







k-mean就是按照某个特定的标准将数据集划分成不同的多个类或簇,使得同一个类内部的相似度尽可能的大,同时不在同一个类内的数据的差异性也尽可能的大,该方法是一种无监督学习算法。
k-mean算法原理:该算法是一种迭代算法,是将规模为n的数据集基于数据间的相似度及距离类内中心点距离划分成k类。算法流程主要包括两方面(1)初始化聚类中心,或输入数据范围内随机选择,或使用一些现有的训练样本(推荐);(2)将每个数据点分配到最近的聚类,点与聚类中心之间的距离用欧几里得计算;(3)通过将聚类中心的当前估计值设为属于该聚类的所有实例的平均值,用来更新它们的当前估计值。
k值的确定:采用最小簇内节点平方偏差之和算法(Within Cluster Sum of Squares,WCSS)进行确定。目的:得到一个k值,使得进行k-mean后计算得到的每个样本到簇内中心点的距离偏差之和最小,具体步骤如下:
- 选择不同的k值(如1-15),对数据样本执行k-means算法;
- 对每个k值,计算相应的WCSS值;
- 画出WCSS值随着k值变化的曲线;
- 一般来讲WCSS值应该随着k值的增加而减小,然后趋于平稳,选择当WCSS值开始趋于平稳时k的取值,图1中的WCSS曲线可以选择3-5之间的值作为k值。
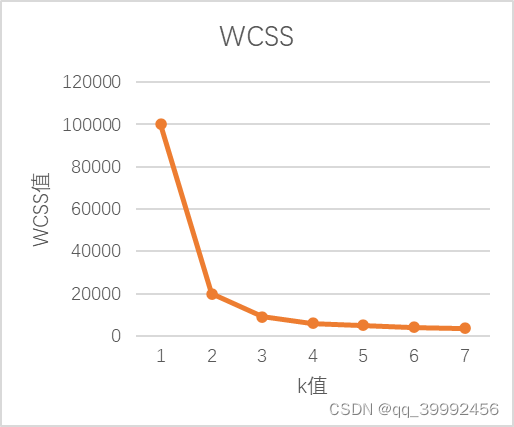
图1 WCSS变化趋势
算法流程:
流程注释:其一是确定k值。可以根据(1)WCSS方法;(2)经验值;(3)交叉验证;其二是选择k个初始化质心。
具体流程:输入样本集 ,聚类的簇为k
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









