






Redis 应用场景
问:你的项目中 redis 的应用场景有哪些?
此问题一是先验证你项目的真实性,二是作为深入提问的切入点,根据你的回答进行深入提问。
答:
- 作为数据缓存使用。延伸问题:(缓存穿透、雪崩、击穿,持久化机制,过期策略,淘汰策略,双写一致
- 分布式锁。延伸问题:setnx、redission
- 消息队列、延迟队列。延伸问题:redis的数据类型和选择方案
问:redis是单线程的,为什么还那么快?
答:redis是C语言编写的纯内存操作软件,采用IO多路复用模型,非阻塞IO,执行速度非常快。
Redis 缓存穿透
问:在用 redis 的过程中,会引发那些问题?请详细说明。
答:会引发 缓存穿透,缓存雪崩,缓存击穿等问题。
缓存穿透
在正常的处理逻辑中,当查询请求到系统时,会先根据请求key来查询 redis 中是否缓存有该数据。
若有,则直接从 redis 中返回该数据,不用通过数据库查询,从而减轻数据库压力。
若无,则从数据库中查询,并将查询结果按照请求key存入 redis 中。当下次同样的请求过来时,可以通过redis返回数据。
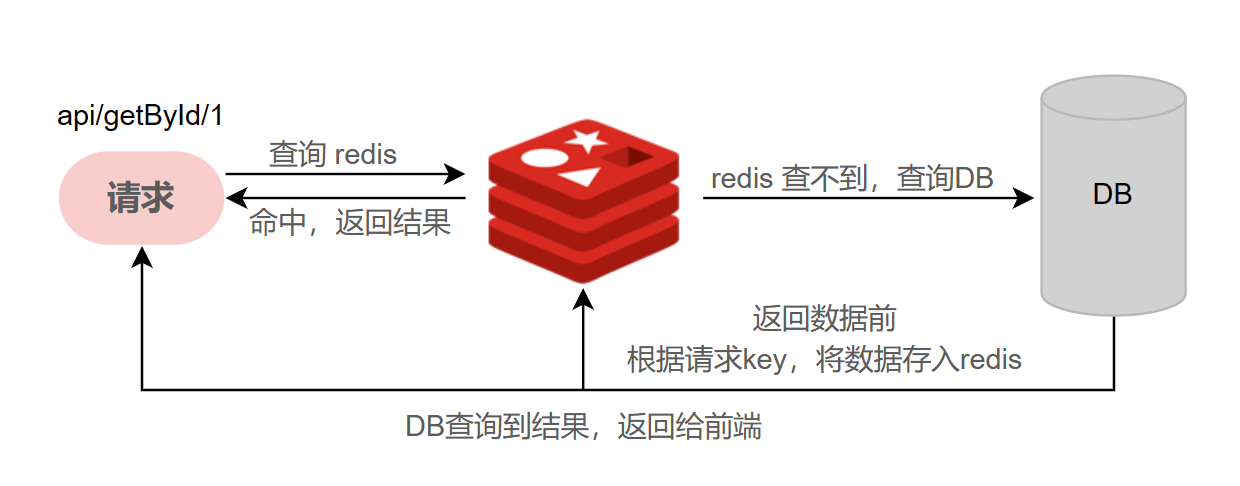
缓存穿透是 当查询一个不存在的数据时,数据库中查询不到数据,也就不会缓存到redis中。每次请求都会查询数据库,当请求过多时,造成数据库压力过大,会造成数据库宕机,从而是系统崩溃。
解决方案
-
缓存空数据。当查询的结果为空时,仍把空数据根据请求key缓存到 redis 中,下次便不会查询数据库
优点:简单直接。缺点:耗费内存,可能会发生数据不一致。
-
使用布隆过滤器。在查询 redis 之前,先查询布隆过滤器,若不存在直接返回。
优点:内存占用少,没有多余key。缺点:实现过于复杂,存在误判。
Redis 缓存雪崩
问:什么是redis雪崩?
答:当大量的key在同一时间失效或者redis服务宕机,导致大量的请求到达数据库,数据库压力过大导致宕机。
解决方案
- 给不同的key设置不同的过期时间。
- 搭建 redis 集群,提高服务可用性。
- 给缓存业务添加降级限流策略。
- 给业务添加多级缓存。Guava、Caffeine
Redis 缓存击穿
问:什么是缓存击穿?
答:当某个热点key在缓存中过期而且还没有在缓存中构建好新的缓存,恰好此时有多个并发请求这个热点key,从而导致多个线程请求数据库查询,从而导致数据库压力过大而宕机。
解决方案
通常根据业务场景进行方案选择。
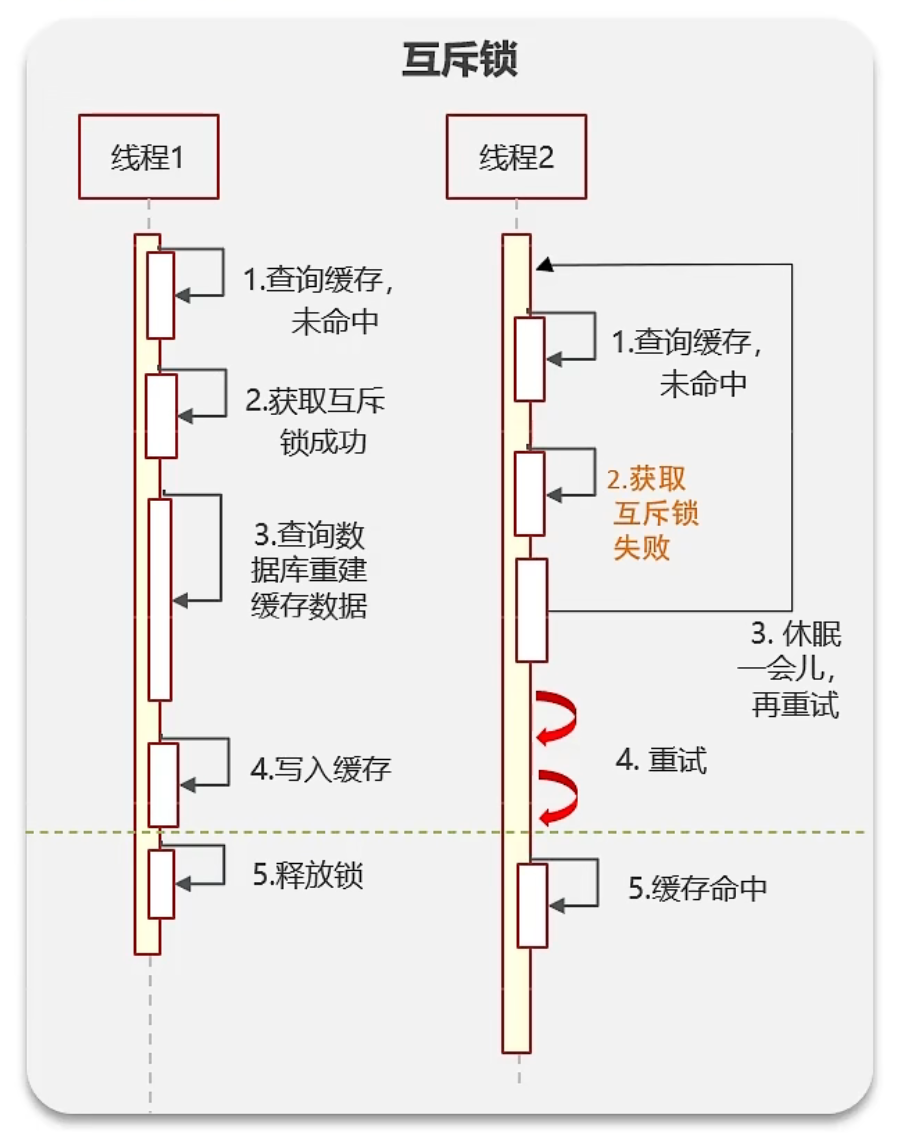
-
互斥锁。优点:数据强一致性。缺点:性能低下,用户体验不好。
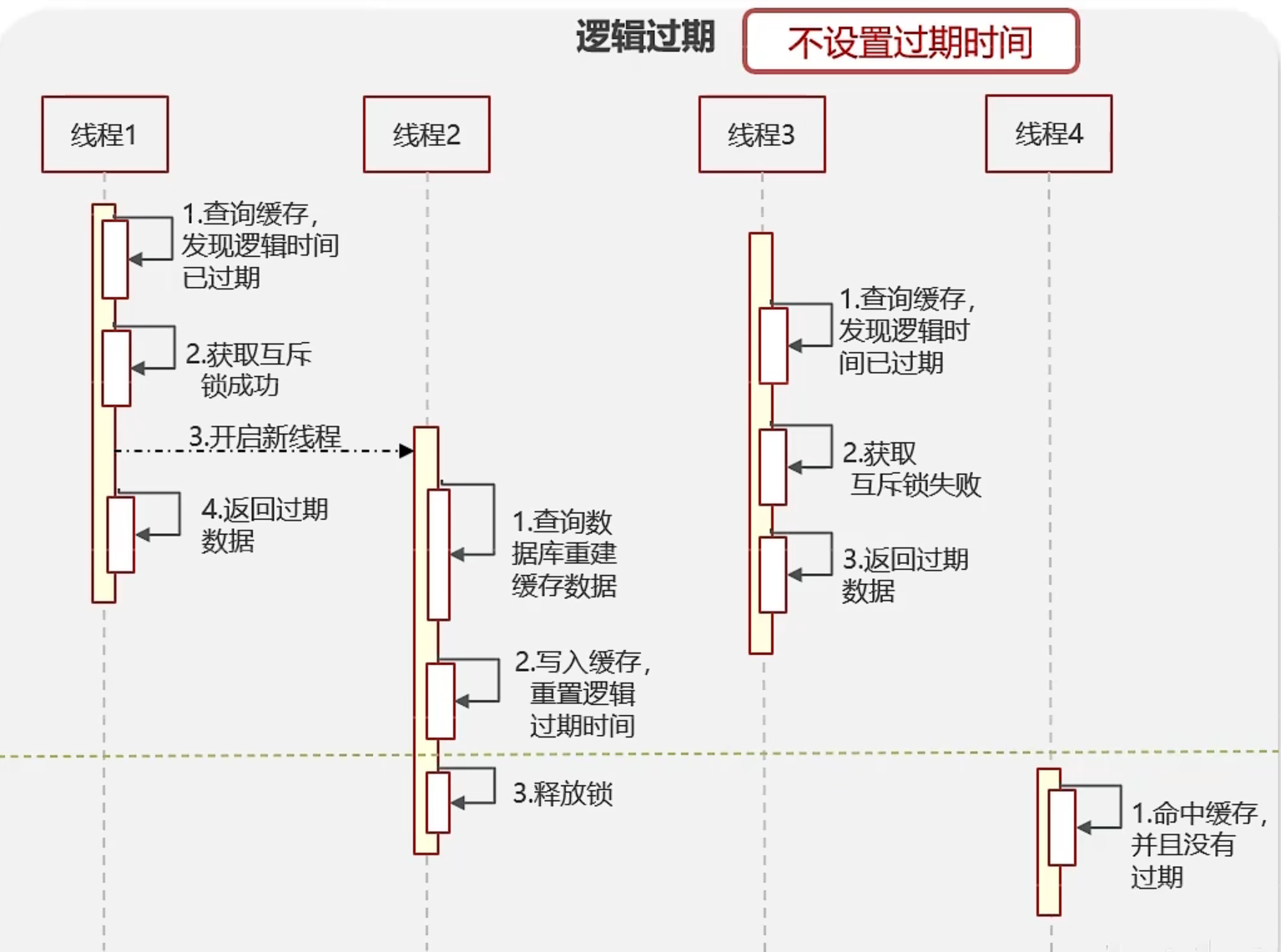
-
逻辑过期。优点:性能高,用户体验好。缺点:数据不一致。
Redis 持久化
Redis持久化机制主要有两种,RDB和AOF。
RDB(Redis Database Backup File)
RDB全称 redis数据备份文件。就是把redis中的数据以二进制的形式记录到磁盘中。当 redis 宕机重启后,从磁盘中读取备份文件,恢复数据。
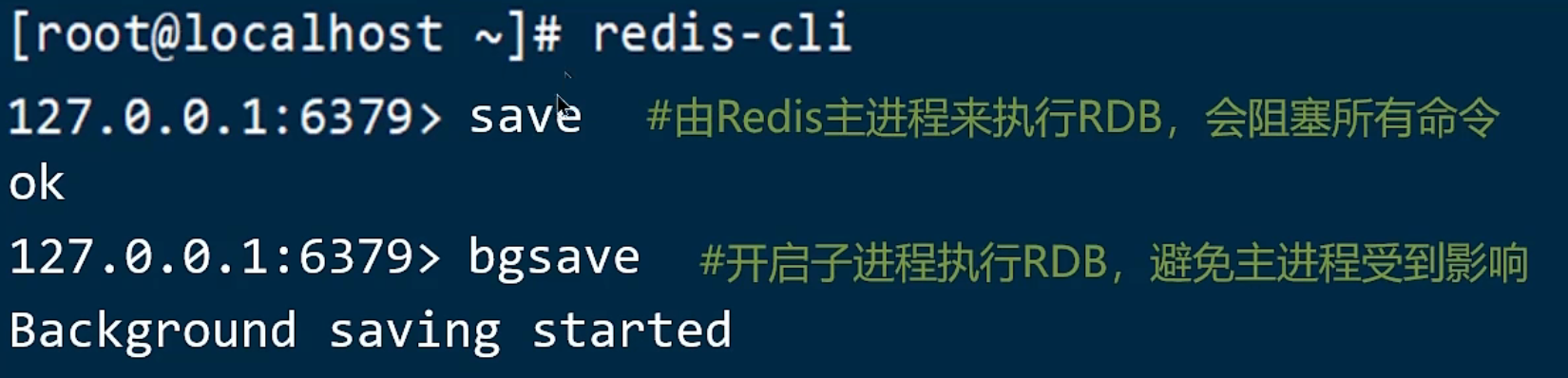
RDB相关命令
save 和 bgsave,在手动备份的情况下,一般使用bgsave命令来备份,避免阻塞。
bgsave会开启一个子进程来完成备份操作,所以不会阻塞。
RDB配置
Redis内部有触发 RDB 的机制,可以在 redis.conf 文件中配置 RDB 的备份规则。
(注意:配置文件触发的RDB命令为 bgsave)

[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-b10r3X5A-1681975557372)(C:\Users\JamesLau\AppData\Roaming\Typora\typora-user-images\image-20230419172152001.png)]
AOF(Append Only File)
AOF全程追加文件,redis处理的每一个写命令都会记录在 aof 文件中,可以看作是命令日志文件。aop默认是关闭的,需要修改redis.conf 文件来开启。


aof的命令记录频率也是通过 redis.conf 来配置的。
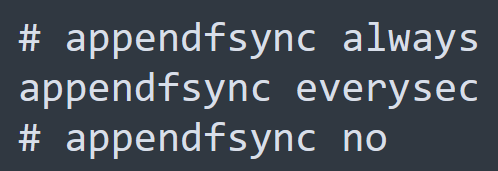


因为是记录命令,所以aof 可能会记录些无效命令,例如同一个key的多次写操作,只有最后一次的写操作才有意义,所以客户端可以通过 BGREWRITEAOF 命令让 aof 文件执行重写功能,用最少的命令达到相同的效果。

也可以在 redis.conf 中配置触发阈值来执行 aof 文件去重操作。

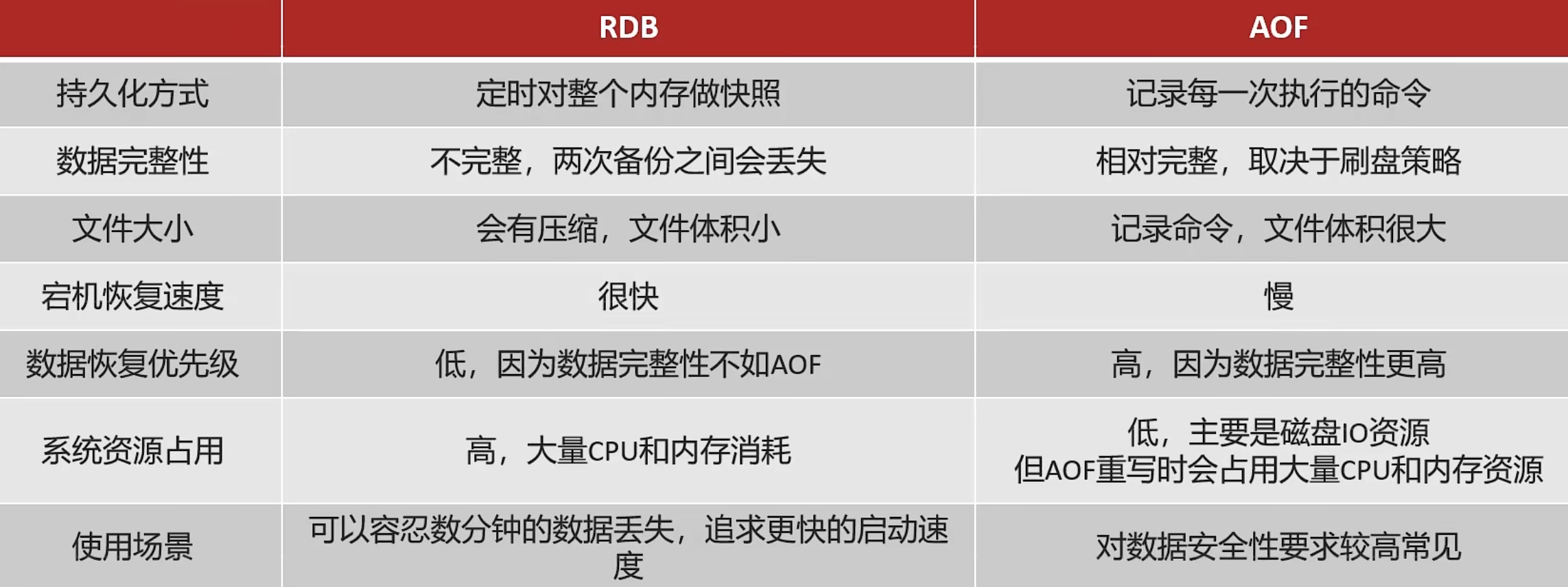
AOF 和 RDB 对比
AOF和RDB都有各自的应用场景,在实际开发中往往会结合两种方式混合使用。
Redis 数据删除策略
问:redis的key过期后,数据会立即删除吗?
答:不会,redis的数据删除策略分为两种,惰性删除和定时删除。通常两种策略一起使用。
惰性删除
当查询某个key的时候,先检查是否过期,若过期了,就执行删除。若没过期,则返回该key数据。
-
优点:对cpu友好,只在使用该key的时候执行过期检查,对很多过期key不必浪费时间进行过期检查和删除。
-
缺点:对内存不友好,若一个key已经过期且一直没有查询使用,则该key会一直存在内存中,造成内存占用。
定时删除
每隔一段时间,就会对一些key进行过期检查,删除里面的过期key。(每次检查一定量的key)
定时清理的两种方式:
-
SLOW模式。redis服务会在初始化函数 initServer()中设置定时任务,执行频率默认10HZ(每秒10次)默认slow模式每次耗时不超过25ms,可以通过修改配置文件来调整执行次数。

-
FAST模式。Redis的每个事件循环前会调用beforeSleep()函数执行过期key清理。执行频率不固定,但每两次间隔不低于2ms,每次耗时不超过1ms。
-
优点:定时删除可以有效释放内存空间。
-
缺点:难以确定删除执行操作的时长。
实际开发中,通常两种策略一起配合使用。
Redis 数据淘汰策略
问:假如缓存过多,内存被占满了怎么办?
答:默认情况下,会报错。但是我们可以修改redis的数据淘汰策略来根据场景清理一部分key来继续使用。
数据淘汰策略:当 redis 中的内存不够用时,再向redis中添加新的key时,redis就会按照一定规则来将内存中的数据删除掉。这种删除规则称之为 redis 数据淘汰策略。

通过 redis.conf 来配置 redis的数据淘汰策略。
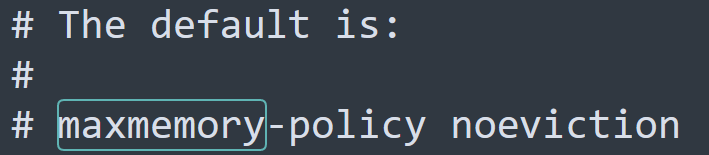
redis 支持8中数据淘汰策略
- noeviction(默认策略):不淘汰任何key,在内存满时不允许写入新的数据。
- volatile-ttl:对于设置了过期时间的key,比较key剩余的TTL值,TTL越小先被淘汰。
- allkeys-random:所有key,随机淘汰。
- volatile-random:所有设置了过期时间的key,随机淘汰。
- allkeys-lfu:所有key,根据使用频率淘汰。
- allkeys-lru:所有key,根据最近使用时间间隔淘汰。
- volatile-lfu:设置了TTL的key,根据使用频率淘汰。
- volatile-lru:设置了TTL的key,根据最近使用时间间隔淘汰。
LRU(Least Recently Used):最近最少使用。使用当前时间减去最后一次访问时间,值越大,越优先被淘汰。
LFU(Least Frequently Used):最少频率使用。统计每个key的访问频率,值越小,越优先被淘汰。
使用建议
- 优先使用 allkeys-lru,充分利用lru算法的优势。
- 若业务中数据访问频率差距不大,测试用 allkeys-random。
- 若业务中有置顶需求,则使用volatile-lru,同时置顶数据不设置过期时间。
问:数据库中有1000w条数据,redis中只能缓存20w条。如何保证 redis 中都是热点数据?
答:使用 allkeys-lru 淘汰策略,留下来的都是最近的热点数据。
问:redis内存用完会发生什么?
答:主要看redis的数据淘汰策略是什么。如果是默认配置noeviction,则会直接报错。
Redis 实现分布式锁
问:为什么要用到分布式锁?
答:
在分布式系统中,多个进程,需要同时操作一个共享资源,如何互斥呢?此时就必须借助一个外部系统,所有进程都去这个系统上申请加锁。而这个外部系统,必须要实现互斥能力。这个外部系统可以是数据库,也可以是Redis或Zookeeper。而 Redis 的读写性能高,可以应对高并发的锁操作场景,所以一般选用 redis 作为分布式锁。
Redis 实现分布式锁需要用到 redis 的 setnx 命令。setnx 命令是 set if not exists 的缩写,意为如果不存在则set,否则什么也不做。多个客户端进程可以执行这个命令来获取锁或设置锁,从而达到互斥的效果。
加锁用 setnx 命令,释放锁用到 del 命令,将锁的key值删除即可。
但是,以上实现存在一个很大的问题,当客户端1拿到锁后,如果发生下面的场景,就会造成死锁。
- 程序处理业务逻辑异常,没及时释放锁
- 进程挂了,没机会释放锁
以上情况会导致已经获得锁的客户端一直占用锁,其他客户端永远无法获取到锁。
为了解决以上死锁问题,最容易想到的方案是在申请锁时,在Redis中实现时,给锁设置一个过期时间,假设操作共享资源的时间不会超过10s,那么加锁时,给这个key设置10s过期即可。
但以上操作还是有问题,加锁、设置过期时间是2条命令,有可能只执行了第一条,第二条却执行失败。导致没有设置过期时间,还会产生死锁问题。
例如:
- SETNX执行成功,执行EXPIRE时由于网络问题,执行失败
- SETNX执行成功,Redis异常宕机,EXPIRE没有机会执行
- SETNX执行成功,客户端异常崩溃,EXPIRE没有机会执行
总之这两条命令如果不能保证是原子操作,就有潜在的风险导致过期时间设置失败,依旧有可能发生死锁问题。
在Redis 2.6.12之后,Redis扩展了SET命令的参数,可以在SET的同时指定EXPIRE时间,这条操作是原子的。
SET lock_key value NX EX 10 ex 是过期时间
至此,解决了死锁问题,但还是有其他问题。例如:锁过期和释放其他进程的锁。
锁过期是评估操作共享资源的时间不准确导致的,如果只是一味增大过期时间,只能缓解问题降低出现问题的概率,依旧无法彻底解决问题。原因在于客户端在拿到锁之后,在操作共享资源时,遇到的场景是很复杂的,既然是预估的时间,也只能是大致的计算,不可能覆盖所有导致耗时变长的场景。
释放其他进程的锁是在释放锁的操作是无脑操作,并没有检查这把锁的归属,这样解锁不严谨。
问:如何控制锁的有效时长呢?如果控制解的是当前进程的锁呢?
答:通过 redisson 来实现。
Redisson
执行流程

redisson底层实现的分布式锁底层是通过 setnx 和 lua 脚本实现的。lua脚本可以保证redis命令的原子性。
问:redisson 实现分布式锁如何合理控制锁的有效时长?
答:在redisson中,提供了一个 watchDog,一个线程获取锁成功后,watchDog 会给持有锁的线程续期。(默认为每十秒一次)
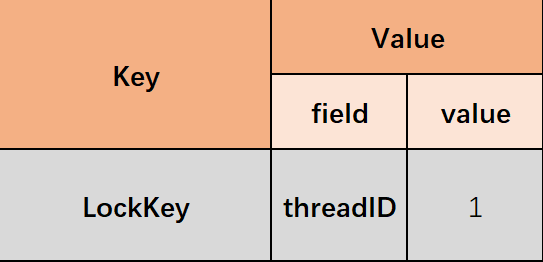
问:redisson分布式锁,可重入吗?
答:可以重入。多个锁重入时会根据线程id判断是否是当前线程。若是,则在redis中以hash形式的数据结构存储线程信息和重入次数。
问:redisson能解决主从数据一致性问题吗?
答:不能解决,但是可以使用红锁来解决。但是性能低下,维护成本高,一般不建议使用。若需要保证数据强一致性问题,可以使用 zookeeper 来实现分布式锁。
Redis 集群
问:redis为什么要搭建集群?
答:单点redis的并发能力是有上限的,要进一步提高redis的并发能力,就需要搭建redis集群,实现读写分离。一般是一主多从,主节点负责写操作,从节点负责读操作。
问:redis集群方案有哪些?
答:主要有三种,主从复制、哨兵模式、分片集群。
主从复制
问:主从同步数据的流程是怎样的?
答:
全量同步:
- 从节点请求主节点同步数据,发送 replication id 和 offset 偏移量。
- 主节点判断是否是第一次请求,是第一次就与从节点同步版本信息。
- 主节点执行bgsave命令,生存rdb文件后,发送给从节点执行。
- 在rdb生成和执行期间,主节点会以命令的方式将新增数据记录到缓冲区(一个日志文件)。
- 在从节点执行rdb同步后,主节点再把新增数据的执行命令的日志文件同步给从节点同步。
增量同步:
- 从节点请求主节点同步数据,主节点根据replid判断是否是第一次请求,不是第一次请求就获取从节点的offset值。
- 主节点从命令日志文件中获取offset值之后的数据,发送给从节点进行数据同步。
主从全量同步原理

出从增量同步原理(slave重启后数据变化)

哨兵模式
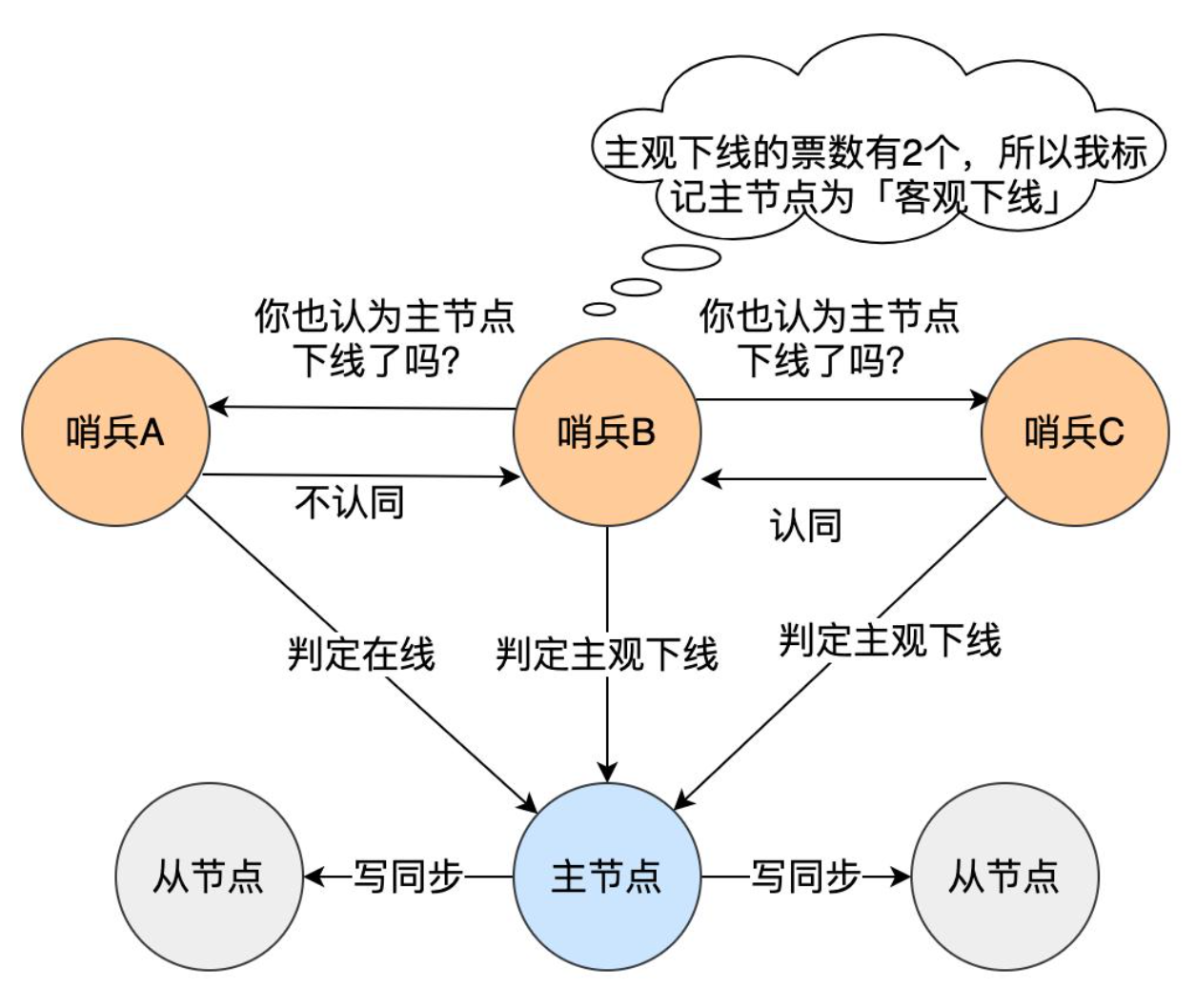
Redis提供了哨兵模式(sentinel)来实现主从集群的自动故障修复。哨兵的作用如下。
- 监控:哨兵不断检查和监控 redis 主从集群状态
- 自动故障修复:如果master故障,哨兵会将一个slave提升为master,当故障恢复后,也会以新的master为主
- 通知:当redis集群发生故障时,哨兵会将最新的主节点信息推送给redis客户端。
哨兵的选主规则:
- 首先判断主节点与从节点断开时间长短,超过一定时间,此从节点就不会被选举
- 然后判断从节点的 slave-priority (配置文件配置)值,值越小,优先级越高
- 当 slave-priority 值一致时,则判断从节点的 offset 值,值越大,优先级越高
- 最后判断slave节点的运行id大小,值越小,优先级越高
问:怎么保证 redis 的高可用性?
答:使用redis的哨兵模式,实现主从集群的自动故障修复。
问:你们使用的 redis 集群是什么模式?
答:我们项目中使用的 redis 集群是 1主+1从+哨兵的模式。
问:redis 集群脑裂,怎么解决?
答: 集群脑裂是由于redis主节点和从节点不处于同一个网络环境。当主节点网络波动时,使得哨兵没能获取到主节点心跳,所以就会选举一个从节点当做主节点。此时就会有两个主节点,客户端还在写入数据到旧的主节点,而新的主节点无法同步数据。当网络恢复后,旧的主节点就会降级为从节点,此时从节点会向新的主节点发送同步数据命令,这样就会导致网络波动时产生的数据丢失。
解决方法:可以修改 redis 的配置文件,设置最少从节点数量以及缩短主从数据同步延迟的时间。
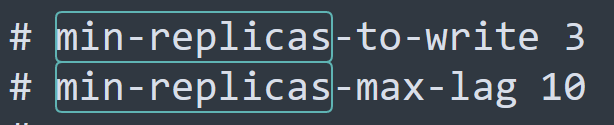
min-replicas-to-write 1:表示最少的salve节点为1个
min-replicas-max-lag 5:表示数据复制和同步的延迟不能超过5秒
分片集群
主从复制和哨兵模式可以解决redis的高可用和高并发读的问题。但依旧有两个问题尚未解决。
- 海量数据存储问题。
- 高并发写问题。
使用分片集群就可以完美解决以上问题,分片集群特征如下。
- 集群中有多个master,每个master用来保存不同的数据。
- 每个master都有多个slave节点。
- master之间通过ping检测彼此的状态。
- 客户端请求到任意节点,最终都会被转发到正确的节点上。
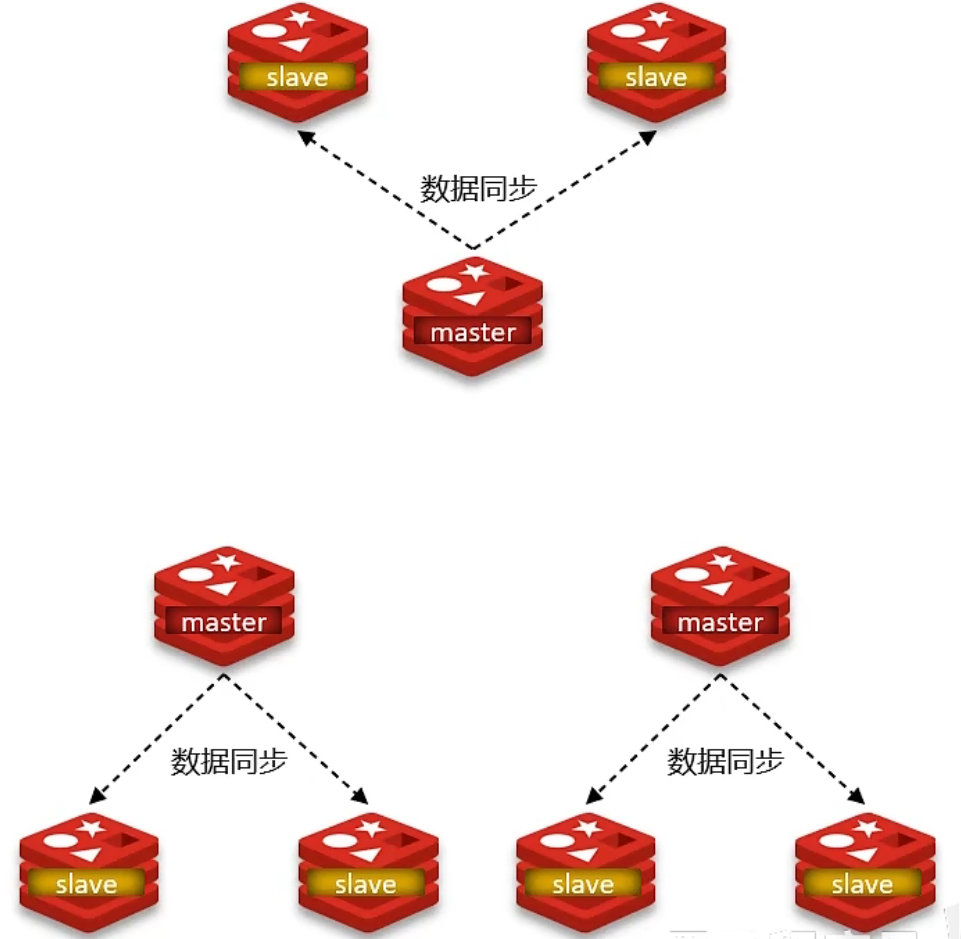
问:redis的分片集群有什么用?
答:集群中有多个master,每个master保存不同的数据,并且每个master都有多个slave节点来实现高可用。master之间会通过ping来检测彼此的状态,客户端可以请求任意的master,最终都会被转发到正确的master节点。
问:redis分片集群时如何存储和读取数据的?
答:redis分片集群引入了哈希槽的概念,redis集群有16384个哈希槽,将16384个哈希槽分配给不同的实例。读写数据时,根据key的有效部分计算哈希值,对16384取余,余数作为插槽,寻找插槽所在的实例存取。
mages.oss-cn-hangzhou.aliyuncs.com/blogImg-master/noteImg/202304201515123.png" style=“zoom:50%;” />
问:redis的分片集群有什么用?
答:集群中有多个master,每个master保存不同的数据,并且每个master都有多个slave节点来实现高可用。master之间会通过ping来检测彼此的状态,客户端可以请求任意的master,最终都会被转发到正确的master节点。
问:redis分片集群时如何存储和读取数据的?
答:redis分片集群引入了哈希槽的概念,redis集群有16384个哈希槽,将16384个哈希槽分配给不同的实例。读写数据时,根据key的有效部分计算哈希值,对16384取余,余数作为插槽,寻找插槽所在的实例存取。

















 615
615

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









