






 本文提出一种基于注意力机制的图像修复方法,通过并行执行多种操作并由注意力机制加权,实现对多重因素混合失真的图像恢复。网络由特征提取、操作注意力层及输出层构成,实验表明该方法性能优越。
本文提出一种基于注意力机制的图像修复方法,通过并行执行多种操作并由注意力机制加权,实现对多重因素混合失真的图像恢复。网络由特征提取、操作注意力层及输出层构成,实验表明该方法性能优越。
[论文笔记] Attention-based Adaptive Selection of Operations for Image Restoration
一,大纲
以往的研究多是研究在某一因素的作用下导致的图片失真,然后提出了解决它们的方法。然而,在现实世界中,图像质量下降是在多种因素的共同作用下。
为了能够解决多重因素随机比例混合导致的图像失真,作者提出了一种简单而有效的神经网络层结构。它并行执行多个操作,这些操作由一个注意机制加权,以便根据输入选择合适的操作。该层可以叠加形成一个深度网络,该层是可微的,因此,整个网络架构可以通过梯度下降进行端到端方式训练。
二,网络架构
作者提出的网络由三个部分组成:特征提取块,operation-wise attention 层的堆叠块 和 输出层。
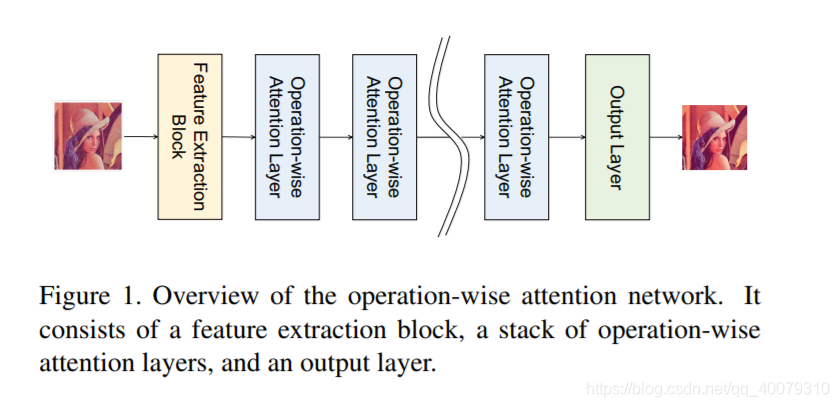
Operation-wise Attention Layer
operation-wise attention 层由操作层和注意层组成。
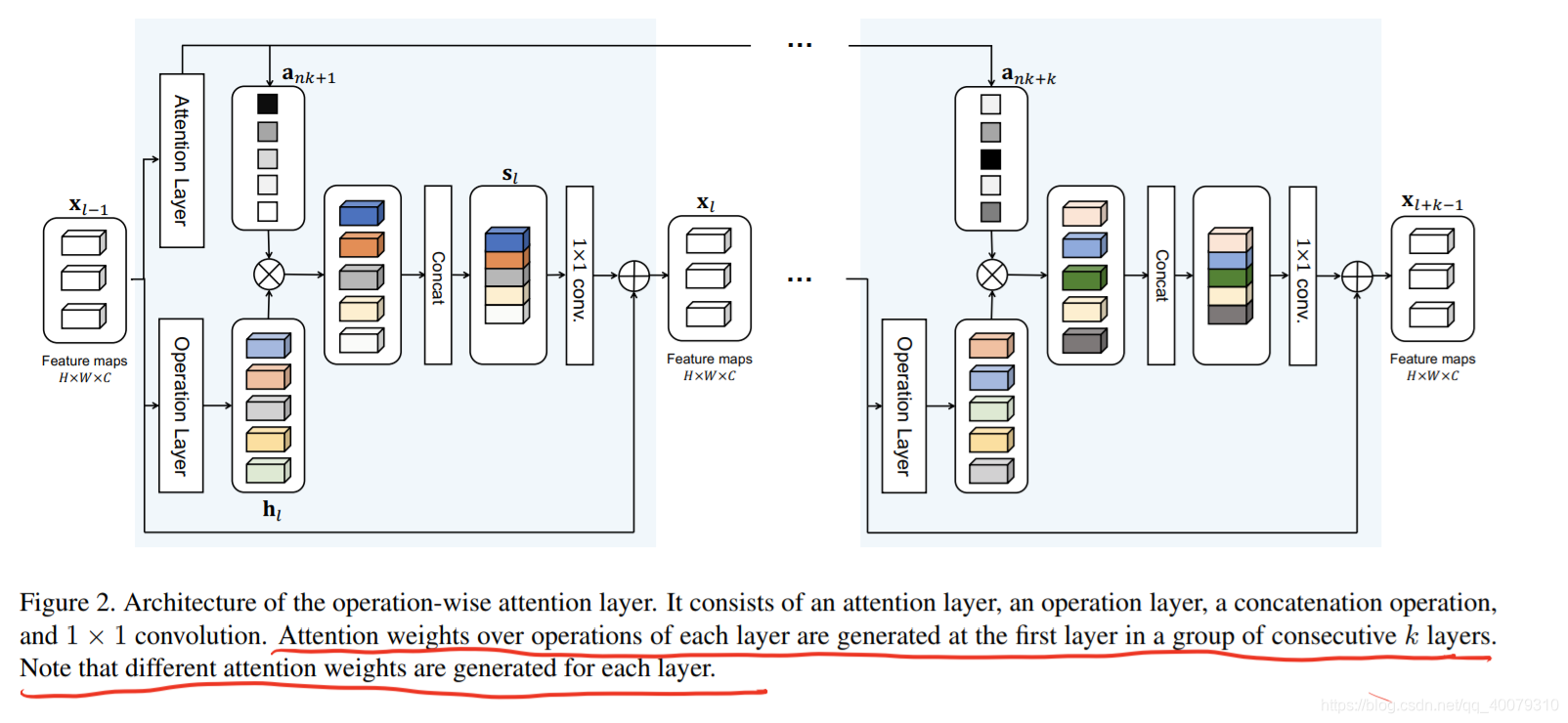
Operation-wise注意权重生成

此外,作者在初步实验中发现,在每隔几层的第一层生成注意权重比在每一层生成和使用注意权重更稳定。(这里所说的层,指的是operation-wise attention layer )具体来说,我们计算了在每一组的第一层计算出了后面连续k层中使用的注意权重。(论文中,k = 4)即group attention
然后,将不同操作生成的feature map进行加权,concat
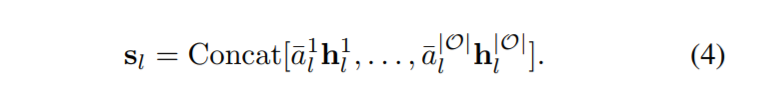
最后,concat后的feature map进行一次1x1的卷积降低维数,再来个残差连接~
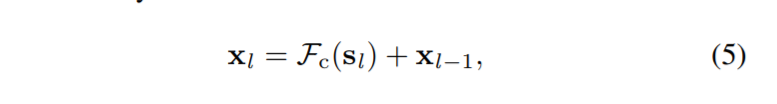
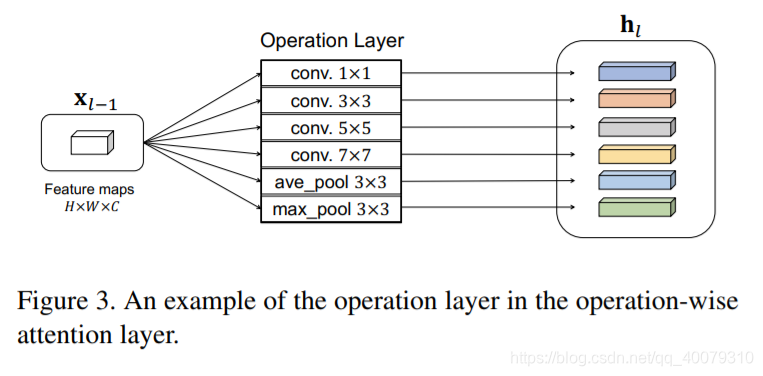
Operation Layer
作者为操作层选择8个常用操作:
separable convolutions : 1 x 1, 3 x 3, 5 x 5, 7 x 7
dilated separable convolutions : 3 x 3, 5 x 5, 7 x 7 (dilation rate = 2)
average pooling with a 3 ⇥ 3 receptive field
所以卷积操作(C = 16filters,stride = 1,followed by a Relu)
此外,为了不改变其输入和输出的大小,会对输入进行零填充后在计算映射。
Feature Extraction Block and Output Layer
Feature Extraction Block
k 个标准残差块叠加(论文中 k = 4)。其中,每个残差块中有两个卷积层(16个过滤器,且size 3x3 后面有ReLU激活函数)
Output Layer
论文中使用一个卷积层(内核大小3 x 3.#filters 取决于 最后图片的输出格式 灰度就是一个filter,RGB就是3个)
三,Experimental configuration
作者提出的网络中,共有40个operation-wise attention layers。
我们将权值矩阵W1、W2在每一层的维数设为T = 32,并在所有卷积层中使用16个卷积滤波器。
采用**L1**损失
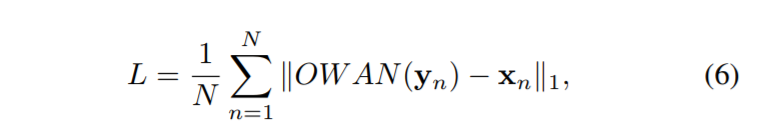
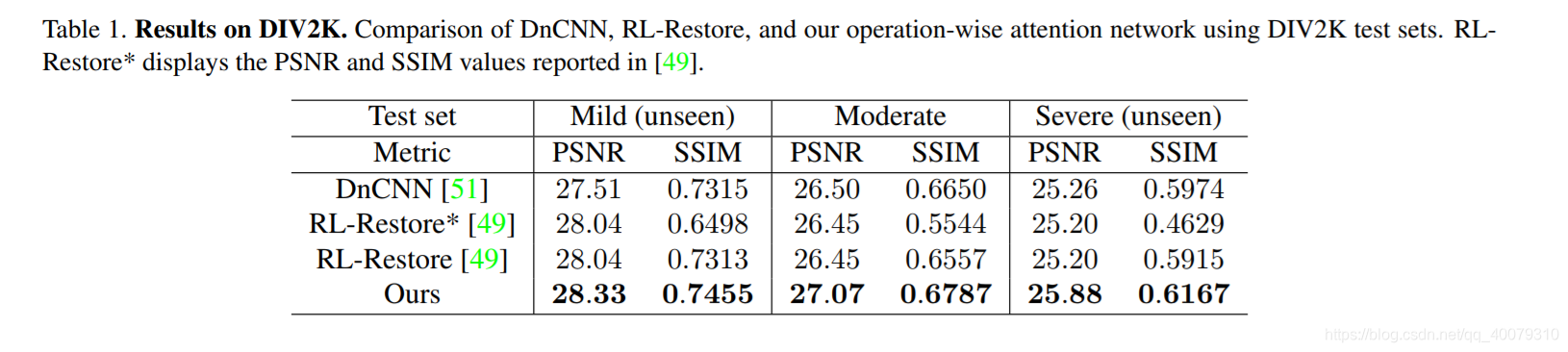
四,实验结果


五,结论
在本文中,作者提出了一个简单的网络结构,称为operation-wise attention mechanism,用于恢复具有混合比例和强度未知的失真的图像。它支持根据输入信号在一个层中执行多个操作。作者提出了一个具有这种注意机制的层,它可以堆叠起来构建一个深度网络。该网络是可微的,可以用梯度下降法进行端到端训练。实验结果表明,该方法比原方法具有更好的性能

















 625
625

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









