1. JDBC
Spark SQL可以通过JDBC从关系型数据库中读取数据的方式创建DataFrame,通过对DataFrame一系列的计算后,还可以将数据再写回关系型数据库中。
1.1. SparkSql 从MySQL中加载数据 1.1.1 通过IDEA编写SparkSql代码
执行查看效果:
1.1.2 通过spark-shell运行
(1)、启动spark-shell(必须指定mysql的连接驱动包)
[AppleScript] 纯文本查看 复制代码
?
01
02
03
04
05
06
07
08
09
10
11
spark-shell \
--master spark://hdp-node-01:7077 \
--executor-memory 1g \
--total-executor-cores 2 \
--jars /opt/bigdata/hive/lib/mysql-connector-java-5.1.35.jar \
--driver-class-path /opt/bigdata/hive/lib/mysql-connector-java-5.1.35.jar
(2)、从mysql中加载数据
[AppleScript] 纯文本查看 复制代码
?
1
val mysqlDF = spark.read.format("jdbc").options(Map("url" -> "jdbc:mysql://192.168.200.150:3306/spark", "driver" -> "com.mysql.jdbc.Driver", "dbtable" -> "iplocation", "user" -> "root", "password" -> "123456")).load()
(3)、执行查询
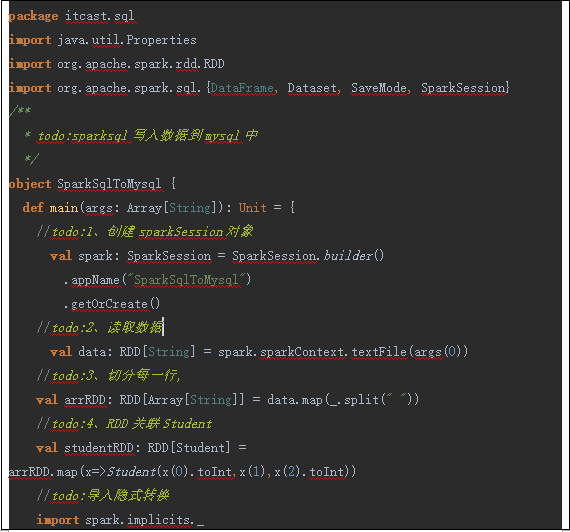
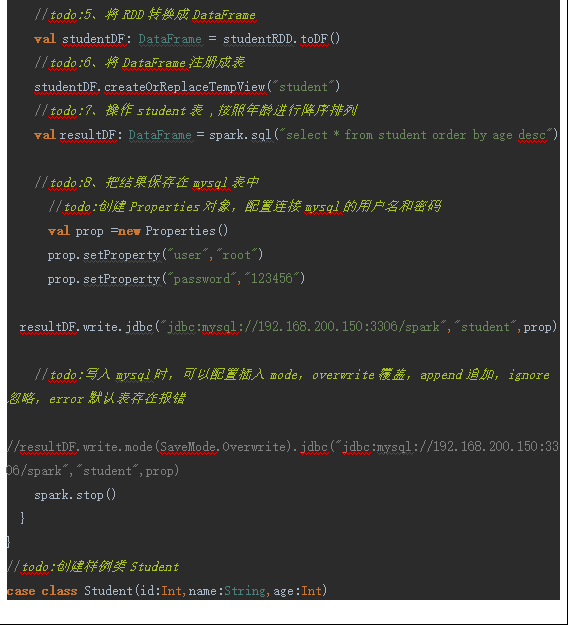
1.2. SparkSql 将数据写入到MySQL中 1.2.1 通过IDEA编写SparkSql代码
(1)编写代码
(2)用maven将程序打包
通过IDEA工具打包即可
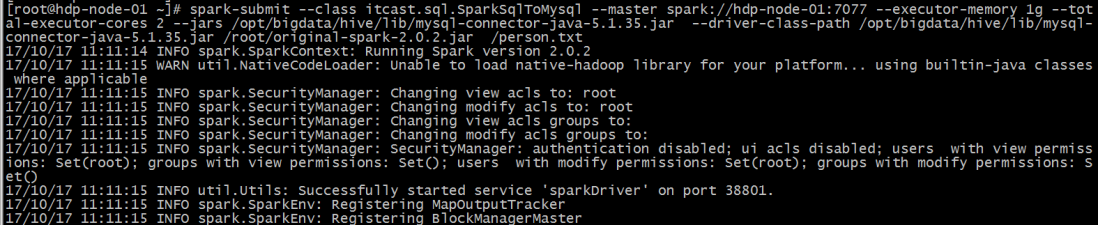
(3)将Jar包提交到spark集群
[AppleScript] 纯文本查看 复制代码
?
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
spark-submit \
--class itcast.sql.SparkSqlToMysql \
--master spark://hdp-node-01:7077 \
--executor-memory 1g \
--total-executor-cores 2 \
--jars /opt/bigdata/hive/lib/mysql-connector-java-5.1.35.jar \
--driver-class-path /opt/bigdata/hive/lib/mysql-connector-java-5.1.35.jar \
/root/original-spark-2.0.2.jar /person.txt
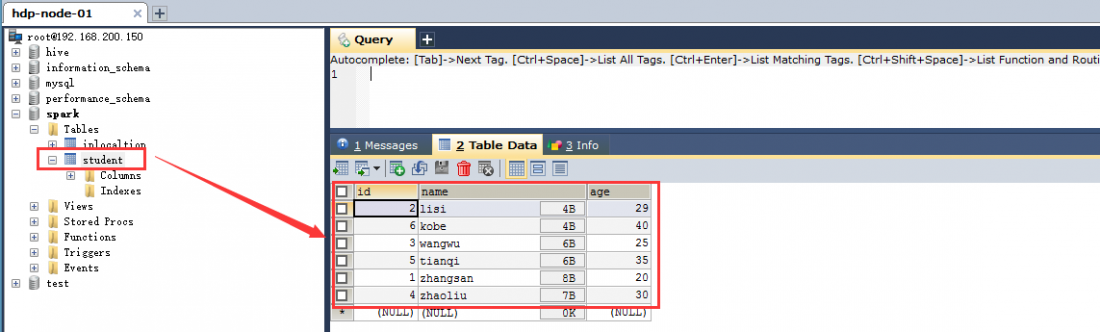
(4)查看mysql中表的数据





 本文介绍了如何使用Spark SQL通过JDBC接口与MySQL进行数据交互。详细讲解了从MySQL加载数据到DataFrame,以及如何将DataFrame中的数据写回MySQL的过程,包括在IDEA中编写代码、spark-shell运行及打包提交到Spark集群的操作步骤。
本文介绍了如何使用Spark SQL通过JDBC接口与MySQL进行数据交互。详细讲解了从MySQL加载数据到DataFrame,以及如何将DataFrame中的数据写回MySQL的过程,包括在IDEA中编写代码、spark-shell运行及打包提交到Spark集群的操作步骤。





















 1224
1224

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









