






urllib库的应用:
import urllib.request
① urlretrieve()这个模块属于直接下载 网页到指定路径
用法:urlretrieve(网址,本地文件存储地址)
例子:
urllib.request.urlretrieve("http://www.baidu.com","D://python3文件//baidu.html")
在编辑器上可以打以下代码则直接下载(在指定的路径下能找到你所下载的网页)
from urllib import request
a = request.urlretrieve("http://www.baidu.com","D://python3文件//baidu.html")② info()属于查看网页的相关信息
例子:
from urllib import request
b=request.urlopen("https://read.douban.com/provider/all")
print(b.info())我们查看到的是豆瓣网址中的一些信息如下
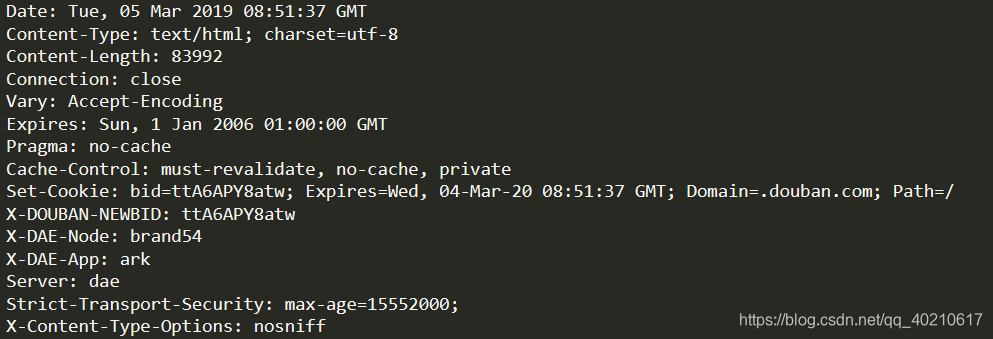
③getcode() :得到访问状态码,200为正常状态码,非200为非正常状态码
from urllib import request
b=request.urlopen("https://read.douban.com/provider/all")
print(b.getcode())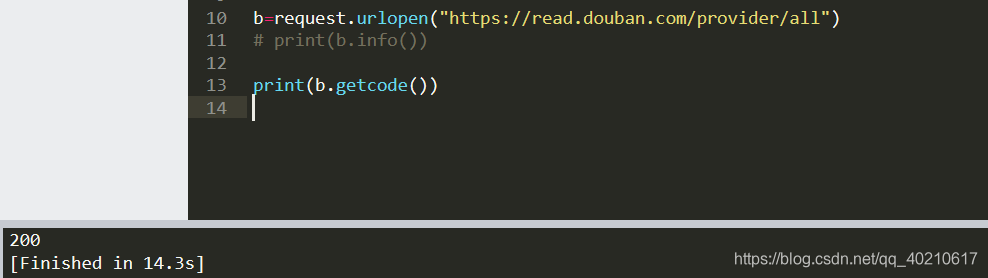
④geturl():获得现在所访问的url地址
from urllib import request
b=request.urlopen("https://read.douban.com/provider/all")
print(b.geturl())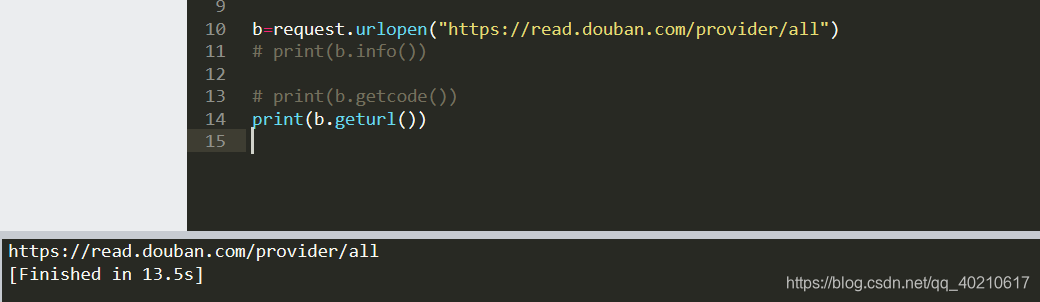
⑤urlcleanup() 清除缓存信息,没有报错执行说明已经清除

直接执行就行


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









