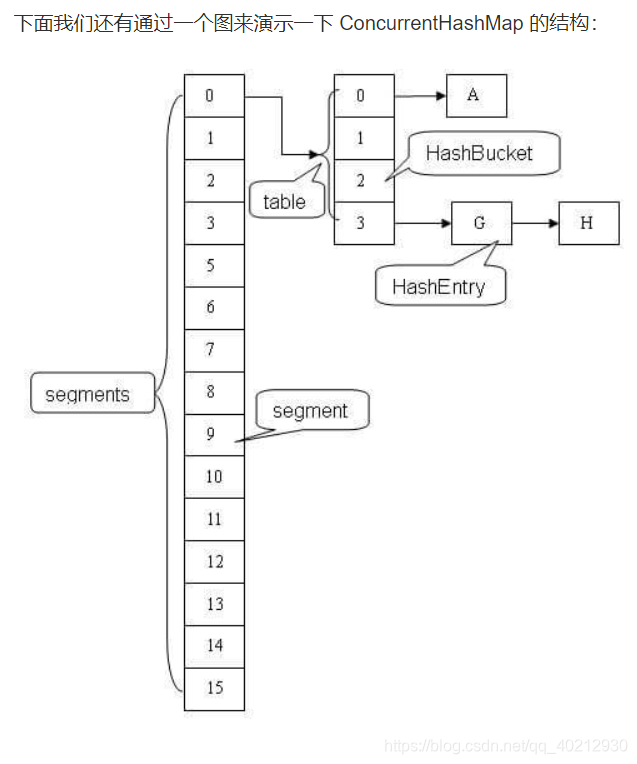
ConcurrentHashMap 类中包含两个静态内部类 HashEntry 和 Segment。HashEntry 用来封装映射表的键 / 值对;Segment 用来充当锁的角色,每个 Segment 对象守护整个散列映射表的若干个桶。每个桶是由若干个 HashEntry 对象链接起来的链表。一个 ConcurrentHashMap 实例中包含由若干个 Segment 对象组成的数组。HashEntry 用来封装散列映射表中的键值对。在 HashEntry 类中,key,hash 和 next 域都被声明为 final 型,value 域被声明为 volatile 型。
static final class HashEntry<K,V> {
final K key; // 声明 key 为 final 型
final int hash; // 声明 hash 值为 final 型
volatile V value; // 声明 value 为 volatile 型
final HashEntry<K,V> next; // 声明 next 为 final 型
并发写操作
/**
* Maps the specified key to the specified value in this table.
* Neither the key nor the value can be null.
*
* <p> The value can be retrieved by calling the <tt>get</tt> method
* with a key that is equal to the original key.
*
* @param key key with which the specified value is to be associated
* @param value value to be associated with the specified key
* @return the previous value associated with <tt>key</tt>, or
* <tt>null</tt> if there was no mapping for <tt>key</tt>
* @throws NullPointerException if the specified key or value is null
*/
@SuppressWarnings("unchecked")
public V put(K key, V value) {
Segment<K,V> s;
if (value == null)
throw new NullPointerException();
int hash = hash(key);
int j = (hash >>> segmentShift) & segmentMask;
if ((s = (Segment<K,V>)UNSAFE.getObject // nonvolatile; recheck
(segments, (j << SSHIFT) + SBASE)) == null) // in ensureSegment
s = ensureSegment(j);
return s.put(key, hash, value, false);
}
我们通过注释可以了解到,ConcurrentHashMap 不允许空值。该方法首先有一个 Segment 的引用 s,然后会通过 hash() 方法对 key 进行计算,得到哈希值;继而通过调用 Segment 的 put(K key, int hash, V value, boolean onlyIfAbsent)方法进行存储操作。该方法源码为
final V put(K key, int hash, V value, boolean onlyIfAbsent) {
//加锁,这里是锁定的Segment而不是整个ConcurrentHashMap
HashEntry<K,V> node = tryLock() ? null :scanAndLockForPut(key, hash, value);
V oldValue;
try {
HashEntry<K,V>[] tab = table;
//得到hash对应的table中的索引index
int index = (tab.length - 1) & hash;
//找到hash对应的是具体的哪个桶,也就是哪个HashEntry链表
HashEntry<K,V> first = entryAt(tab, index);
for (HashEntry<K,V> e = first;;) {
if (e != null) {
K k;
if ((k = e.key) == key ||
(e.hash == hash && key.equals(k))) {
oldValue = e.value;
if (!onlyIfAbsent) {
e.value = value;
++modCount;
}
break;
}
e = e.next;
}
else {
if (node != null)
node.setNext(first);
else
node = new HashEntry<K,V>(hash, key, value, first);
int c = count + 1;
if (c > threshold && tab.length < MAXIMUM_CAPACITY)
rehash(node);
else
setEntryAt(tab, index, node);
++modCount;
count = c;
oldValue = null;
break;
}
}
} finally {
//解锁
unlock();
}
return oldValue;
}
需要注意的是:加锁操作是针对的 hash 值对应的某个 Segment,而不是整个 ConcurrentHashMap。因为 put 操作只是在这个 Segment 中完成,所以并不需要对整个 ConcurrentHashMap 加锁。所以,此时,其他的线程也可以对另外的 Segment 进行 put 操作,因为虽然该 Segment 被锁住了,但其他的 Segment 并没有加锁。同时,读线程并不会因为本线程的加锁而阻塞。
正是因为其内部的结构以及机制,所以 ConcurrentHashMap 在并发访问的性能上要比Hashtable和同步包装之后的HashMap的性能提高很多。在理想状态下,ConcurrentHashMap 可以支持 16 个线程执行并发写操作(如果并发级别设置为 16),及任意数量线程的读操作。
concurrenthashmap有什么优势以及1.7和1.8区别
Concurrenthashmap线程安全的,1.7是在jdk1.7中采用Segment + HashEntry的方式进行实现的,lock加在Segment上面。1.7size计算是先采用不加锁的方式,连续计算元素的个数,最多计算3次:1、如果前后两次计算结果相同,则说明计算出来的元素个数是准确的;2、如果前后两次计算结果都不同,则给每个Segment进行加锁,再计算一次元素的个数;
1.8中放弃了Segment臃肿的设计,取而代之的是采用Node + CAS + Synchronized来保证并发安全进行实现,1.8中使用一个volatile类型的变量baseCount记录元素的个数,当插入新数据或则删除数据时,会通过addCount()方法更新baseCount,通过累加baseCount和CounterCell数组中的数量,即可得到元素的总个数;
与hashtable 对比

门户:Portal


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









