







前言:
最近研究了一下某饿了app的商铺评论的抓取,该app使用了ssl-pinning的技术来防止中间人攻击,中间代理抓包的时候,出现了unknown,你的代理工具的协议不支持,你可以手写协议或者使用下文中提到的方法。
1.目标
- 环境的准备:雷电模拟器,要抓取的app,可登录的账号,Charles
抓取某饿了app店铺的评论数据,
2.抓包寻找接口
- 设置好Charles的环境,配置证书信任后,由于Charles证书并非证书机构颁发的目标站点的合法证书,手机上的抓包神器,PacketCapture也存在这个问题
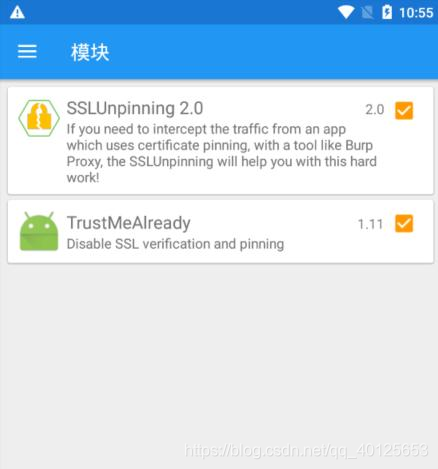
- 在抓取这个软件数据包的过程中,会发现接口出现unknown,就是证书不信任的问题校验不通过。怎么关闭这个校验,可以自己修改Charles的协议源码,我这边使用的方案是 Xposed+JustTrustMe
XposedInstaller
(xposed框架)是一款可以在不修改APK的情况下影响程序运行(修改系统)的框架服务,基于它可以制作出许多功能强大的模块,且在功能不冲突的情况下同时运作。
JustTrustMe是Github上的一个开源工程,他是一个Xposed模块,用来禁止SSL证书验证。以下是其简介。
JustTrustMe:
An xposed module that disables SSL certificate checking. This is useful for auditing an appplication which does certificate pinning.
可能某些软件使用了JustTrustMe 还是不行,可以再试下 SSLUnpinning 这个Xposed模块。
SSLUnpinning:
通过 Xposed 框架进行 SSLUnning,在 SSL 类中创建多个挂钩,以绕过特定应用的证书验证,然后您可以截获所有流量。
- posed安装器下载地址: https://pan.baidu.com/s/1dEToAvJ 密码:uiu8
- JustTrustMe Relese版本下载地址:https://github.com/Fuzion24/JustTrustMe/releases
- sslunpinning 下载地址: https://repo.xposed.info/module/mobi.acpm.sslunpinning
3.打开软件,进行抓包分析
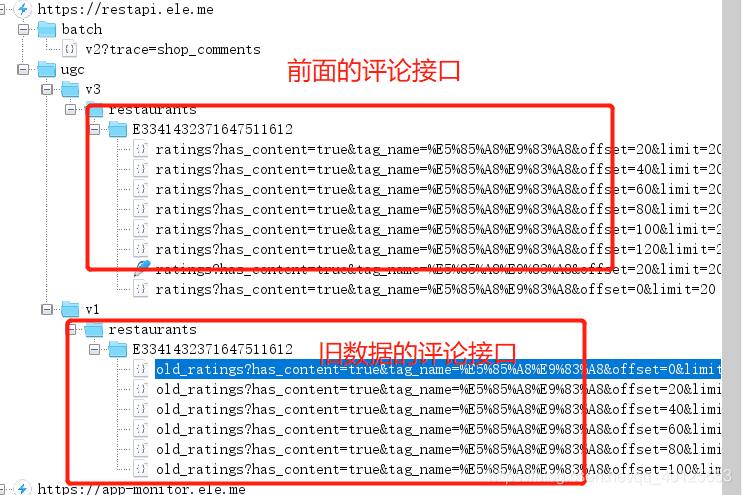
- 使用抓包工具分析,发现评论是由两部分数据接口组成的,
- 接口1,返回的是新数据
https://restapi.ele.me/ugc/v3/restaurants/{eid}/ratings?has_content=true&tag_name=全部&offset={}&limit=20
# 参数的含义
eid 商铺的标识
has_content 有内容的评论
tag_name 评论的类型
offset翻页的参数
limit 每页的数量
- 接口2 返回的是旧数据接口
https://restapi.ele.me/ugc/v1/restaurants/E3341432371647511612/old_ratings?has_content=true&tag_name=%E5%85%A8%E9%83%A8&offset={}&limit=20&from_time={}
# 参数的含义
from_time 翻页的参数,接口上一页返回的值
offset 翻页参数
from_time 翻页携带的参数 上一个页面返回的值
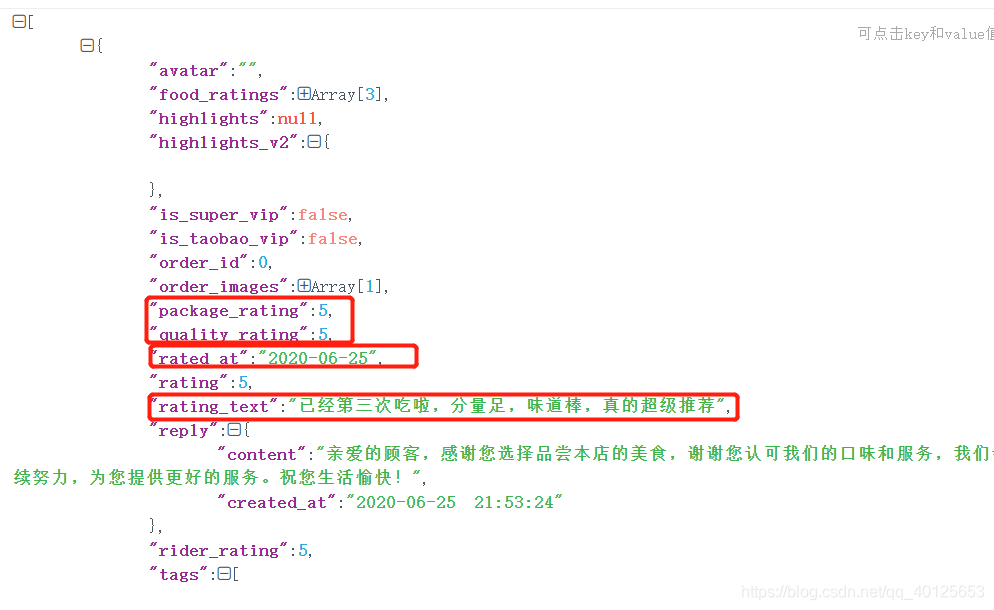
返回的数据
源码:
# 旧的评分
def get_old_page(page_size, from_time, headers1):
time.sleep(2)
print("++++++++++开始老数据第{}页".format(page_size))
old_url = "https://restapi.ele.me/ugc/v1/restaurants/E3341432371647511612/old_ratings?has_content=true&tag_name=%E5%85%A8%E9%83%A8&offset={}&limit=20&from_time={}".format(page_size*20, from_time)
resp2 = requests.get(old_url, headers=headers1)
result2 = resp2.json()
# print(resp2.text)
for item in result2['ratings']:
text = item.get('rating_text')
pub_time = item.get('rated_at')
print(pub_time, text)
# return result2['from_time']
if result2["from_time"]:
# 翻页处理
get_old_page(page_size=page_size+1, from_time=result2["from_time"], headers1=headers1)
def run_spider(eid):
# E3341432371647511612
"""
:param eid: 店铺id
:return:
"""
headers1 = {
"cookie": "SID=xxxxxxxxxxxxxxxxxxxxxxxx",
"user-agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safari/537.36 MicroMessenger/7.0.4.501 NetType/WIFI MiniProgramEnv/Windows WindowsWechat",
"x-shard": "loc=116.4103439077735,39.91629492491484;shopid={}".format(eid),
}
start_page = 0
while True:
time.sleep(2)
print("----------新数据第{}页-----".format(start_page))
base_url = "https://restapi.ele.me/ugc/v3/restaurants/{}/ratings?has_content=true&tag_name=%E5%85%A8%E9%83%A8&offset={}&limit=20".format(eid, start_page*20)
resp = requests.get(base_url, headers=headers1)
# 解析数据
result = resp.json()
if not result:
break
start_page += 1
for item in result:
text = item['rating_text']
pub_time = item.get('rated_at')
print(pub_time, text)
# 老数据
get_old_page(0, '', headers1)
if __name__ == '__main__':
# 店铺ID是动态的每天会换一次
eid = "E537594264834876451"
run_spider(eid)
如果对采集方案感兴趣或者对数据抓取有兴趣的,可以加我qq: 330446875 学习交流(注明:优快云爬虫)

















 627
627

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









