









前言:
非平衡分类技术也称非均衡分类技术,通常是指各个类别的样例数量差别很大,某些类别对应的样例过多,而某些类别对应的样例过少;使用这种类型的数据集来训练诸如神经网络之类的模型,通常会导致属于多数类的数据的高精度,但是对于少数类数据的精度是不可接受的。发生这种情况通常是因为模型最终只专注于样本量最大的类,因为样本较少的类在调整权重时出现的次数较少。
方法:
-
随机过采样:
这种方法比较直接,通过增加少数类样本来提高少数类的分类性能,最简单的办法是随机复制少数类样本。
-
SMOTE:
SMOTE全称为信息性过采样,利用KNN技术,对于少数类样本a,在特征空间中随机选择一个最近邻的样本b,然后从a与b的连线上随机选取一个点c作为新的少数类样本。SMOTE有时能提升分类准确率,有时不能,甚至可能因为构建数据时放大了噪声数据导致分类结果变差,这要视具体情况而定。
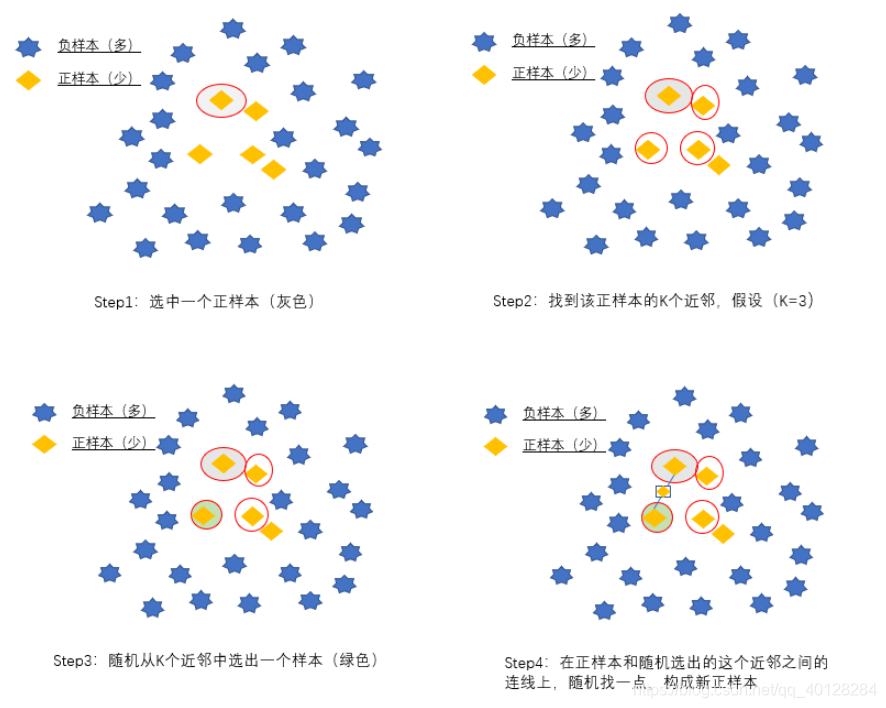
-
ADASYN
ADASYN全称为自适应综合过采样,我的理解就是它是一种插值法,在少数类样本之间进行插值。但是这种算法可能会在多数类样本中间插值出一个少数类样本导致类别重叠。
(1)计算不平衡度
记少数类样本为
,多数类为
,则不平衡度为
,则
。
(2)计算需要合成的样本数量
,
,当b = 1时,即G等于少数类和多数类的差值,此时合成数据后的多数类个数和少数类数据正好平衡。
(3)对每个属于少数类的样本用欧式距离计算k个邻居,
为k个邻居中属于多数类的样本数目,记比例
为
,r∈[0,1]。
(4)在(3)中得到每一个少数类样本的
, 用
计算每个少数类样本的周围多数类的情况。
(5)对每个少数类样本计算合成样本的数目
。
(6)在每个待合成的少数类样本周围k个邻居中选择1个少数类样本,根据下列等式进行合成
。
-
对抗性过采样
这种方法主要采用生成对抗网络技术对少数类样本进行生成,从而获取平衡数据集。
最近在做非平衡分类方法的工作,后面会继续整理相关技术,以做到查缺补漏。
评价指标:
精确度是常规分类问题中常用的评价标准,它反映分类器对数据集的整体分类性能。对于类与类间分布平衡的分类问题,精确度指标一般可以较好地对分类器的分类性能进行评价。但是,精确度指标一般不能较好地反映非平衡数据集的分类性能。针对非平衡数据,通常采用更为合理的评价标准,常用的评价标准有:F-measure值、G-mean值和AUC值等。
-
F-measure:
召回率和准确率有时候会出现矛盾的情况,这样就需要综合考虑二者。最常见的方法是F-measure,它是召回率和精度的加权调和平均值,F-measure 值较高时,说明模型性能较好。
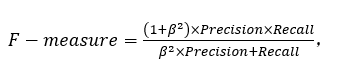
-
G-mean:
也是一种综合考虑召回率和准确率的标准,G-mean值较高时。说明模性性能较好。

AUC:
ROC曲线下方的面积,ROC曲线的横坐标为伪正类率FPR,纵坐标为真正类率TPR,通过调整分类器的正类概率阈值得到多组FPR和TPR元组,画出ROC曲线,从而求得AUC值。
- 0.5-0.7:效果较低。
- 0.7-0.85:效果一般。
- 0.85-0.95:效果很好。
- 0.95-1:效果非常好。

















 555
555

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









