






 本文包含三道编程题目解答:使用JavaScript统计字符串中出现频率最高的字符;通过Java代码找出101到200之间的所有素数;利用MySQL删除重复团队记录,保留每个团队的最小ID。这些题目覆盖了基本的数据结构操作、算法实现及数据库管理技巧。
本文包含三道编程题目解答:使用JavaScript统计字符串中出现频率最高的字符;通过Java代码找出101到200之间的所有素数;利用MySQL删除重复团队记录,保留每个团队的最小ID。这些题目覆盖了基本的数据结构操作、算法实现及数据库管理技巧。
JavaScript 编程题
查找「sdddrtkjsfkkkasjdddj」字符串中,出现次数最多的字符和次数。
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title></title>
</head>
<body>
</body>
<script>
var str = "sdddrtkjsfkkkasjdddj";
// 使用对象记录字符出现的次数,键为各个字符,值为字符出现的次数
var obj = {};
for(var i = 0; i < str.length; i++) {
//获得字符
var char = str.charAt(i);
//若对象已有该字符属性,值加1
if(obj[char]) {
obj[char]++;
} else {
//第一次出现该字符,值记为1
obj[char] = 1;
}
}
//记录出现最多次数
var max = 0;
for(var key in obj) {
if(obj[key] >= max) {
max = obj[key];
}
}
//打印
for(var key in obj) {
if(obj[key] == max) {
console.log("出现次数最多的字符:" + key);
console.log("出现次数:" + obj[key]);
}
}
</script>
</html>
MySQL 编程题
表名 team
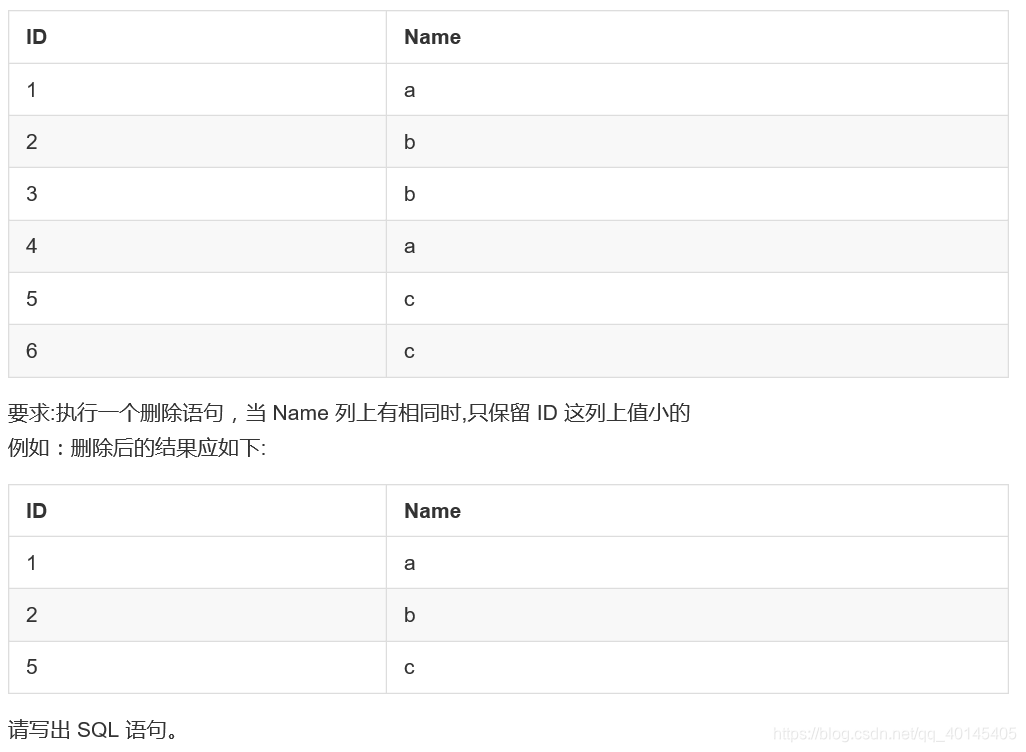
delete from team where id not in (selete a.id from (selete min(id) as id from team group by name) a)
Java 编程题
判断 101-200 之间有多少个素数,并输出所有素数。
package com.nt.test;
public class test1 {
public static void main(String[] args) {
int count=0;
for(int i=101;i<200;i++)
{
int j;
for(j=2;j<i;j++)
{
if(i%j==0)
break;
}
if(j==i)
{
count++;
System.out.print(i + "\t");
if (count % 5 == 0) {
System.out.print("\n");
}
}
}
}
}

















 188
188

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









