




11. L 1 L1 L1和 L 2 L2 L2正则先验分别服从什么分布(第五题关联)
L
1
L1
L1服从拉普拉斯分布,
L
2
L2
L2服从高斯分布。
所谓先验就是优化的起跑线,有先验的好处就是可以在较小的数据集中有良好的泛化性能,当然这是在先验分布是接近真实分布的情况下得到的了,从信息论的角度看,向系统加入了正确先验这个信息,肯定会提高系统的性能。
通俗解释:
模型过于复杂是因为模型尝试去兼顾各个测试数据点, 导致模型函数如下图,处于一种动荡的状态, 每个点的到时在某些很小的区间里,函数值的变化很剧烈。这就意味着函数在某些小区间里的导数值(绝对值)非常大,由于自变量值可大可小,所以只有系数足够大,才能保证导数值很大。
而加入正则能抑制系数过大的问题。如下公式, 是岭回归的计算公式。
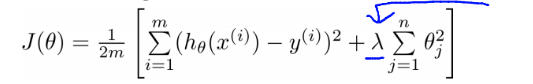
如果发生过拟合, 参数θ一般是比较大的值, 加入惩罚项后, 只要控制λ的大小,当λ很大时,θ1到θn就会很小,即达到了约束数量庞大的特征的目的。
对参数引入高斯正态先验分布相当于
L
2
L2
L2正则化:
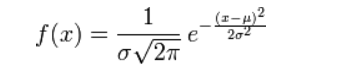
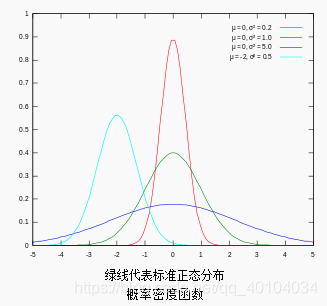
对参数引入拉普拉斯先验等价于
L
1
L1
L1正则化, 如下图:
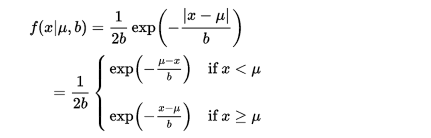
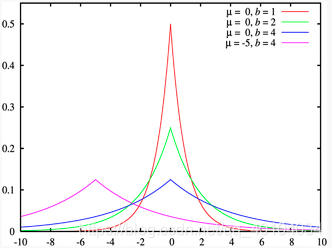
从上面两张图可以看出L2先验趋向零周围, L1先验趋向零本身。
详细解释:回归系列之L1和L2正则化。
(Lp范数:向量中各个元素绝对值的p次方和的开p次方根)
12. CNN最成功的应用是在CV,那为什么NLP和Speech的很多问题也可以用CNN解出来?为什么AlphaGo里也用了CNN?这几个不相关的问题的相似性在哪里?CNN通过什么手段抓住了这个共性?
- 以上几个不相关问题的相关性在于,都存在局部与整体的关系,由低层次的特征经过组合,组成高层次的特征,并且得到不同特征之间的空间相关性。如下图:低层次的直线/曲线等特征,组合成为不同的形状,最后得到汽车的表示。

- CNN抓住此共性的手段主要有四个:局部连接/权值共享/池化操作/多层次结构。
- 局部连接使网络可以提取数据的局部特征;权值共享大大降低了网络的训练难度,一个Filter只提取一个特征,在整个图片(或者语音/文本) 中进行卷积;池化操作与多层次结构一起,实现了数据的降维,将低层次的局部特征组合成为较高层次的特征,从而对整个图片进行表示。如下图:
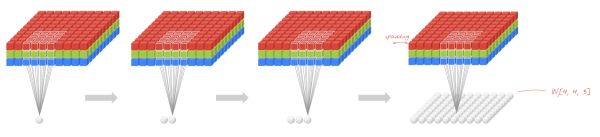
上图中,如果每一个点的处理使用相同的Filter,则为全卷积,如果使用不同的Filter,则为Local-Conv。
13.说一下Adaboost,权值更新公式。当弱分类器是Gm时,每个样本的的权重是w1,w2…,请写出最终的决策公式。
14.LSTM结构推导,为什么比RNN好?
循环神经网络(RNN)
背景了解:
RNN可以指代两种神经网络,Recursive Neural Network 以及 Recurrent Neural Network 前一种应该被称为递归神经网络,但是现在提到的主要都是指Recurrent Neural Network。
Recursive Neural Network是为了解决日常现象中一些递归结构的存在而特别设计的网络,比如在图像处理中一个表示车的图片中可以分为若干块小的零件图片,如窗户,轮子,但是这些代表窗户的图片也可能是飞机甚至是房子的一部分;比如在自然语言处理中出现的名词带的从句中又出现名词的情况。因此,Recursive Neural Network是一种对网络结构的重复,重复的网络权值构成一个树状结构,主要应用是图片分割与注释,在自然语言处理中也有应用。
而Recurrent Neural Network则更偏重于时序上的处理,因此是一个链式的连接。
具体介绍(Recurrent Neural Network):
CNN等传统神经网络的局限在于:将固定大小的向量作为输入(比如一张图片),然后输出一个固定大小的向量(比如不同分类的概率)。不仅如此,CNN还按照固定的计算步骤(比如模型中层的数量)来实现这样的输入输出。这样的神经网络没有持久性: 假设你希望对电影中每一帧的事件类型进行分类,传统的神经网络就没有办法使用电影中先前的事件推断后续的事件。
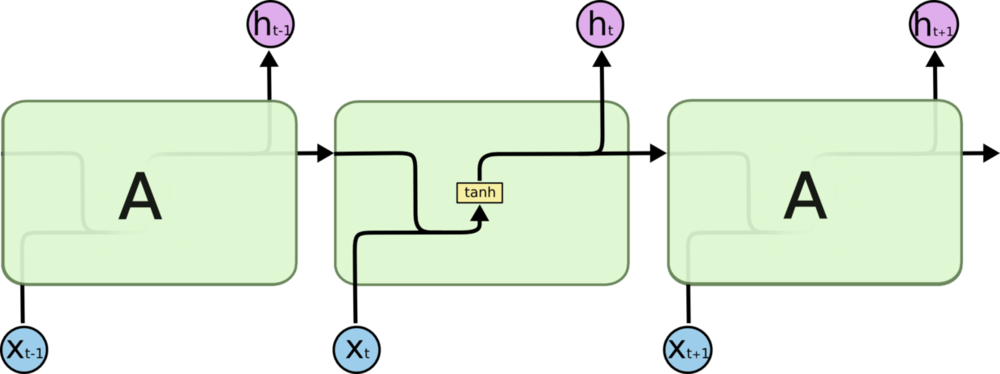
如果把RNN展开,可以看到RNN的结构和普通的网络相似,可以将其看作是若干个相同的网络相连,并将信息在网络中进行传递。由于这种信息传递的存在,RNN的就可以根据之前出现的信息对当前的信息进行推断,特别是在语言处中,RNN就可以用于根据上文预测下一个将要出现的词。
RNN允许信息的持久化,对当前的状态保留记忆(以隐变量的方式存在,也就是图中计算h{t}需要用到h{t-1}的信息)。对于同一个RNN来说,其“A结构”(绿色部分)是固定的(共享一套参数,毕竟是从循环展开来的啊肯定是一样的)。
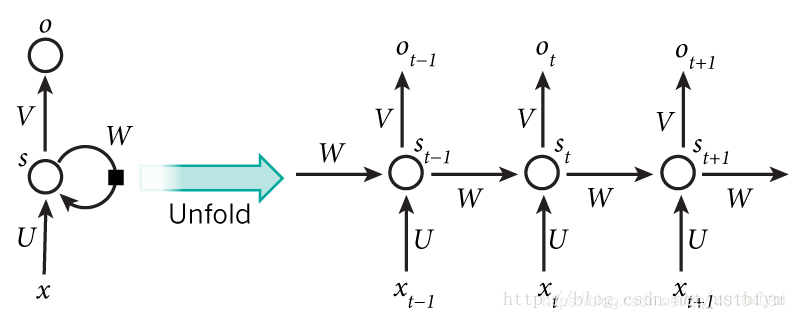
上图所示的是最基本的循环神经网络,但是这个图是抽象派的,只画了一个圈不代表只有一个隐层。如果把循环去掉,每一个都是一个全连接神经网络。x是一个向量,它表示输入层,s也是一个向量,它表示隐藏层,这里需要注意,一层是有多个节点,节点数与s的维度相同。U是输入层到隐藏层的权重矩阵,与全连接网络的权重矩阵相同,o也是一个向量,它表示输出层,V是隐藏层到输出层的权重矩阵。
公式推导:

LSTM(Long-Short Term Memory)
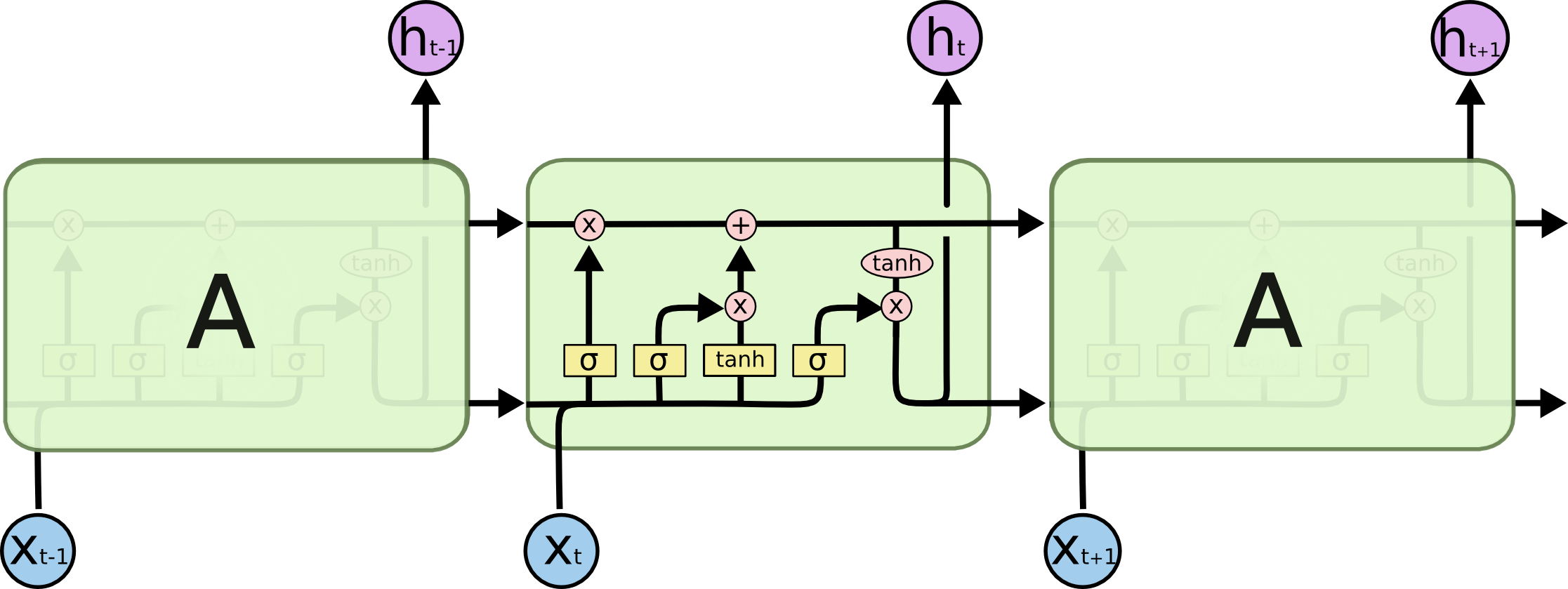 公式推导链接1
公式推导链接1
公式推导链接2
因为LSTM有进有出且当前的cell informaton是通过input gate控制之后叠加的,RNN是叠乘,因此LSTM可以防止梯度消失或者爆炸。
15.Google是怎么利用贝叶斯方法,实现"拼写检查"的功能
用户输入一个单词时,可能拼写正确,也可能拼写错误。如果把拼写正确的情况记做c(代表correct),拼写错误的情况记做w(代表wrong),那么"拼写检查"要做的事情就是:在发生w的情况下,试图推断出c。换言之:已知w,然后在若干个备选方案中,找出可能性最大的那个c,也就是求
P
(
c
∣
w
)
P(c|w)
P(c∣w)的最大值。
根据贝叶斯定理,有:
P
(
c
∣
w
)
=
P
(
w
∣
c
)
∗
P
(
c
)
/
P
(
w
)
P(c|w) = P(w|c)*P(c)/P(w)
P(c∣w)=P(w∣c)∗P(c)/P(w)
由于对于所有备选的c来说,对应的都是同一个w,所以它们的P(w)是相同的,因此我们只要最大化:
P
(
w
∣
c
)
∗
P
(
c
)
P(w|c)*P(c)
P(w∣c)∗P(c)
 具体细节:How to Write a Spelling Corrector
具体细节:How to Write a Spelling Corrector

















 638
638

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









