






 本文介绍了一种使用Node.js抓取网易新闻、网易体育及新浪网体育新闻的方法,涵盖从请求网页、解析HTML、转码、提取新闻详情到存储至MySQL数据库的全过程。
本文介绍了一种使用Node.js抓取网易新闻、网易体育及新浪网体育新闻的方法,涵盖从请求网页、解析HTML、转码、提取新闻详情到存储至MySQL数据库的全过程。
!!!ps: 因为最近一段时间都在忙毕业论文(5.6提交),所以博客方面并没有持续更新,是最后做完一块更新的
首先,先介绍一下,基本的爬虫部分:这次我主要爬了 网易新闻、网易体育、新浪网体育三个网站
(1)引入相关配置文件(具体见注释)
//引入相关配置文件
var cheerio = require('cheerio') //用于解析html界面
var rp = require('request-promise') //用于发送请求
var iconv = require('iconv-lite'); //用于转码,防止乱码
var mysql = require('./mysql.js'); //用于连接本地数据库
出现查询不到的,打开cmd用npm install ...来安装
(2)请求一级页面(暂时以“网易体育”为例子)
观察页面,发现新闻头条都在div.topnews里面
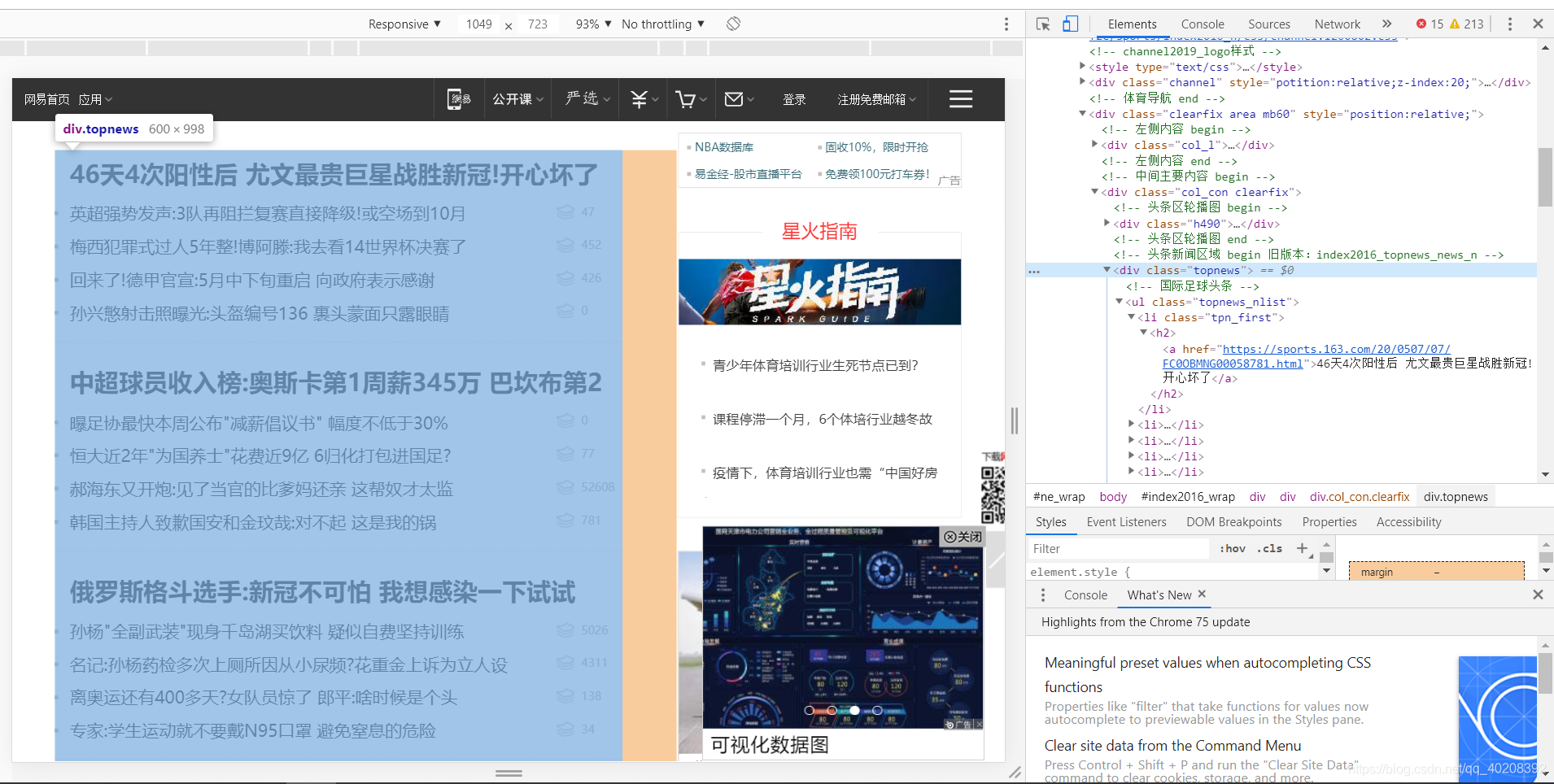
于是我们就去解析 div.topnews这个版块,找到里面的新闻链接:
var options = {
uri: 'https://sports.163.com/',
encoding: null,
transform: function (body) {
body = iconv.decode(body, 'gbk');
return cheerio.load(body);
}
}
rp(options).then(function ($) { //链接一级页面
var newsArr = [];
var item = $('.topnews','div').find('li');
item.map(function (idx, element) {
console.log("here1");
var news = {};
news.link = $(element).find('a').attr('href');
console.log(news.link);
getTexts(newsArr, news, function(newsArr, news) { //链接二级页面
});
})
})
(3)请求二级页面(具体爬取新闻标题、内容、时间)
网易体育:
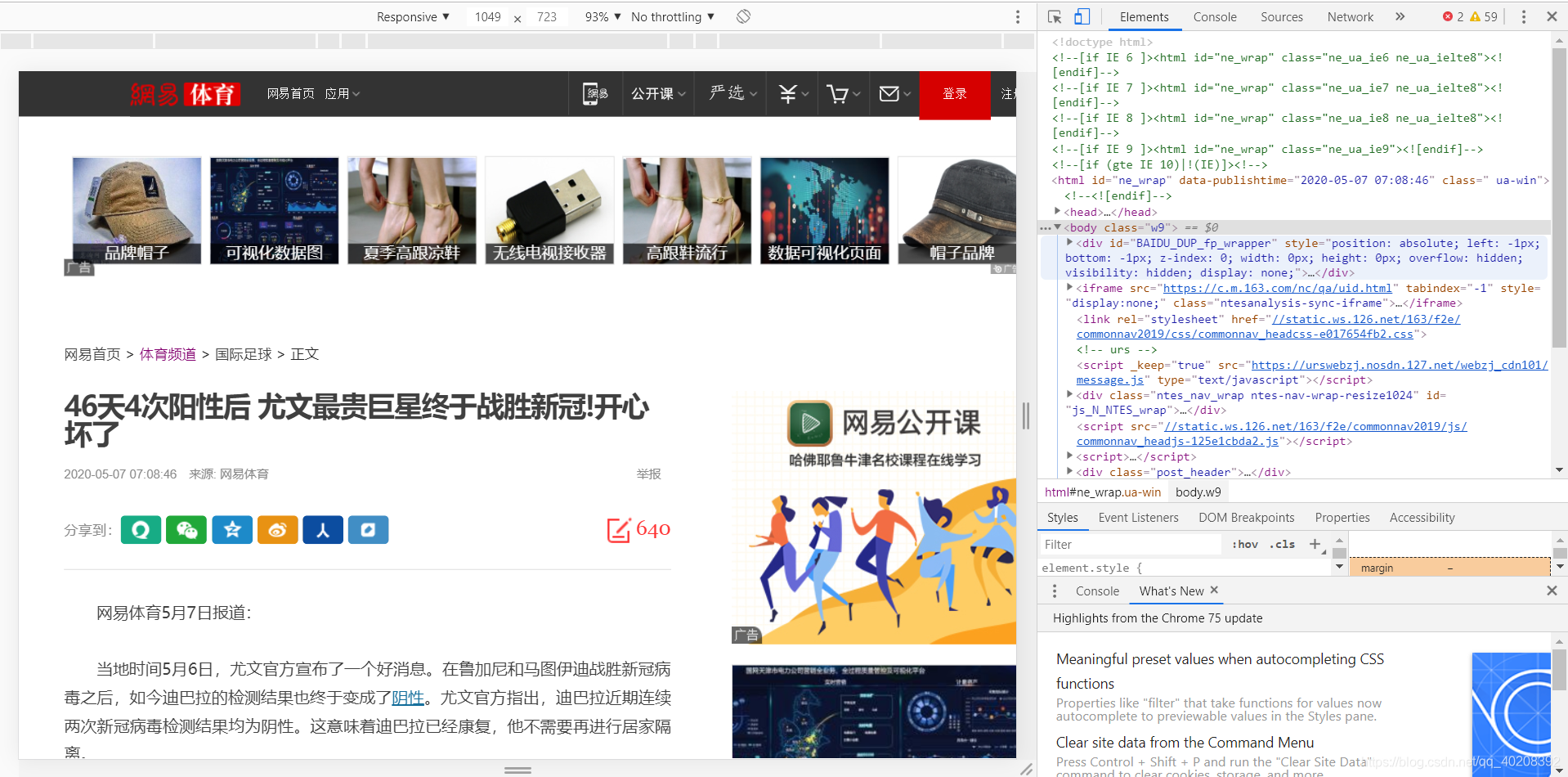
//获得二级目录信息
function getTexts(newsArr, news, callback) {
var options = {
uri: news.link,
encoding: null,
transform: function (body) {
body = iconv.decode(body, 'gbk');
return cheerio.load(body);
}
}
rp(options).then(function ($) {
//标题
news.title = $('#epContentLeft').children('h1').first().text();
//时间
news.time = $('#ne_wrap').attr("data-publishtime");
console.log(news.time);
var item = $('.post_content_main', 'div');
//编辑者
news.editor = item.find('.ep-editor', 'span').text();
news.source = item.find('.post_time_source', 'div').children('a').first().text();
news.comment = item.find('.post_cnum_tie', 'a').text();
var maintext = '';
$('.post_text', 'div').children('p').each(function (idx, element) {
maintext = maintext.concat($(element).text()).replace(/\s*/g, '');
})
news['texts'] = maintext;
console.log(news.title);
console.log(news.editor);
})
网易新闻:
//获得二级目录信息
function getTexts(newsArr, news, callback) {
var options = {
uri: news.link,
encoding: null,
transform: function (body) {
body = iconv.decode(body, 'gbk');
return cheerio.load(body);
}
}
rp(options).then(function ($) {
//标题
news.title = $('#epContentLeft').children('h1').first().text();
//时间
news.time = $('#ne_wrap').attr("data-publishtime");
console.log(news.time);
var item = $('.post_content_main', 'div');
//编辑者
news.editor = item.find('.ep-editor', 'span').text();
news.source = item.find('.post_time_source', 'div').children('a').first().text();
news.comment = item.find('.post_cnum_tie', 'a').text();
var maintext = '';
$('.post_text', 'div').children('p').each(function (idx, element) {
maintext = maintext.concat($(element).text()).replace(/\s*/g, '');
})
news['texts'] = maintext;
console.log(news.title);
console.log(news.editor);
})
新浪网体育:
var arrData=[]; //用于保存每篇新闻的href,title,time,source,id
$2('div').each(function(){
var arrTime = [];
$2('span').each(function(){ //直接通过span标签,获得所有新闻的time,并先存放进arrTime数组
var atime=$2(this).text();
arrTime.push(atime);
})
var index=0;
var id=$2(this).attr("id");
$2('#'+id+' a').each(function(){ //遍历每篇新闻
var ahref=$2(this).attr("href"); //获取新闻href
var atitle=$2(this).text(); //获取新闻title
var a=ahref.split('/');
var aid=a[a.length-1];
var num= aid.replace(/[^0-9]/ig,""); //从href中截取新闻id
var insertItem="['"+ahref+"','"+atitle+"','"+arrTime[index++]+"','新浪网体育','','"+num+"']"; //得到每条新闻的href,title,time,source,id
arrData.push(insertItem);
})
})
(4)存储到本地MySQL(以网易体育为例)
先要在本地下载好MySQL,然后建库,建表(在此省略)
本地MySQL相关配置
var mysql = require("mysql");
var pool = mysql.createPool({
host: '127.0.0.1',
user: 'root',
password: '12345678',
database: '前端设计case'
});
接口配置:
var query = function(sql, sqlparam, callback) {
pool.getConnection(function(err, conn) {
if (err) {
callback(err, null, null);
} else {
conn.query(sql, sqlparam, function(qerr, vals, fields) {
conn.release(); //释放连接
callback(qerr, vals, fields); //事件驱动回调
});
}
});
};
var query_noparam = function(sql, callback) {
pool.getConnection(function(err, conn) {
if (err) {
callback(err, null, null);
} else {
conn.query(sql, function(qerr, vals, fields) {
conn.release(); //释放连接
callback(qerr, vals, fields); //事件驱动回调
});
}
});
};
exports.query = query;
exports.query_noparam = query_noparam;
(5)把爬虫结果存到本地
var newsAddSql = 'INSERT INTO sina(href,title,time,source,author,articid) VALUES(?,?,?,?,?,?)';
//SQL语句
news.crawltime = new Date();
var newsAddSql_Params = [news.link, news.title, news.time, '网易体育', news.editor, num];
//爬虫爬下来的数据,用来存入SQL语句的‘?’中
mysql.query(newsAddSql, newsAddSql_Params, function(qerr, vals, fields) {
if (qerr) {
console.log(qerr);
}
});
//调用mysql.js中的函数,存入数据库中
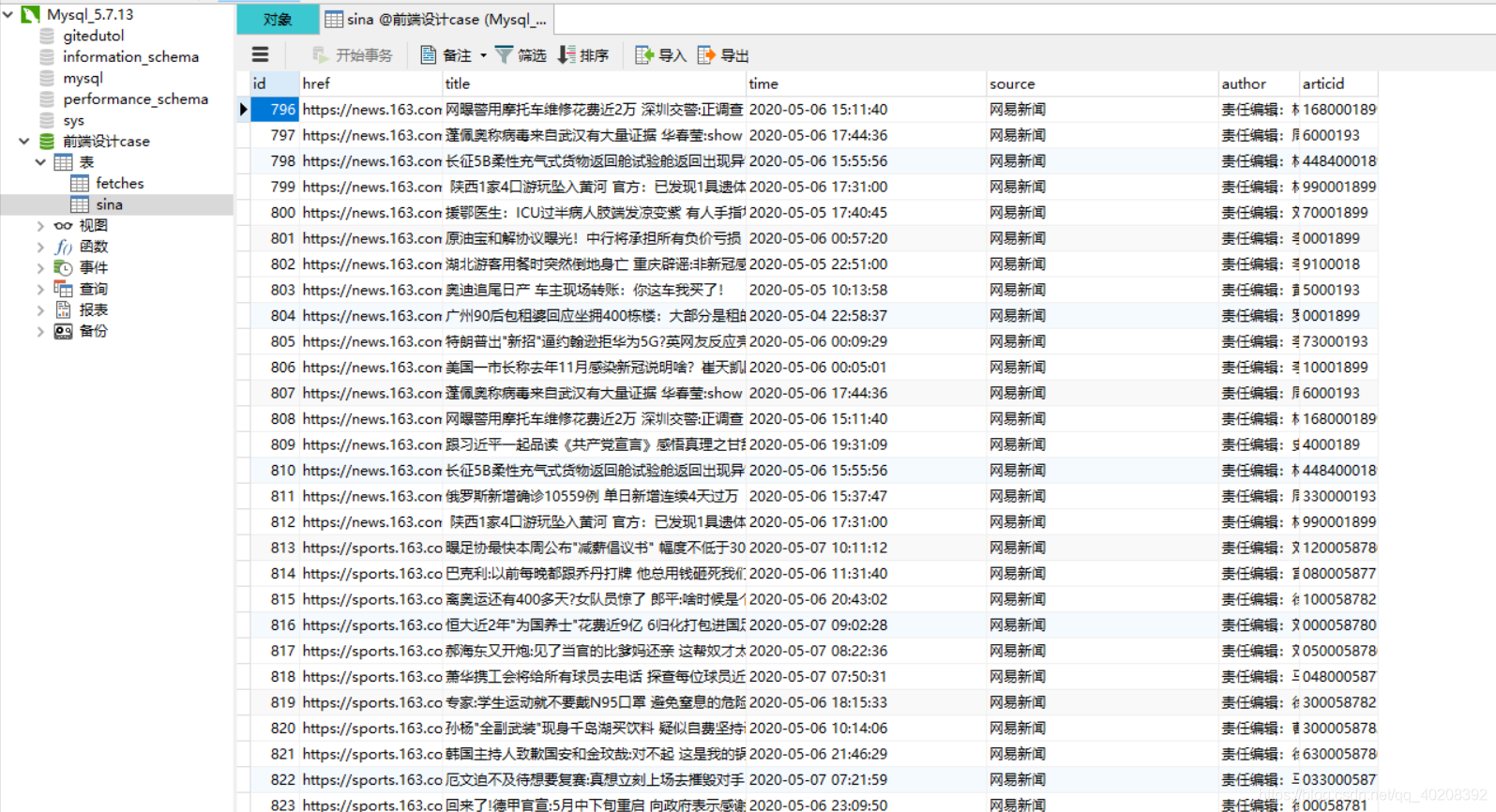
(6)数据库结果截图
(用Navicat显示的)

















 855
855

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









