



 本文深入探讨了JavaScript中0.1+0.2为何不等于0.3的奥秘,揭示了IEEE-754二进制浮点数表示法导致的舍入误差现象,同时提供了猴子吃桃问题的Java实现。
本文深入探讨了JavaScript中0.1+0.2为何不等于0.3的奥秘,揭示了IEEE-754二进制浮点数表示法导致的舍入误差现象,同时提供了猴子吃桃问题的Java实现。
JavaScript 问答题
解释一下下面代码的输出。
console.log(0.1 + 0.2); //0.30000000000000004
console.log(0.1 + 0.2 == 0.3); //false
JavaScript 中的 number 类型就是浮点型,JavaScript 中的浮点数采用IEEE-754 格式的规定,这是一种二进制表示法,可以精确地表示分数,比如 1/2,1/8,1/1024,每个浮点数占 64 位。但是,二进制浮点数表示法并不能精确的表示类似 0.1 这样 的简单的数字,会有舍入误差。 由于采用二进制,JavaScript 也不能有限表示 1/10、1/2 等这样的分数。在二进制中,1/10(0.1)被表示为 0.00110011001100110011…… 注意 0011 是无限重复的,这是舍入误差造成的,所以对于 0.1 + 0.2 这样的运算,操作数会先被转成二进制,然后再计算:
0.1 => 0.0001 1001 1001 1001…(无限循环)
0.2 => 0.0011 0011 0011 0011…(无限循环)
双精度浮点数的小数部分最多支持 52 位,所以两者相加之后得到这么一串
0.0100110011001100110011001100110011001100… 因浮点数小数位的限制而截断的二进制数字,这时候,再把它转换为十进制,就成了 0.30000000000000004。
MySQL 编程题
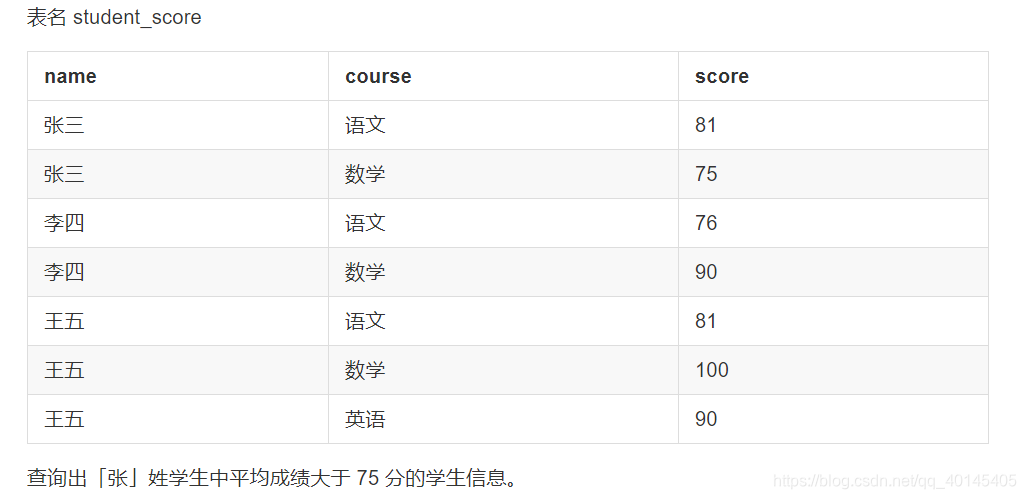
SELECT *
FROM student_score
WHERE name IN (SELECT name
FROM student_score
WHERE name LIKE '张%'
GROUP BY name
HAVING AVG(score) > 75)
Java 编程题
猴子吃桃问题:猴子第一天摘下若干个桃子,当即吃了一半,还不瘾,又多吃了一个 第二天早上又将剩下的桃子吃掉一半,又多吃了一个。以后每天早上都吃了前一天剩下的一半零一个。到第 10 天早上想再吃时,见只剩下一个桃子了。求第一天共摘了多少。
package test;
public class Test{
public static void main(String[] args) {
int num = 1;
for (int i = 10; i >1; i--) {
num = (num + 1) * 2;
}
System.out.println("第一天共摘了" + num + "个桃子");
}
}

















 1112
1112

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









