







内核中的链表
Linux内核中使用的链表方式可谓是独树一帜,它将各个结构体链接在一起并不是将数据结构塞入链表,而是将链表节点塞入数据结构!
如普通的链表结构:
struct fox {
long tail_length;
long weight;
struct fox *nex;
struct fox *prev;
};
上面这种双链表结构是最常见的结构,是直接将fox结构放入链表中。
而Linux内核使用的是如下方式:
struct list_head {
struct list_head *next;
struct list_head *prev;
}
struct fox {
long tail_length;
long weight;
struct list_head list;
}
与传统方式不同,Linux使用的是将链表放入结构中。
有了Linux这种结构就可以直接将带有list_head结构的结构体链在一起,可以有如下结构:
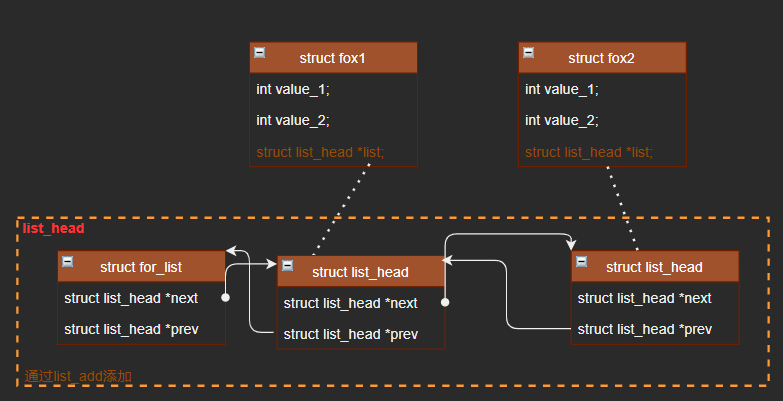
有了如上结构,那么就可以轻松将结构链接起来,直接将结构体里面的list成员传入到list_add函数即可,实现如下:
static __inline__ void __list_add(struct list_head *new,
struct list_head *prev,
struct list_head *next)
{
next->prev = new;
new->next = next;
new->prev = prev;
prev->next = new;
}
现在链接起来的是list_head类型的结构,但是我们要获取的是包含list_head成员的fox结构,那该怎么获取呢?
由于C语言中,一个给定的结构中变量偏移时的地址被ABI固定下来了,所以我们可以根据地址偏移来找到fox结构,Linux中是使用宏list_entry()来实现这种方法的,代码如下:
/**
* list_entry - get the struct for this entry
* @ptr: the &struct list_head pointer.
* @type: the type of the struct this is embedded in.
* @member: the name of the list_struct within the struct.
*/
#define list_entry(ptr, type, member) \
((type *)((char *)(ptr)-(unsigned long)(&((type *)0)->member)))
依靠list_entry()方法,内核提供了创建、操作以及其他链表管理的各种例程,所有这些方法都不需要知道list_head所嵌入对象的数据结构。
而且我们可以从任何一个节点起遍历整个链表,直到我们看到所有节点。
遍历链表有以下几种方法:
- 最基本的方法:使用
list_for_each()宏。- 比较灵活的:使用
list_for_each_entry()宏。- 反向遍历链表:
list_for_each_entry_reverse()宏。- 遍历的同时删除:
list_for_each_entry_safe()宏。
其中常用的是:
/**
* list_for_each_entry - iterate over list of given type
* @pos: the type * to use as a loop cursor.
* @head: the head for your list.
* @member: the name of the list_struct within the struct.
*/
#define list_for_each_entry(pos, head, member) \
for (pos = list_entry((head)->next, typeof(*pos), member); \
prefetch(pos->member.next), &pos->member != (head); \
pos = list_entry(pos->member.next, typeof(*pos), member))
这种方法使用的是遍历list_head链表中所有的成员,然后找到指定的head则返回。
内核中的队列
队列一般用于生产者和消费者模型,即通过队列实现消息的存放和提取。
Linux内核使用的是叫做kfifo的队列,和多数队列相似,提供了两个主要操作:enqueue(入队列)和dequeue(出队列)。kfifo对象维护了两个偏移量:入口偏移和出口偏移。
入口偏移:指下一次入队列时的位置。
出口偏移:下一次出队列的位置。
队列空:出口偏移等于入口偏移。
队列满:入口偏移等于队列长度。
红黑树
Linux主要的平衡二叉树数据结构就是红黑树。
红黑树能维持半平衡结构,遵循以下六个属性:
(1). 所有叶子节点只能是红色或者时黑色。
(2). 叶子节点都是黑色。
(3). 叶子节点不包含数据
(4). 所有非叶子节点都有两个子节点
(5). 如果一个节点是红色,则它的子节点都是黑色
(6). 在一个节点到其叶子节点的路径中,如果总是包含同样数目的黑色节点,则该路径相比其他路径是最短的。
通过以上特性,保证了最深的叶子节点的深度不会大于两倍的最浅叶子节点的深度,所以红黑树总是半平衡的。
数据结构的选择:
队列:符合生产者/消费者模型。
映射:需要映射一个UID到一个对象。
红黑树:需要存储大量数据,并且检索迅速。检索快,但是耗内存。
链表:不需要执行太多次紧迫的查找操作。
内核除了以上数据结构外,还有其他数据结构,比如映射、基树和位图等。
总结:
平时写代码时,尽量在已经存在的数据结构基础上拓展,很多时候不必重复造轮子,我们可以参考已有的数据结构,找到符合我们需要场景即可。

















 902
902

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









